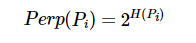目录
1.什么是生产者消费者模式:
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给生产者和消费者解耦的。纵观大多数设计模式,都会找一个第三者出来进行解耦,如工厂模式的第三者是工厂类,模板模式的第三者是模板类。在学习一些设计模式的过程中,如果先找到这个模式的第三者,能帮助我们快速熟悉一个设计模式。

如上图所示:当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
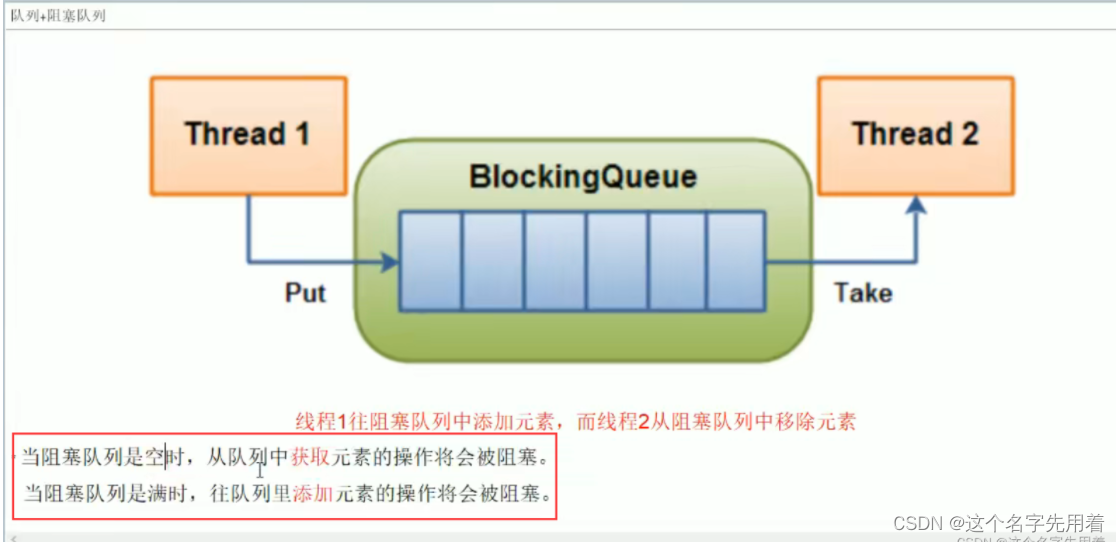
如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
2.生产者消费者模型的实现:
生产者是一堆线程,消费者是另一堆线程,内存缓冲区可以使用List数组队列,数据类型只需要定义一个简单的类就好。关键是如何处理多线程之间的协作。这其实也是多线程通信的一个范例。
在这个模型中,最关键就是内存缓冲区为空的时候消费者必须等待,而内存缓冲区满的时候,生产者必须等待。其他时候可以是个动态平衡。值得注意的是多线程对临界区资源(即共享资源)的操作时候必须保证在读写中只能存在一个线程,所以需要设计锁的策略。
第一种:使用 synchronized和wait、notify
package com.fan.blockqueue;
import java.util.concurrent.TimeUnit;
//使用 synchronized和wait、notify实现生产者和消费者
//1.定义资源类
class MyCacheResources1{int num = 0;//共享资源:生产和消费数字//资源池中实际存储的数据个数private int count = 0;//资源池中允许存放的资源数目private int capacity = 5;Object obj= new Object();//作为锁//生产方法public void product() throws InterruptedException {//使用代码块,精确加锁,且synchronized会自动释放锁synchronized (obj){//1.判断什么时候等待if(count == capacity){//当实际元素数量达到总容量是,生产阻塞等待obj.wait();}//2.干活num++;count++;//生产一个数字,元素数量+1System.out.println(Thread.currentThread().getName()+"生产了一个数字"+num+",资源池剩余数据个数:"+count);//3.干完后后通知唤醒 消费者来消费obj.notifyAll();//唤醒其他所有线程,让他们竞争锁}}//消费的方法public void consumer() throws InterruptedException {synchronized (obj){//1.判断什么时候等待if(count == 0){//当实际元素数量达到总容量是,生产阻塞等待obj.wait();}//2.干活num--;count--;//消费一个元素,数量-1System.out.println(Thread.currentThread().getName()+"消费了一个数字"+num+",资源池剩余数据个数:"+count);//3.干完后后通知唤醒 生产者obj.notifyAll();//唤醒其他所有线程,让他们竞争锁}}
}
public class ProductAndConsumerTest1 {public static void main(String[] args) {MyCacheResources1 myCacheResources1 = new MyCacheResources1();//这里我们直接使用匿名内部类的变相lamda表达式来创建线程//生产者new Thread(()->{for (int i = 1; i <=10 ; i++) {//生产10轮try {myCacheResources1.product();} catch (InterruptedException e) {e.printStackTrace();}}},"生产者").start();//消费者new Thread(()->{//让生产者先 生产数据for (int i = 1; i <=10 ; i++) {//消费10轮,try { TimeUnit.SECONDS.sleep(1);}catch (InterruptedException e) {e.printStackTrace();}try {myCacheResources1.consumer();} catch (InterruptedException e) {e.printStackTrace();}}},"消费者1").start();new Thread(()->{//让生产者先 生产数据for (int i = 1; i <=10 ; i++) {//消费10轮,try { TimeUnit.SECONDS.sleep(1);}catch (InterruptedException e) {e.printStackTrace();}try {myCacheResources1.consumer();} catch (InterruptedException e) {e.printStackTrace();}}},"消费者2").start();}
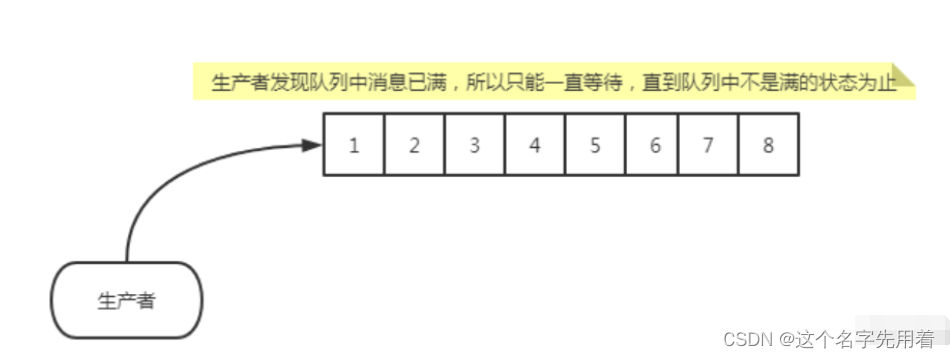
}打印结果:

第二种:使用 Lock和await、signal
package com.fan.blockqueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;//定义资源类
class MyCacheResources2{int num = 0;//共享资源:生产和消费数字//资源池中实际存储的数据个数private int count = 0;//资源池中允许存放的资源数目private int capacity = 5;//创建可重入的非公平锁Lock lock = new ReentrantLock();//使用两个条件队列condition来实现精确通知Condition productCondition = lock.newCondition();Condition consumerCondition = lock.newCondition();//定义操作资源类的方法:生产方法public void product() throws InterruptedException {lock.lock();//加锁try {//1.判断什么时候等待,并防止虚假唤醒while(count == capacity){//当达到最大容量,则阻塞等待,生产者阻塞productCondition.await();}//2.干活num++;//共享资源+1count++;//元素实际个数+1System.out.println(Thread.currentThread().getName()+"\t 生产了一个数字:"+num+",现在资源池剩余数据个数:"+count);//3.通知。生产者生产完立马通知消费者来消费consumerCondition.signal();//消费者条件队列被唤醒} finally {lock.unlock();//解锁}}//定义操作资源类的方法:生产方法public void consumer() throws InterruptedException {lock.lock();//加锁,同一把锁try {//1.判断什么时候等待,并防止虚假唤醒while(count == 0){//没数据时,则阻塞等待,消费者阻塞consumerCondition.await();}//2.干活//共享资源-1count--;//元素实际个数-1System.out.println(Thread.currentThread().getName()+"\t 消费了一个数字:"+(num--)+",现在资源池剩余数据个数:"+count);//3.通知。消费者 消费完 立马通知生产者来生产productCondition.signal();//生产者条件队列被唤醒} finally {lock.unlock();//解锁}}
}
public class ProductAndConsumerTest2 {public static void main(String[] args) {MyCacheResources2 myCacheResources2 = new MyCacheResources2();//可以定义多个生产者和消费者,这里分别定义了一个new Thread(()->{for (int i = 0; i < 10; i++) {//10轮生产try {try { TimeUnit.SECONDS.sleep(1);}//让生产者 先 生产catch (InterruptedException e) {e.printStackTrace();}myCacheResources2.product();} catch (InterruptedException e) {e.printStackTrace();}}},"生产者").start();new Thread(()->{for (int i = 0; i < 10; i++) {//10轮消费try {myCacheResources2.consumer();} catch (InterruptedException e) {e.printStackTrace();}}},"消费者").start();}
}注意:Condition 可以达到精确通知哪个线程要被唤醒的。很方便。而synchronized办不到精确通知的效果。
第三种:使用 阻塞队列 BlockingQueue
package com.fan.blockqueue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;//资源类
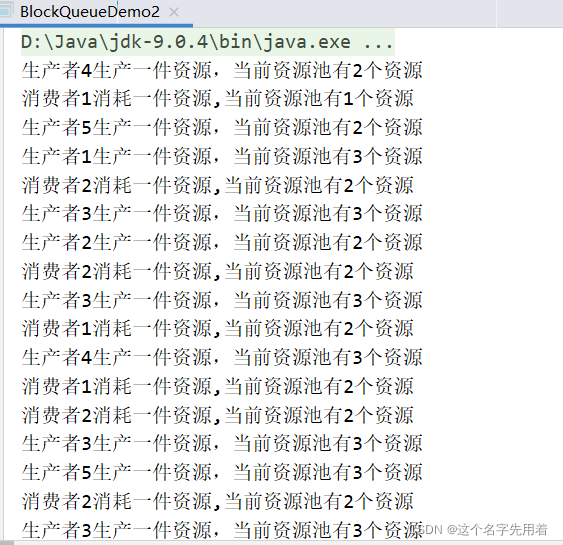
class MyResource3{private BlockingQueue blockingQueue = new ArrayBlockingQueue(3);//线程操作资源类//向资源池中添加资源public void add() throws InterruptedException {try {//put自带锁和通知唤醒方法try { TimeUnit.SECONDS.sleep(1);}//模拟生产耗时1秒catch (InterruptedException e) {e.printStackTrace();}//put方法是自带锁的阻塞唤醒方法,不需要我们写锁,通知和唤醒blockingQueue.put(1);System.out.println("生产者"+Thread.currentThread().getName()+"生产一件资源,当前资源池有"+blockingQueue.size()+"个资源");} catch (InterruptedException e) {e.printStackTrace();}}//向资源池中移除资源public void remove(){try {try { TimeUnit.SECONDS.sleep(1);}//模拟消费耗时1秒catch (InterruptedException e) {e.printStackTrace();}Object take = blockingQueue.take();//自带锁和通知唤醒方法System.out.println("消费者" + Thread.currentThread().getName() +"消耗一件资源," + "当前资源池有" + blockingQueue.size()+ "个资源");} catch (InterruptedException e) {e.printStackTrace();}}
}
//使用阻塞队列BlockingQueue解决生产者消费者
public class BlockQueueDemo2 {public static void main(String[] args) {MyResource3 myResource3 = new MyResource3();//这里可以通过for循环的次数控制生产者和消费者的比例,来模拟缓存区的缓存剩余情况for (int i = 1; i <= 5 ; i++) {//请变换生产者和消费者数量进行测试//模拟两个生产者线程new Thread(()->{while(true){//循环生产try {myResource3.add();//生产数据} catch (InterruptedException e) {e.printStackTrace();}}},String.valueOf(i)).start();}for (int i = 1; i <= 2 ; i++) {//5个消费者new Thread(()->{while (true){//循环消费myResource3.remove();}},String.valueOf(i)).start();}}
}