目录
- 简介
- 环境要求
- 数据爬取
- 爬取目标
- 电影详情页
- 反爬虫破解
- 数据存储
- 服务器搭建
- 电影推荐
- 数据展示
- 电影推荐
- 电影评分
- 电影票房
- 电影类型词云
简介
这次是一次数据库实验,实验要求是了解最新的数据库,并使用!做一个简单案例使用。根据实际需要就采用了MongoDB 数据库,因为它是非关系数据库。使用比较简单,而且容易上手。案例是想爬取猫眼2018年上映的所有电影,并进行简单分析。然后进行电影推荐,可以输入一个电影,然后该系统采用推荐算法,推荐5部电影评分类型的电影。写下该博客就是为了记录。以免以后忘记!
环境要求
- 该项目使用了一个比较流行的服务器框架,Nodejs 的Express 服务器搭建框架。
- 也使用了简单的爬虫。基于python3.0 、java8.0
- 数据库:MongoDB4.0, Npm3.10 模块管理。
数据爬取
项目的第一步,就是准备相关的数据。
爬取目标
该项目爬取的电影数据,是2018年猫眼电影上映的电影数据。

分析该页html 结构,我们的目标就是获取索引页里所有电影链接,已经评分信息。
电影详情页
对详情页的信息进行获取,主要获取内容是电影名称、类型、国家、时长、上映时间、评分、评分人数以及累计票房。

反爬虫破解
通过 BeautifulSoup 获取数据的时候,我们发现一些数据很容易就可以获得,但是电影评分,评分人数,累计票房这些数据,施加了反爬。

通过分析文字反爬中的js 事件,我们可以看出,只要刷新页面,三处文字编码就会改变,无法直接匹配信息。 所以需要下载文字文件,对其进行双匹配。然后将woff 格式转换为xml 格式。以便在 pycharm 中查看详细信息。

文字反爬破解后,接下来的工作就简单了,获取自己需要的数据,构造请求头、获取电影详情页链接,获取电影详情页的信息。
数据存储
我们要把获取的数据保存到数据库中,我们使用的是MongoDB 数据库,它是专为可拓展性、高性能、高可用性而设计的数据库,它可以从单服务器部署扩展到大型、复杂的多数据中心架构。利用内存计算的优势,MongoDB 能够提供高性能的数据读写操作。


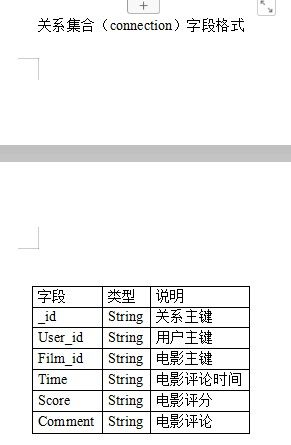
在创建用户集合,电影集合的时候,还需要添加一个两者关系的集合。
用户集合:


服务器搭建
为了让用户能够通过浏览器查看数据,该系统搭建了一个服务器,将用户浏览器发来的查询请求进行处理,谈话服务器从数据库中读取数据,将数据返回给前端,前端将服务器返回的数据进行可视化处理。
服务器的搭建该系统采用了 Express 服务器框架,它是一种保持最低程度规模的灵活 NodeJs web 应用程序框架,为web 和移动应用程序提供一组强大的功能。


电影推荐
根据用户输入的电影名称通过KNN 推荐算法,根据电影类型推荐评分前5的电影。

用户输入电影名称,向服务器发送电影推荐请求,服务器调用脚本执行机器学习的KNN推荐算法,该算法根据用户输入电影的类型进行分类,然后向用户推荐评分最高的5部电影。
数据展示
电影推荐

电影评分

电影票房

电影类型词云

源码已上传到GitHub上 https://github.com/AdminWangYe/Movie