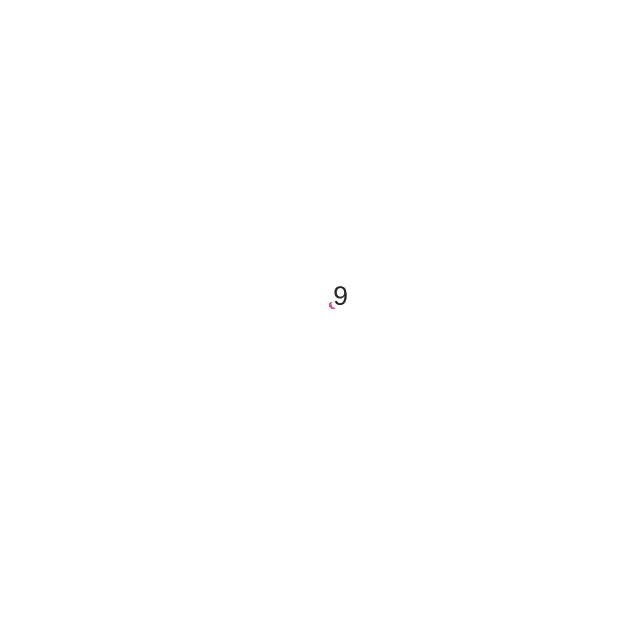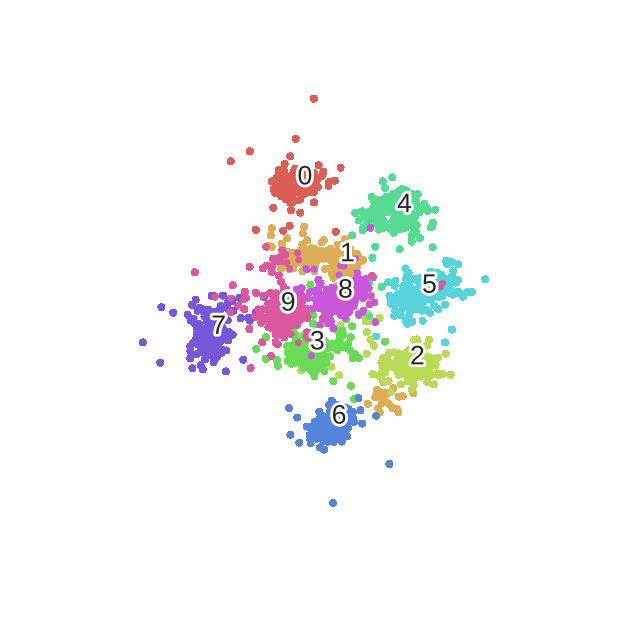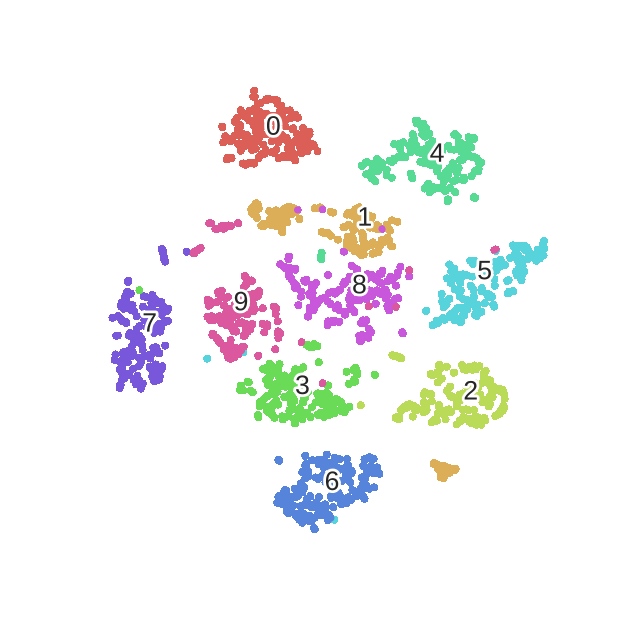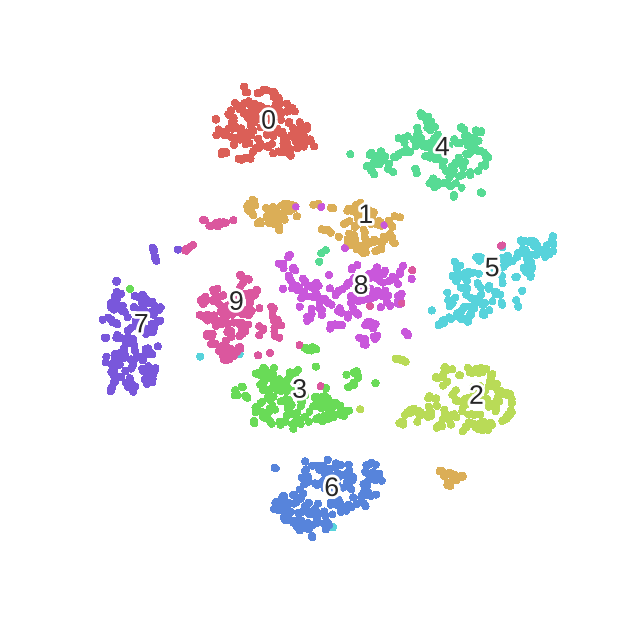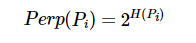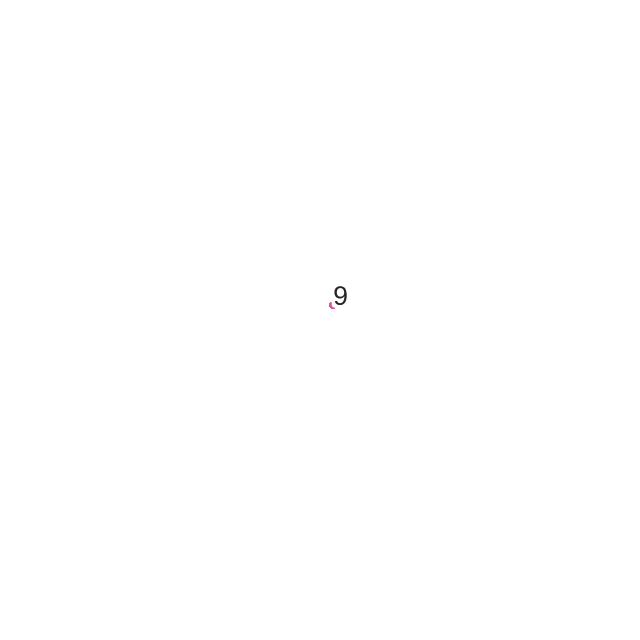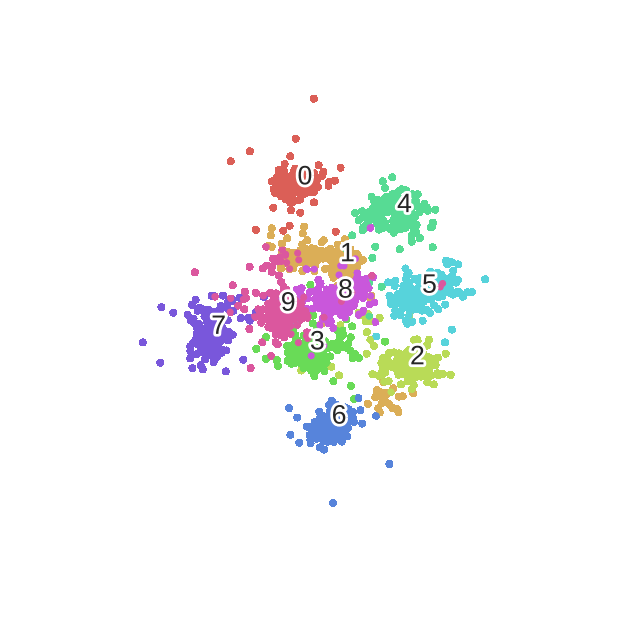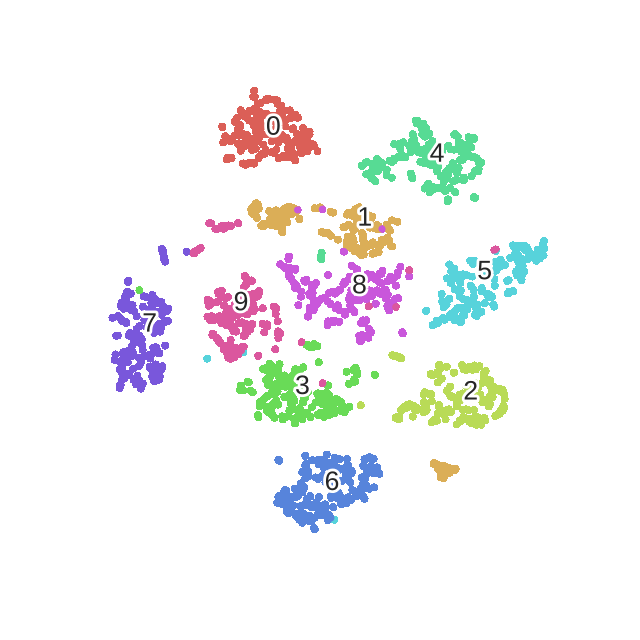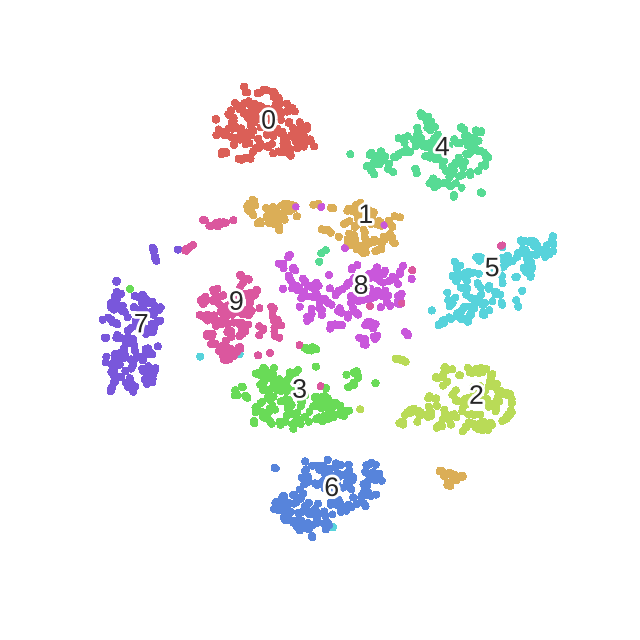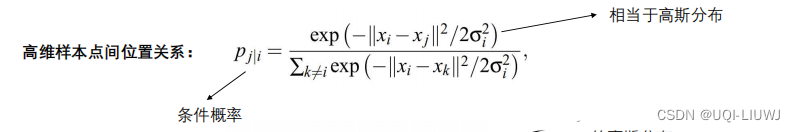如有错误,恳请指出。
这篇博客将会介绍一个无监督的降维算法——t-SNE,其是一个常用的降维可视化工具,下面会记录一下李宏毅老师对其的原理介绍,然后我做了一个实验,用其来对手写数字(MNIST数据集)进行降维的一个效果展示。
文章目录
- 1. t-SNE原理介绍
- 1.1 manifold介绍
- 1.2 LLE
- 1.3 t-SNE
- 2. t-SNE可视化效果
- 2.1 2D可视化效果
- 2.2 3D可视化效果
- 3. t-SNE降维后对MNIST数据集进行分类
1. t-SNE原理介绍
t-SNE全称是t-distributed Stochastic Neighbor Embedding,所以manifold方法的一种。
1.1 manifold介绍
什么是manifold,比如地球的表面就是一个maniflod,其本身是一个二维的平面,但是却被塞到了一个三维的平面中。所以此时只有比较接近的距离时,这个空间的欧式距离(Euclidean distance)才会成立,但是如果两个点距离比较远,那么这个欧式几何就不一定会成立。

如这个图为例,在高维空间中,直接计算欧式距离来比较两个样本的相似程度很大概率上是出错的。所以manifold learning要做的事情是把S型的这块东西展开,就是把塞到高维空间的地位空间摊平。

这样摊平之后就可以进行欧式距离计算,也就是降维的目标。下面会介绍两种方法:LLE与t-SNE。
1.2 LLE
paper:Think Globally, Fit Locally: Unsupervised Learning of Low Dimensional Manifolds
对样本xi,进行一个∑|| xi - ∑j wij*xj || 的二范数优化,固定住参数Wij,然后重新找一个新的向量z,满足∑|| zi - ∑j wij*zj ||,如下所示:

处理的效果:

1.3 t-SNE
在LLE中解决的问题是,想要想接近的点都是应该相邻的,但是其没有补充不同的点不同的类别需要分开。所以不同的目标其实是挤在一起的。

首先对原来的数据中,计算所以其他样本xj与xi的一个相似程度:S(xi, xj),然后再做一个normalization,就是用S(xi, xj)除以一个正则项。其会summation over除了xi以外所有其他的点和xi之间所算出来的距离。对于另外的一个低维的数据分布也可以计算出一个Q(zi,zi)。
这个normalization是必要的,因为无法知道在高维中的S(xi, xj)与低维空间中的S'(zi, zj)的scale是否是一致的。那么如果做了normalization,最后就可以把这个数值变成是几率的含义。
但是现在zi与zj是不知道的,所以希望可以找到zi与zj可以使得P(xj | xi)与Q(zj | zi)这两个数据分布尽可能的相同,越接近越好。也就是根据similarity在S这个原来的space算出来的distribution与这个降维后的space算出来的distribution越接近越好。而衡量两个数据分布的相似程度的方法,就是KL divergence。

那么,现在所需要做的事情就是找到一组z,其可以做到xi对其他样本点的distribution与zi对其他样本点的distribution,这两个distribution的KL divergence越小越好。然后summation over所以的样本点,就是损失函数的定义。最后目的是使这个损失越小越好。
损失计算的处理其实就梯度下降法,把公式带进去然后对z作微分即可,但是t-SNE的一个问题就是其需要对所以的样本点做一个相似度,所以如果样本太多可能跑不动。一个常见的做法是相用一些其他的降维算法比如PCA,然后再用t-SNE进一步的降维。但是如果现在有一个新的样本来融入原来的样本,可以发现t-SNE其实是无法解决这个问题的,所以也就是t-SNE不适合做training与testing的训练,其实其只适合做一个可视化的结果,来看看对于这个高维的数据降维后的过是怎么样的。
最后,补充一下在t-SNE中similarity的选择:

一个很直观的解释是:如果本来距离比较近,那么其实影响是比较小的,高维的分布与降维后的分布也算是比较接近的;但是如果本来就有一段距离,那么从原来的高维distribution变为了t-distribution之后,他会被拉得很远。t-distribution的尾巴特别长,所以如果你本来的距离比较远的话,降维变成t-distribution之后,其距离会变得更远。也就说,如果在原来的高维空间中,如果距离很近,降维后其实还算很近;但是原来如果在高维空间中就有一个距离了,那么降维后其会被拉得很远。
2. t-SNE可视化效果
下面是我用手写数字识别,使用t-SNE作的图:
2.1 2D可视化效果

2.2 3D可视化效果

不同的颜色会代表不同的数值,那么会发现无论是降到2维还是3维,不同的数字都是一群一群的。这部分的代码在我的上一篇博文中,有兴趣的的可以查看:《Scikit-learn学习系列 | 5. sklearn特征降维可视化展示(t-SNE、PCA、KernelPCA、MDS、SpectralEmbedding)》。除了t-SNE之外,里面还包含了对PCA,kernelPCA,MSD与SpectralEmbedding的降维效果展示。
- 李宏毅老师的结果

所以,总的来说,t-SNE是一个很好的可视化工具,但是其不适合做训练与测试的任务。就是就拿手写数字识别任务来是哦,如果你用t-SNE来进行降维然后再用一个分类算法比如svm或者随机森林来进行分类,其实效果是不好的。这也是无监督算法的一个毛病就是,你已经把他聚类成了10个簇,但其实这时候不知道哪个簇是哪一类,能做到的只是将数据样本区分开。
3. t-SNE降维后对MNIST数据集进行分类
在刚刚的理论部分也已经提及,t-SNE其实适合做一个可视化的结果,其不适合做一个training与testing的任务的。这里用t-SNE降维后的数据进行一个分类处理,验证一下理论。
- 数据集准备
from sklearn import preprocessing
from sklearn.manifold import TSNEimport torch
import torchvisiontraindata = torchvision.datasets.MNIST(root='./dataset/', train=True, download=True)
testdata = torchvision.datasets.MNIST(root='./dataset/', train=False, download=True)X_train = traindata.data
y_train = traindata.targets
X_test = testdata.data
y_test = testdata.targets
# X_train.shape, y_train.shape, X_test.shape, y_test.shape
# 输出:
# (torch.Size([60000, 28, 28]),
# torch.Size([60000]),
# torch.Size([10000, 28, 28]),
# torch.Size([10000]))
- 数据降维
X_train = X_train.view(len(X_train), -1)
X_test = X_test.view(len(X_test), -1)# t-SNE降维处理
tsne = TSNE(n_components=3, verbose=1 ,random_state=42)
result = tsne.fit_transform(X_train)# 归一化处理
scaler = preprocessing.MinMaxScaler(feature_range=(-1,1))
result = scaler.fit_transform(result)
- 可视化结果
import matplotlib.pyplot as pltfig = plt.figure(figsize=(20, 20))
ax = fig.add_subplot(projection='3d')
ax.set_title('t-SNE process')
ax.scatter(result[:,0], result[:,1], result[:,2] , c=y_train, s=10)
-
训练集的3D可视化效果

-
模型训练与验证
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np# 查看随机森林拟合训练集的结果
y_train = np.array(y_train)
clf = RandomForestClassifier(random_state=42)
clf.fit(result, y_train)
clf.score(result, y_train)# 需要重新降维,这就是不适合做训练任务的原因
test = tsne.fit_transform(X_test)
test = scaler.transform(test)# 测试数据的可视化结果
fig = plt.figure(figsize=(20, 20))
ax = fig.add_subplot(projection='3d')
ax.set_title('t-SNE process')
ax.scatter(test[:,0], test[:,1], test[:,2] , c=y_test, s=10)# 模型测试
train_pred = clf.predict(result)
test_pred = clf.predict(test)# 查看训练效果
y_test = np.array(y_test)
testscore = accuracy_score(y_test, test_pred)
trainscore = accuracy_score(y_train, train_pred)
print("trainscore:{}, testscore:{}".format(trainscore, testscore))
- 测试集的3D可视化效果

打印出来的结果:trainscore:1.0, testscore:0.0523
所以可以看见效果是非常的惨不忍睹,但是其可视化效果是挺好的。所以使用t-SNE降维后再分类其实效果是不好的,因为t-SNE本身就是一个无监督的分类算法。
ps:随便用一个随机森林的算法对MNIST数据集进行分类的结果都有97+%
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
train_pred = clf.predict(X_train)
test_pred = clf.predict(X_test)
testscore = accuracy_score(y_test, test_pred)
trainscore = accuracy_score(y_train, train_pred)
print("trainscore:{}, testscore:{}".format(trainscore, testscore))
打印出来的结果:trainscore:1.0, testscore:0.9705
参考资料:
1. Scikit-learn学习系列 | 5. sklearn特征降维可视化展示
2. MINST数据集的分类与效果验证
3. 机器学习 第16讲 无监督学习 Neighbor Embedding T-SNE
4. 更多关于t-SNE的github参考资料