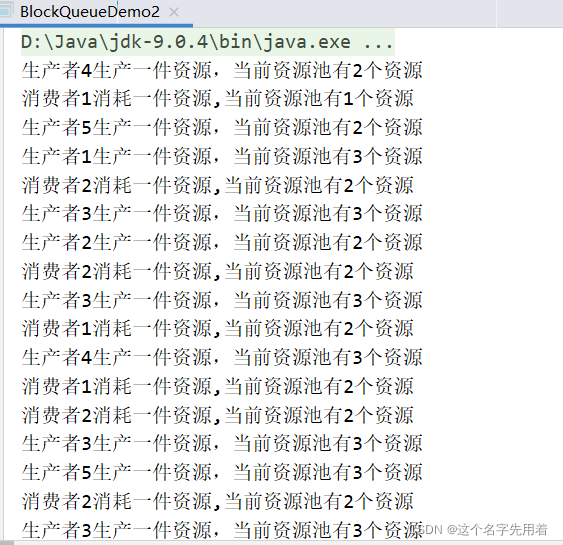
1 基本概括

2 主要介绍
2.1 概念
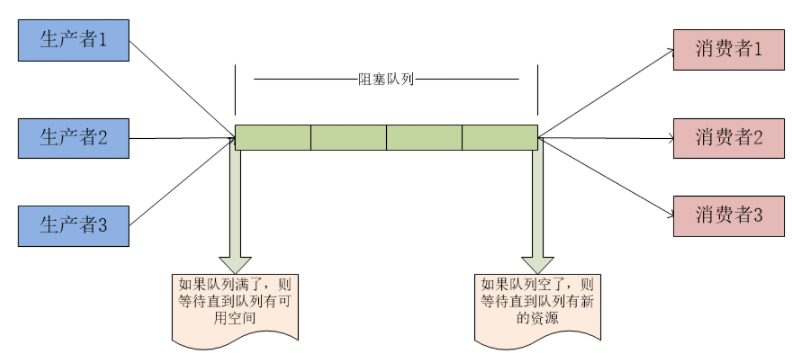
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力
这个阻塞队列就是用来给生产者和消费者解耦的。
如果缓冲区已经满了,则生产者线程阻塞;
如果缓冲区为空,那么消费者线程阻塞。
2.2 生产消费者模型
就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品
注册用户这种服务,它可能解耦成好几种独立的服务(账号验证,邮箱验证码,手机短信码等)。它们作为消费者,等待用户输入数据,在前台数据提交之后会经过分解并发送到各个服务所在的url,分发的那个角色就相当于生产者。消费者在获取数据时候有可能一次不能处理完,那么它们各自有一个请求队列,那就是内存缓冲区了。做这项工作的框架叫做消息队列。
2.3 生产者消费者模型的实现
生产者是一堆线程,消费者是另一堆线程,内存缓冲区可以使用List数组队列,数据类型只需要定义一个简单的类就好。关键是如何处理多线程之间的协作。这其实也是多线程通信的一个范例。
在这个模型中,最关键就是内存缓冲区为空的时候消费者必须等待,而内存缓冲区满的时候,生产者必须等待。其他时候可以是个动态平衡。值得注意的是多线程对临界区资源的操作时候必须保证在读写中只能存在一个线程,所以需要设计锁的策略。
2.4 为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这种生产消费能力不均衡的问题,所以便有了生产者和消费者模式。
优点
解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
支持并发(concurrency)
生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。
使用了生产者/消费者模式之后,生产者和消费者可以是两个独立的并发主体(常见并发类型有进程和线程两种)。生产者把制造出来的数据往缓冲区一丢,就可以再去生产下一个数据。基本上不用依赖消费者的处理速度。
支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。

2.5 生产者和消费者关系
1)生产者仅仅在仓储未满时候生产,仓满则停止生产。
2)消费者仅仅在仓储有产品时候才能消费,仓空则等待。
3) 当消费者发现仓库没产品可消费时候会通知生产者生产。
4)生产者在生产出可消费产品时候,应该通知等待的消费者去消费。
2.6 多生产者和多消费者场景
在多核时代,多线程并发处理速度比单线程处理速度更快,所以我们可以使用多个线程来生产数据,同样可以使用多个消费线程来消费数据。而更复杂的情况是,消费者消费的数据,有可能需要继续处理,于是消费者处理
完数据之后,它又要作为生产者把数据放在新的队列里,交给其他消费者继续处理。
2.6 线程池与生产消费者模式
Java中的线程池类其实就是一种生产者和消费者模式的实现方式,但是我觉得其实现方式更加高明。生产者把任务丢给线程池,线程池创建线程并处理任务,如果将要运行的任务数大于线程池的基本线程数就把任务扔到阻塞
队列里,这种做法比只使用一个阻塞队列来实现生产者和消费者模式显然要高明很多,因为消费者能够处理直接就处理掉了,这样速度更快,而生产者先存,消费者再取这种方式显然慢一些。
2.7 内存缓冲区
最传统、最常见的方式:队列(FIFO)作缓冲。
2.7.1 线程方式
并发线程中使用队列的优缺点
内存分配的性能
在线程方式下,生产者和消费者各自是一个线程。生产者把数据写入队列头(以下简称push),消费者从队列尾部读出数据(以下简称pop)。当队列为空,消费者就稍息(稍事休息);当队列满(达到最大长度),生产者
就稍息。整个流程并不复杂。 上述过程会有一个主要的问题是关于内存分配的性能开销。对于常见的队列实现:在每次push时,可能涉及到堆内存的分配;在每次pop时,可能涉及堆内存的释放。假如生产者和消费者都很勤快,频繁地push、pop,那内
存分配的开销就很可观了。对于内存分配的开销,可查找Java性能优化相关知识。
解决办法:环形缓冲区。
同步和互斥的性能
另外,由于两个线程共用一个队列,自然就会涉及到线程间诸如同步、互斥、死锁等等。这会儿要细谈的是,同步和互斥的性能开销。在很多场合中,诸如信号量、互斥量等的使用也是有不小的开销的(某些情况下,也可能导致
用户态/核心态切换)。如果像刚才所说,生产者和消费者都很勤快,那这些开销也不容小觑。
适用于队列的场合
由于队列是很常见的数据结构,大部分编程语言都内置了队列的支持,有些语言甚至提供了线程安全的队列(比如JDK 1.5引入的ArrayBlockingQueue)。因此,开发人员可以捡现成,避免了重新发明轮子。
所以,假如你的数据流量不是很大,采用队列缓冲区的好处还是很明显的:逻辑清晰、代码简单、维护方便。比较符合KISS原则。
2.7.2 进程方式
跨进程的生产者/消费者模式,非常依赖于具体的进程间通讯(IPC)方式。而IPC的种类很多。下面介绍比较常用的跨平台、且编程语言支持较多的IPC方式。
匿名管道
感觉管道是最像队列的IPC类型。生产者进程在管道的下端放入数据;消费者进程在管道的读端取出数据。整个的效果和线程中使用队列非常类似,区别在于使用管道就无需操心线程安全、内存分配等琐事
管道又分命名管道和匿名管道两种,今天主要聊匿名管道。因为命名管道在不同的操作系统下差异较大(比如Win32和POSIX,在命名管道的API接口和功能实现上都有较大差异;有些平台不支持命名管道,
比如Windows CE)。除了操作系统的问题,对于有些编程语言(比如Java)来说,命名管道是无法使用的。
其实匿名管道在不同平台上的API接口,也是有差异的(比如Win32的CreatePipe和POSIX的pipe,用法就很不一样)。但是我们可以仅使用标准输入和标准输出(以下简称stdio)来进行数据的流入流出。然
后利用shell的管道符把生产者进程和消费者进程关联起来。实际上,很多操作系统(尤其是POSIX风格的)自带的命令都充分利用了这个特性来实现数据的传输(比如more、grep等),如此优点:
1、基本上所有操作系统都支持在shell方式下使用管道符。因此很容易实现跨平台。
2、大部分编程语言都能够操作stdio,因此跨编程语言也就容易实现。
3、管道方式省却了线程安全方面的琐事。有利于降低开发、调试成本。
当然,这种方式也有自身的缺点:
1、生产者进程和消费者进程必须得在同一台主机上,无法跨机器通讯。这个缺点比较明显
2、在一对一的情况下,这种方式挺合用。但如果要扩展到一对多或者多对一,那就有点棘手了。所以这种方式的扩展性要打个折扣。假如今后要考虑类似的扩展,这个缺点就比较明显。
3、由于管道是shell创建的,对于两边的进程不可见(程序看到的只是stdio)。在某些情况下,导致程序不便于对管道进行操纵(比如调整管道缓冲区尺寸)。这个缺点不太明显。
4、最后,这种方式只能单向传数据。好在大多数情况下,消费者进程不需要传数据给生产者进程。万一你确实需要信息反馈(从消费者到生产者),那就费劲了。可能得考虑换种IPC方式。
注意事项:
1、对stdio进行读写操作是以阻塞方式进行。比如管道中没有数据,消费者进程的读操作就会一直停在哪儿,直到管道中重新有数据。
2、由于stdio内部带有自己的缓冲区(这缓冲区和管道缓冲区是两码事),有时会导致一些不太爽的现象(比如生产者进程输出了数据,但消费者进程没有立即读到)。
SOCKET(TCP方式)
基于TCP方式的SOCKET通讯是又一个类似于队列的IPC方式。它同样保证了数据的顺序到达;同样有缓冲的机制。而且跨平台和跨语言,和刚才介绍的shell管道符方式类似。
SOCKET相比shell管道符的方式,主要有如下几个优点:
1、SOCKET方式可以跨机器(便于实现分布式)。这是主要优点。
2、SOCKET方式便于将来扩展成为多对一或者一对多。这也是主要优点。
3、SOCKET可以设置阻塞和非阻塞方法,用起来比较灵活。这是次要优点。
4、SOCKET支持双向通讯,有利于消费者反馈信息。
这么做的关键点在于把代码分为两部分:生产线程和消费线程属于和业务逻辑相关的代码(和通讯逻辑无关);发送线程和接收线程属于通讯相关的代码(和业务逻辑无关)。
虽然TCP在很多方面比UDP可靠,但鉴于跨机器通讯先天的不可预料性,在程序设计上我们还是要多留一手。
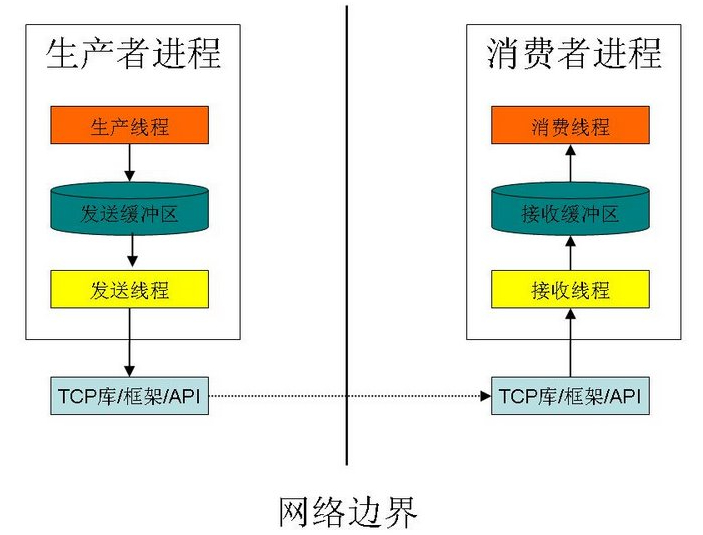
这样的好处是很明显的,具体如下:
1、能够应对暂时性的网络故障。并且在网络故障解除后,能够继续工作。
2、网络故障的应对处理方式(比如断开后的尝试重连),只影响发送和接收线程,不会影响生产线程和消费线程(业务逻辑部分)。
3、具体的SOCKET方式(阻塞和非阻塞)只影响发送和接收线程,不影响生产线程和消费线程(业务逻辑部分)。
4、不依赖TCP自身的发送缓冲区和接收缓冲区。(默认的TCP缓冲区的大小可能无法满足实际要求)
5、业务逻辑的变化(比如业务需求变更)不影响发送线程和接收线程。
2.7.3 环形缓冲区
使用场景:当存储空间(不仅包括内存,还可能包括诸如硬盘之类的存储介质)的分配/释放非常频繁并且确实产生了
明显的影响,才应该考虑环形缓冲区的使用。否则的话,还是选用最基本、最简单的队列缓冲区。
3 实现生产者消费者的三种模式
3.1 synchronized、wait和notify
//wait 和 notify
public class ProducerConsumerWithWaitNofity {public static void main(String[] args) {Resource resource = new Resource();//生产者线程ProducerThread p1 = new ProducerThread(resource);ProducerThread p2 = new ProducerThread(resource);ProducerThread p3 = new ProducerThread(resource);//消费者线程ConsumerThread c1 = new ConsumerThread(resource);//ConsumerThread c2 = new ConsumerThread(resource);//ConsumerThread c3 = new ConsumerThread(resource);p1.start();p2.start();p3.start();c1.start();//c2.start();//c3.start();}
}
/*** 公共资源类* @author**/
class Resource{//重要//当前资源数量private int num = 0;//资源池中允许存放的资源数目private int size = 10;/*** 从资源池中取走资源*/public synchronized void remove(){if(num > 0){num--;System.out.println("消费者" + Thread.currentThread().getName() +"消耗一件资源," + "当前线程池有" + num + "个");notifyAll();//通知生产者生产资源}else{try {//如果没有资源,则消费者进入等待状态wait();System.out.println("消费者" + Thread.currentThread().getName() + "线程进入等待状态");} catch (InterruptedException e) {e.printStackTrace();}}}/*** 向资源池中添加资源*/public synchronized void add(){if(num < size){num++;System.out.println(Thread.currentThread().getName() + "生产一件资源,当前资源池有"+ num + "个");//通知等待的消费者notifyAll();}else{//如果当前资源池中有10件资源try{wait();//生产者进入等待状态,并释放锁System.out.println(Thread.currentThread().getName()+"线程进入等待");}catch(InterruptedException e){e.printStackTrace();}}}
}
/*** 消费者线程*/
class ConsumerThread extends Thread{private Resource resource;public ConsumerThread(Resource resource){this.resource = resource;}@Overridepublic void run() {while(true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}resource.remove();}}
}
/*** 生产者线程*/
class ProducerThread extends Thread{private Resource resource;public ProducerThread(Resource resource){this.resource = resource;}@Overridepublic void run() {//不断地生产资源while(true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}resource.add();}}}3.2 lock和condition的await、signalAll
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/*** 使用Lock 和 Condition解决生产者消费者问题* @author tangzhijing**/
public class LockCondition {public static void main(String[] args) {Lock lock = new ReentrantLock();Condition producerCondition = lock.newCondition();Condition consumerCondition = lock.newCondition();Resource2 resource = new Resource2(lock,producerCondition,consumerCondition);//生产者线程ProducerThread2 producer1 = new ProducerThread2(resource);//消费者线程ConsumerThread2 consumer1 = new ConsumerThread2(resource);ConsumerThread2 consumer2 = new ConsumerThread2(resource);ConsumerThread2 consumer3 = new ConsumerThread2(resource);producer1.start();consumer1.start();consumer2.start();consumer3.start();}
}
/*** 消费者线程*/
class ConsumerThread2 extends Thread{private Resource2 resource;public ConsumerThread2(Resource2 resource){this.resource = resource;//setName("消费者");}public void run(){while(true){try {Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {e.printStackTrace();}resource.remove();}}
}
/*** 生产者线程* @author tangzhijing**/
class ProducerThread2 extends Thread{private Resource2 resource;public ProducerThread2(Resource2 resource){this.resource = resource;setName("生产者");}public void run(){while(true){try {Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {e.printStackTrace();}resource.add();}}
}
/*** 公共资源类* @author tangzhijing**/
class Resource2{private int num = 0;//当前资源数量private int size = 10;//资源池中允许存放的资源数目private Lock lock;private Condition producerCondition;private Condition consumerCondition;public Resource2(Lock lock, Condition producerCondition, Condition consumerCondition) {this.lock = lock;this.producerCondition = producerCondition;this.consumerCondition = consumerCondition;}/*** 向资源池中添加资源*/public void add(){lock.lock();try{if(num < size){num++;System.out.println(Thread.currentThread().getName() + "生产一件资源,当前资源池有" + num + "个");//唤醒等待的消费者consumerCondition.signalAll();}else{//让生产者线程等待try {producerCondition.await();System.out.println(Thread.currentThread().getName() + "线程进入等待");} catch (InterruptedException e) {e.printStackTrace();}}}finally{lock.unlock();}}/*** 从资源池中取走资源*/public void remove(){lock.lock();try{if(num > 0){num--;System.out.println("消费者" + Thread.currentThread().getName() + "消耗一件资源," + "当前资源池有" + num + "个");producerCondition.signalAll();//唤醒等待的生产者}else{try {consumerCondition.await();System.out.println(Thread.currentThread().getName() + "线程进入等待");} catch (InterruptedException e) {e.printStackTrace();}//让消费者等待}}finally{lock.unlock();}}}3.3 使用阻塞队列实现的版本
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;//使用阻塞队列BlockingQueue解决生产者消费者
public class BlockingQueueConsumerProducer {public static void main(String[] args) {Resource3 resource = new Resource3();//生产者线程ProducerThread3 p = new ProducerThread3(resource);//多个消费者ConsumerThread3 c1 = new ConsumerThread3(resource);ConsumerThread3 c2 = new ConsumerThread3(resource);ConsumerThread3 c3 = new ConsumerThread3(resource);p.start();c1.start();c2.start();c3.start();}
}
/*** 消费者线程* @author tangzhijing**/
class ConsumerThread3 extends Thread {private Resource3 resource3;public ConsumerThread3(Resource3 resource) {this.resource3 = resource;//setName("消费者");}public void run() {while (true) {try {Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {e.printStackTrace();}resource3.remove();}}
}
/*** 生产者线程* @author tangzhijing**/
class ProducerThread3 extends Thread{private Resource3 resource3;public ProducerThread3(Resource3 resource) {this.resource3 = resource;//setName("生产者");}public void run() {while (true) {try {Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {e.printStackTrace();}resource3.add();}}
}
class Resource3{private BlockingQueue resourceQueue = new LinkedBlockingQueue(10);/*** 向资源池中添加资源*/public void add(){try {resourceQueue.put(1);System.out.println("生产者" + Thread.currentThread().getName()+ "生产一件资源," + "当前资源池有" + resourceQueue.size() + "个资源");} catch (InterruptedException e) {e.printStackTrace();}}/*** 向资源池中移除资源*/public void remove(){try {resourceQueue.take();System.out.println("消费者" + Thread.currentThread().getName() + "消耗一件资源," + "当前资源池有" + resourceQueue.size() + "个资源");} catch (InterruptedException e) {e.printStackTrace();}}
}3.4 进阶写法(高并发、消息中间件)
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;/** 生产者消费者【高并发版】* 使用阻塞队列实现* 生产和消费过程自动化进行,不需要进行干预* 消息中间件底层原理*/
class SourceQueue{private volatile boolean flag = true; //默认开启,进行生产+消费private AtomicInteger atomicInteger = new AtomicInteger();BlockingQueue<String> blockingQueue = null;// 构造注入,传入接口实现类,可以适配7种阻塞队列public SourceQueue(BlockingQueue<String> blockingQueue) {this.blockingQueue = blockingQueue;// 利用反射获取传入类System.out.println("传入阻塞队列\n"+blockingQueue.getClass().getName()+"\n");}// 生产线程public void pord()throws Exception{String data = null;// 数据boolean offer;while( flag ) {data = atomicInteger.incrementAndGet()+"";offer = blockingQueue.offer(data,2L,TimeUnit.SECONDS);if(offer) {System.out.println(Thread.currentThread().getName()+" 插入队列,data "+data+" 成功");}else {System.out.println(Thread.currentThread().getName()+" 插入队列,data "+data+" 失败");}TimeUnit.SECONDS.sleep(1);}System.out.println(Thread.currentThread().getName()+" 停止生产 ,flag="+flag+"生产动作结束");}// 消费者public void consumer()throws Exception{String result = null;while( flag ) {result = blockingQueue.poll(2L, TimeUnit.SECONDS);if(result == null || result.equalsIgnoreCase("")){flag = false;System.out.println(Thread.currentThread().getName()+" 超过2s没有取到,消费退出");System.out.println();return;}System.out.println(Thread.currentThread().getName()+" 消费队列 ,result="+result);}}public void stop() throws Exception{this.flag = false;}
}public class ProductConsumer_2 {public static void main(String[] args) throws Exception {SourceQueue sourceQueue = new SourceQueue(new ArrayBlockingQueue<>(10));new Thread(()->{System.out.println(Thread.currentThread().getName()+" 生产者线程启动");try {sourceQueue.pord();} catch (Exception e) {e.printStackTrace();}},"Prod").start();new Thread(()->{System.out.println(Thread.currentThread().getName()+" 消费者线程启动");try {sourceQueue.consumer();} catch (Exception e) {e.printStackTrace();}},"Consumer").start();TimeUnit.SECONDS.sleep(5);System.out.println();System.out.println(Thread.currentThread().getName()+" BOSS 停止");System.out.println();sourceQueue.stop();}
}4 常遇见的问题
1、生产者消费者模型的作用是什么
2、生产者消费者模式的优点常见出现的问题会在后面的文章讨论,一起学习的朋友可以点点关注,会持续更新,文章有帮助的话可以收藏,转发,有什么补充可以在下面评论,谢谢!