(一)生产者消费者模式原理:
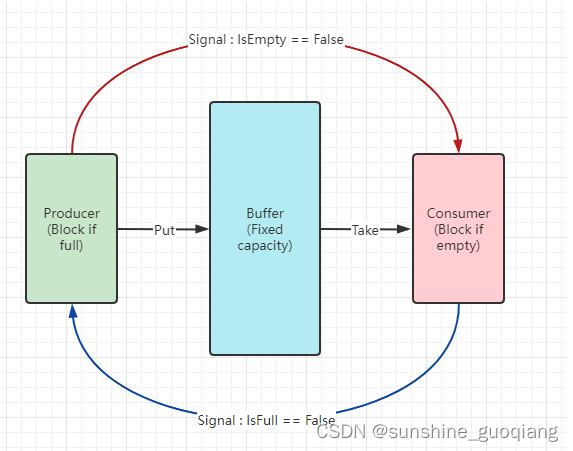
在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品。生产消费者模式如下图:

(二)代码实现
生产者是一堆线程,消费者是另一堆线程,内存缓冲区可以使用List数组队列,数据类型只需要定义一个简单的类就好。最关键就是内存缓冲区为空的时候消费者必须等待,而内存缓冲区满的时候,生产者必须等待。其他时候可以是个动态平衡:

首先设置Market类:
其中变量有:Max(仓库最大值),List(用于存放数据)
方法有Producer(生产方法),Cost(消费方法)
public class Market{private int Max=20;private List<String>list=new ArrayList<String>();public synchronized void producer()throws InterruptedException{ //设置锁if(list.size()>=20){this.wait(): //超过容量时,等待}System.out.println("***开始生产,现在数量为"+list.size()); list.add("a");System.out.println("***生产后数量为"+list.size());this.notify(); //唤醒线程}public synchronized void cost()throws InterruptedException{if(list.size()<0){this.wait(); //线程休眠}System.out.println("开始消费,现在数量为:"+list.size());list.remove(0);System.out.println("消费后数量为:"+list.size());this.notify(); //唤醒线程}
}
其次分别时Producer和Cost类,都要继承Thread类,重写run方法
public class Producer extends Thread{ //继承run方法private Market market;public Producer(Market market){this.market=market;}public void run(){while(true) {try {Thread.sleep(new Random().nextInt(500)); //设置时间延迟} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {market.production(); //调用生产方法} catch (InterruptedException e) { // TODO Auto-generated catch blocke.printStackTrace();}}}public class Cost extends Thread{ //继承run方法private Market market;public Cost(Market market){this.market=market;}public void run(){while(true) {try {Thread.sleep(new Random().nextInt(500)); //设置时间延迟} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {market.cost(); //调用消费方法} catch (InterruptedException e) { // TODO Auto-generated catch blocke.printStackTrace();}}}最后写出测试类,启动线程
public class Test{public static void main(String[]args){Market market=new Market();Producer p1=new Producer(market);Producer p2=new Producer(market);Producer p3=new Producer(market);Cost c1=new Cost(market);Cost c2=new Cost(market);p1.start(); //启动线程p2.start();p3.start();c1.start();c2.start();}
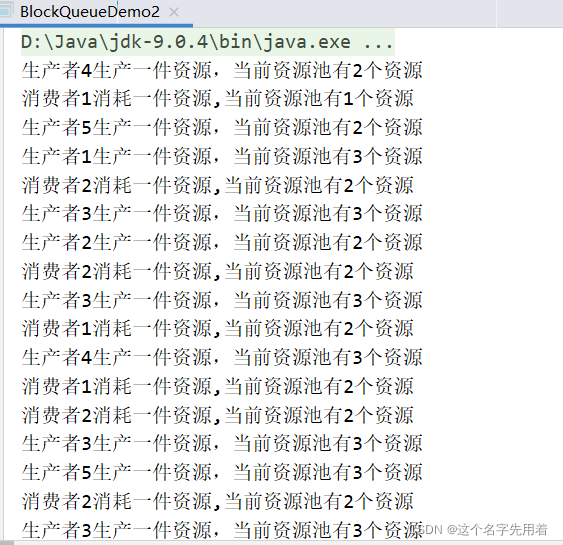
}得到的运行结果为:

可知模拟的生产者消费者模式
(三)代码关键点分析:
1.锁问题:
对于Market中的Producer方法和Cost方法,要使用Synchronized关键字同步非静态方法,且要与wait()方法放在一起,使得在多个消费者生产者线程访问Market中的共享资源时不会发生线程安全问题,并且可以保证锁的时同一个对象
public synchronized void producer()public synchronized void cost ()
2.线程的等待与重启
在生产时达到仓库的最大值后,要停止生产,即让生产的线程处于等待状态,此时需要调用wait()方法,
if(list.size()>=20){this.wait(); //线程休眠} this.notify(); //唤醒线程
要用this来调用wait()方法,而不能用list,是因为被加锁的对象this在调用wait()和notify(),加锁的对象调用 wait() 方法后,线程进入等待状态,直到在加锁的对象上调用 notify() 方法来唤醒之前进入等待的线程
3.While循环放置在Producer和Cost类的run方法中:
使用while循环是原因:要保证线程可以一直运行下去:
public void run(){while(true) {try {Thread.sleep(new Random().nextInt(500)); //设置时间延迟} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {market.cost(); //调用消费方法} catch (InterruptedException e) { // TODO Auto-generated catch blocke.printStackTrace();}}
如果把while循环放在Market中,则睡眠的线程被唤醒之后有可能不满足while()中的条件判定,使得线程线程无法再调用Market中的producer方法,从而无法唤醒线程,因此要放在线程外
4.时间延迟问题:
若要模拟生产和消费的随机过程,还要设置时间延迟
public void run(){while(true) {try {Thread.sleep(new Random().nextInt(500)); //设置时间延迟} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {market.cost(); //调用消费方法} catch (InterruptedException e) { // TODO Auto-generated catch blocke.printStackTrace();}}
放在Producer类中的原因是只有放在run方法中,线程运行时才会具有随机性
否则会发生只有生产达到最大值后才会开始消费