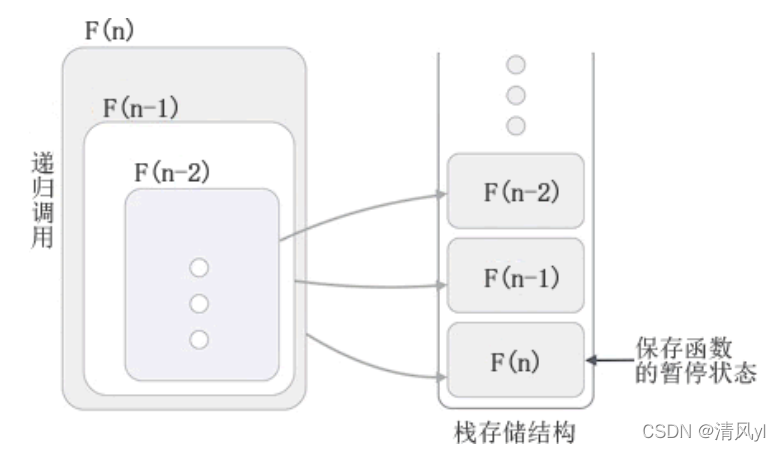
一、HTTP协议介绍
http协议的底层协议是TCP协议。TCP协议是基于数据流的传输方式。其又叫做“超文本传输协议”,为什么呢,因为它是将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器,通过因特网传送万维网文档的数据传送协议。
1. url 统一资源定位器
理论介绍
URL,全称是UniformResourceLocator,中文叫统一资源定位符。它主要是用来表示互联网上的某一个资源的位置的。例如:https://space.bilibili.com/438671228?spm_id_from=333.1007.0.0
便是一个url,其中:
”https://“ 表示的是通信协议,有的是http协议,这个就是https协议(简单理解就是http传输的数据又进行了ssl加密,数据传输更安全)
”space.bilibili.com“ 表示的是域名,域名和ip地址是一一对应的,因为ip地址是类似于这种”140.82.114.3“ 的一串数字,人们很难记忆(例如访问百度主页,你是用xxx.xxx.xxx.xxx简单呢,还是用baidu.com简单呢,肯定是后者啦),所以人们通过DNS解析来将原来的ip地址和域名绑定再一起,这样子访问就简单多啦。(http://127.0.0.1:8080/ 但是例如这种网址,可能会在域名后面添加 ":" 然后后面跟上一个数字,这个表示的是服务器的端口号,默认http协议是80端口,其他的还有好多,自己有兴趣可以查一查)
”/438671228“ 这一部分内容叫做虚拟目录(也叫做虚拟文件吧),就像是你电脑访问文件夹的目录一样,通常域名后面开始到 “?” 或者 “#” 为止中间的部分(上面这个链接就是到 “?” 结束)。
“?spm_id_from=333.1007.0.0” 后面这部分叫做参数部分。不同的参数之间用 ”&“ 符号分开,上面这个只有一个参数,所以没有 ”&“ 符号。每一个参数对应的值用 “=” 连接。
有的后面还会有 “#” ,其代表的是锚部分,这个我也不太懂啊哈哈哈哈,不常用基本。
例子介绍
为了大家更好的理解url,下面我按照格式瞎编一个链接大家看一下:https://GaoZhong.com/HighSchoolSophomore/ClassEight?student=DounkeyBall&year=2017
这个链接的意思就是:采用https协议连接 GaoZhong.com 这个网站的HighSchoolSophomore目录下的ClassEight文件,访问的参数student是DounkeyBall,参数year是2017。(当然有的url可能会出现%,类似这种的:https://GaoZhong.com/%E9%AB%98%E4%BA%8C/%E5%85%AB%E7%8F%AD?%E5%AD%A6%E7%94%9F=%E9%A9%B4%E7%90%83&%E5%B9%B4%E4%BB%BD=2017
这是因为url不支持直接输入中文汉字,所有的中文汉字都被url编码成 "%??" 的形式了,有兴趣的可以解码看看内容,当然这个网址是我瞎编的,肯定访问不了哈哈哈哈哈)
2. http的请求(Request)
所有的用户通过http协议来和服务器交互都是采用Request的方式来进行的。
GET请求
客户端向服务器发起的一个HTTP请求主要包括以下几个内容:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
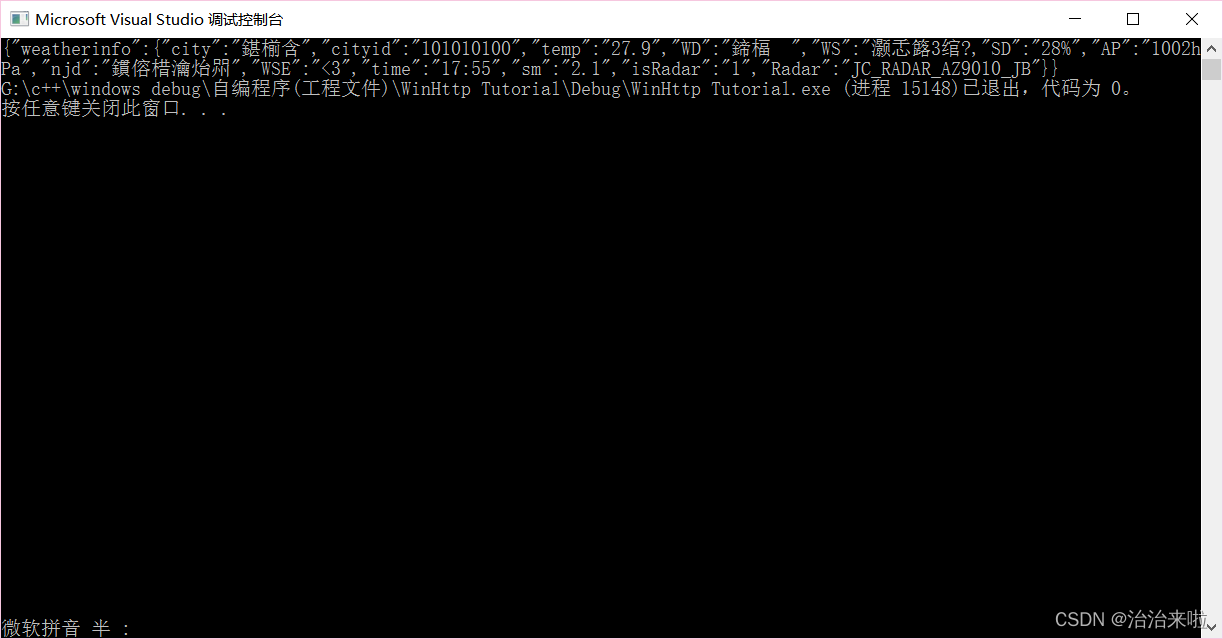
例如下面这个是访问一个天气接口(http://www.weather.com.cn/data/sk/101010100.html)的请求头内容:
GET /data/sk/101010100.html HTTP/1.1
Host: www.weather.com.cn
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7(大家一定要注意其中的空格和换行,都是非常重要的)
第一行内容为请求行,内容包括:请求方式(GET)——请求有很多种,不同的请求对应着不同的功能,例如还有POST,PUT,OPTION等,自己可以具体查阅以下“http请求类型”,访问资源(/data/sk/101010100.html),http协议的版本(HTTP/1.1)——其他还有1.0版本,不过现在大多都1.1版本了。
下一行叫做请求头,请求头的格式为:“字段: 值”
第一个字段(首次出现这个名词哦,认真记)是 “Host”,后面的值是域名(有时候也叫做主机地址,主机ip地址等名字)。后面的几行都是http的头部字段以及对应的字段值,例如:Connection字段表示连接方式,User-Agent表示请求发起者的类型(这个请求是电脑发出的,里面就包含windows,如果是手机可能是android等内容),具体其他各个字段什么意思可以自己查阅以下。
所有的请求头结束后需要有一行空行表示请求头的内容发送结束了!(这个很重要哦)
POST请求
这个请求大部分和上面的一样,一点点小差异哦。
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alivename=Professional%20Ajax&publisher=WileyPOST请求主要用于向服务器上传消息。和上面的GET请求相比可以发现,请求头里面多了一个叫做Content-Length字段,表示请求头后面数据的长度,单位是字节(必须和后面发送的数据量长度保持一致,如果不一致的话,额,我也不知道有什么问题,自己看看吧)。
消息主体(也叫请求数据)和http请求头(就是上面的一团内容)之间必须要有一行空行来分隔开。消息主体即:“name=Professional%20Ajax&publisher=Wiley”。
响应消息Response
响应消息主要包含四部分:状态行、消息报头、空行和响应正文。这是那个天气网站的响应消息,我把它贴过来。
HTTP/1.1 200 OK
Date: Thu, 17 Mar 2022 10:54:48 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
Server: openresty
Age: 3867717
X-CCDN-CacheTTL: 2592000
X-Xss-Protection: 1
nginx-hit: 1
via: CHN-GDguangzhou-CMCC7-CACHE11[2],CHN-GDguangzhou-CMCC7-CACHE59[0,TCP_HIT,0],CHN-SH-GLOBAL1-CACHE37[23],CHN-SH-GLOBAL1-CACHE76[0,TCP_HIT,22]
x-hcs-proxy-type: 1
Content-Encoding: gzip{"weatherinfo":{"city":"北京","cityid":"101010100","temp":"27.9","WD":"南风","WS":"小于3级","SD":"28%","AP":"1002hPa","njd":"暂无实况","WSE":"<3","time":"17:55","sm":"2.1","isRadar":"1","Radar":"JC_RADAR_AZ9010_JB"}}其中状态行包括:http协议版本号(HTTP/1.1),状态码(200),状态消息(OK)。其中状态码有很多,常用的有:101(主要用于升级协议,后面会讲到),200(正确处理请求),301/302(重定向),404(找不到访问的url)。
下面的空行之间的内容是消息报头,和请求头的格式一样,但是字段内容有差异,具体含义自己可以查阅资料深入了解。隔一个空行后面是服务器返回的真正内容(本例子返回的是北京城市的天气信息)。
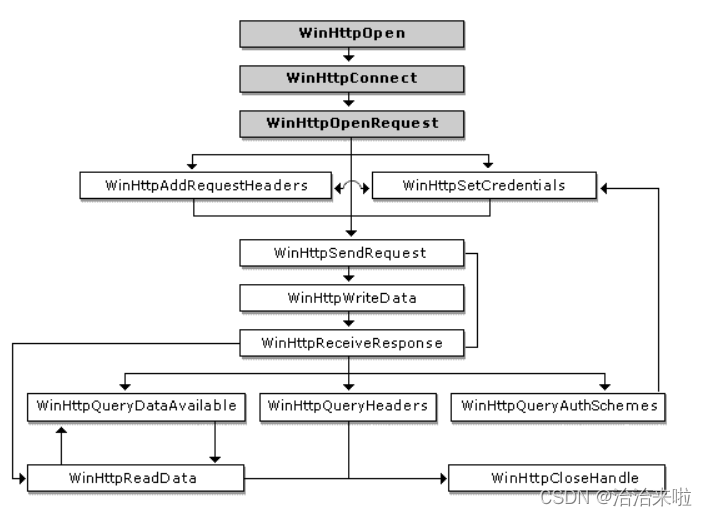
二、WinHttp函数的官方介绍
官方的document地址:Using WinHTTP - Win32 apps | Microsoft Docs
为了防止由于时间等不可控因素导致的在线文档不可以使用,此处放一个百度网盘的地址:
链接:https://pan.baidu.com/s/1wkhV4rGj_AGrNygVsNy2Sg
提取码:w7ux
注意事项:
1. 使用工程需要包含的头文件以及静态库如下:
控制台程序的头文件包含(注意先后顺序也别弄错):
#include <iostream>
#include <windows.h>
#include <winhttp.h>
#include <websocket.h>
#pragma comment(lib, "Websocket.lib")
#pragma comment(lib, "winhttp.lib")
using namespace std;
2. 注意如果出现无法找到相关头文件,需要重定向一下目标方案,我用的是vs2019。
3. 如何能够看到我们的发送请求的内容呢,需要安装一个叫做fidder的程序,是个免费的程序,挺好使的。
Fiddler | Web Debugging Proxy and Troubleshooting Solutions
WinHttp SessionWinHTTP Sessions Overview - Win32 apps | Microsoft Docs
我们用来测试的网站是:http://www.weather.com.cn/data/sk/101010100.html
其中需要修改的地方有几处:
1. 增加宏定义作为发起http请求头的USER-AGENT字段内容(不修改服务器可能不会相应你的请求):
#define CHROME_USER_AGENT TEXT("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36")
2. 修改代码中部分内容
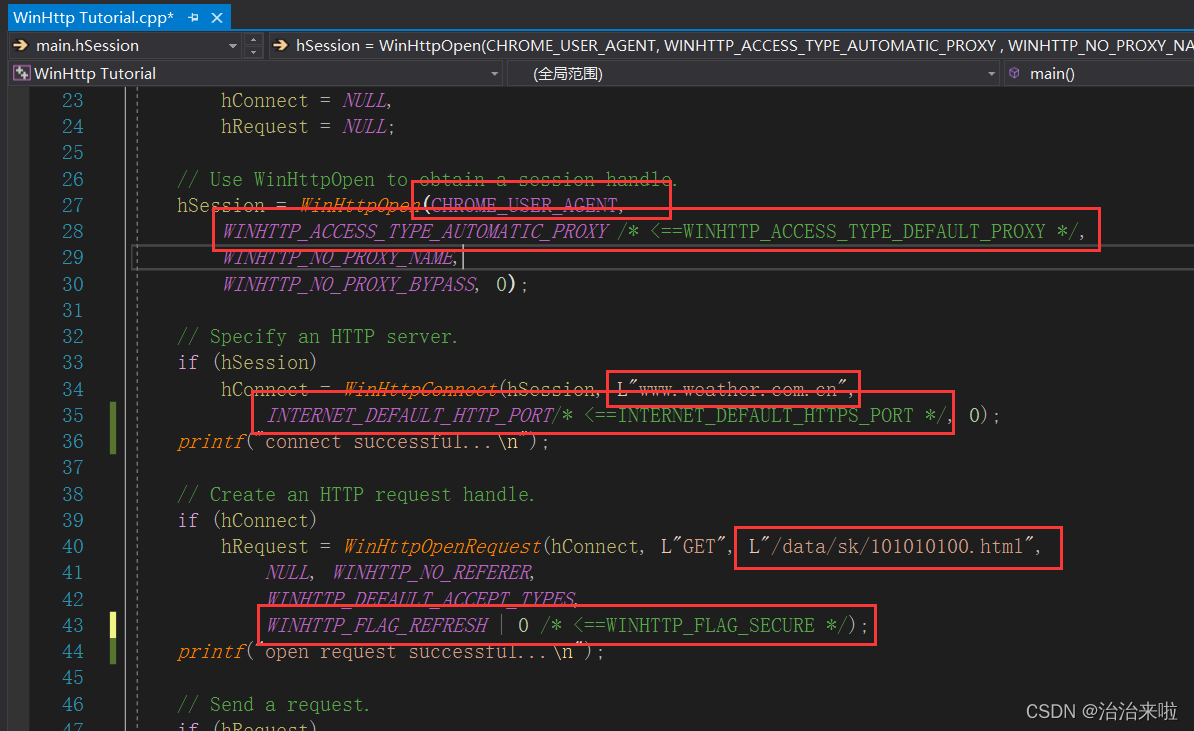
效果:
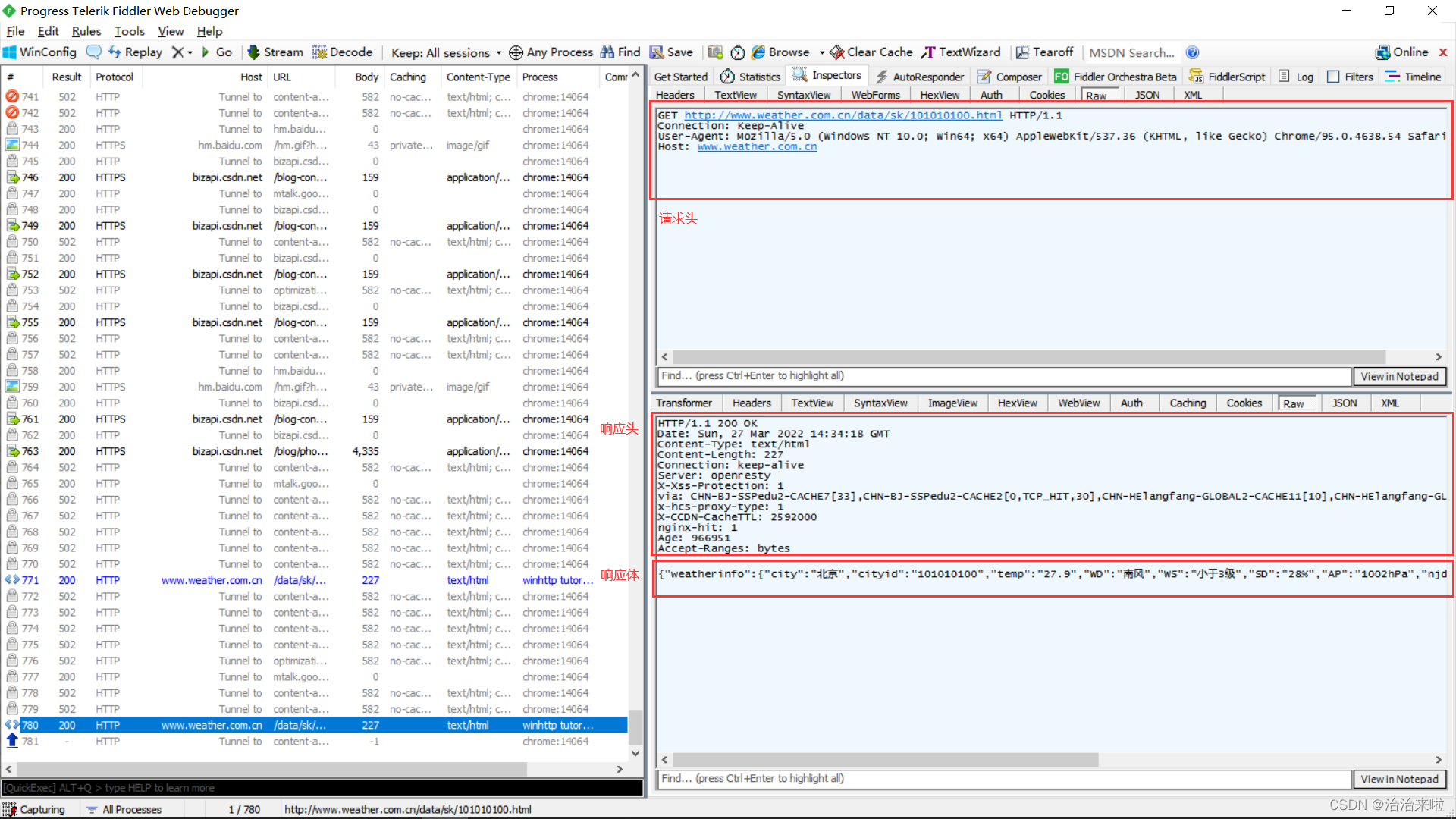
URL的拆分和构建Uniform Resource Locators (URLs) in WinHTTP - Win32 apps | Microsoft Docs
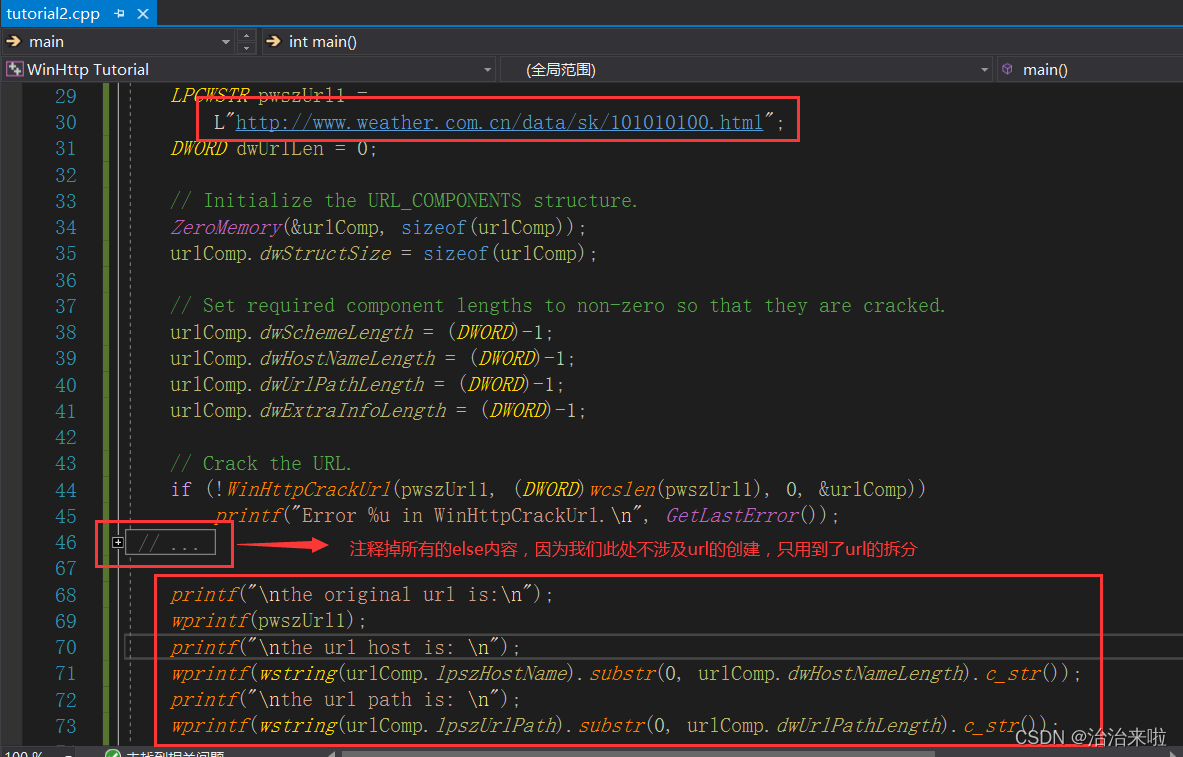
注意方框的内容是我修改的内容,运行结果:
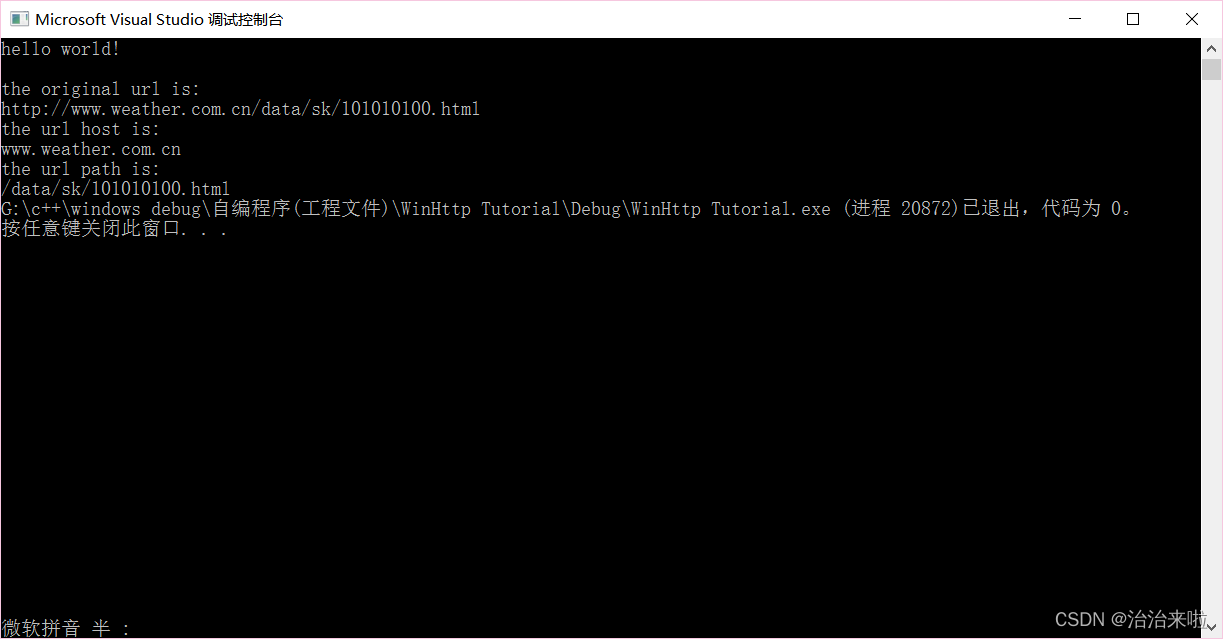
现在我们就完成了url的拆分了,接下来看看怎么用这个拆分结果:
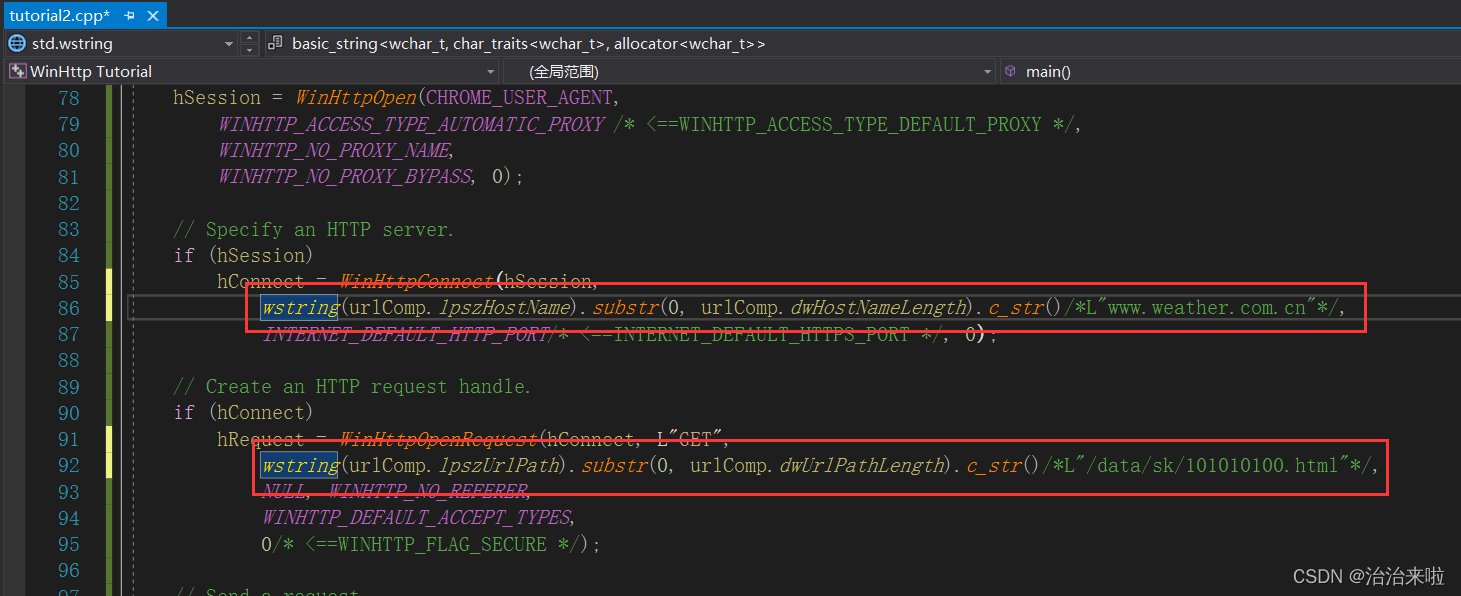
,再次运行是不是发现也可以跑呢,现在可以把那个url换成随意的url都可以自动拆分了,是不是很方便呢,ok,我们接着往下走!
http相应的编码转换
改变数据接收的逻辑,自己处理接收数据的内存空间分配
部分重点函数说明:
WinHttpReceiveResponseWinHttpReceiveResponse function (winhttp.h) - Win32 apps | Microsoft Docs
WinHttpQueryDataAvailableWinHttpQueryDataAvailable function (winhttp.h) - Win32 apps | Microsoft Docs
修改接收消息的部分细节逻辑:
主要利用vector来进行内存管理,关于vector的具体用法及函数介绍,参见:vector 类 | Microsoft Docs
修改的代码内容为:
#include <iostream>
#include <windows.h>
#include <winhttp.h>
#include <websocket.h>
#include <vector>#pragma comment(lib, "Websocket.lib")
#pragma comment(lib, "winhttp.lib")
using namespace std;#define CHROME_USER_AGENT TEXT("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36")int main()
{//http://www.weather.com.cn/data/sk/101010100.htmlDWORD dwSize = 0;DWORD dwDownloaded = 0;LPSTR pszOutBuffer;BOOL bResults = FALSE;HINTERNET hSession = NULL,hConnect = NULL,hRequest = NULL;// Use WinHttpOpen to obtain a session handle.hSession = WinHttpOpen(CHROME_USER_AGENT,WINHTTP_ACCESS_TYPE_AUTOMATIC_PROXY /* <==WINHTTP_ACCESS_TYPE_DEFAULT_PROXY */,WINHTTP_NO_PROXY_NAME,WINHTTP_NO_PROXY_BYPASS, 0);// Specify an HTTP server.if (hSession)hConnect = WinHttpConnect(hSession, L"www.weather.com.cn"/*www.weather.com.cn*/,INTERNET_DEFAULT_HTTP_PORT/* <==INTERNET_DEFAULT_HTTPS_PORT */, 0);printf("connect successful...\n");// Create an HTTP request handle.if (hConnect)hRequest = WinHttpOpenRequest(hConnect, L"GET", L"/weather/101030100.shtml"/*/data/sk/101010100.html*/,NULL, WINHTTP_NO_REFERER,WINHTTP_DEFAULT_ACCEPT_TYPES,WINHTTP_FLAG_REFRESH | 0 /* <==WINHTTP_FLAG_SECURE */);printf("open request successful...\n");// Send a request.if (hRequest)bResults = WinHttpSendRequest(hRequest,WINHTTP_NO_ADDITIONAL_HEADERS, 0,WINHTTP_NO_REQUEST_DATA, 0,0, 0);printf("send request successful...\n");// End the request.if (bResults)bResults = WinHttpReceiveResponse(hRequest, NULL);printf("response received...\n");//create the buffer to store the data receivedvector<BYTE> bufferReceive; int iDataReceive;//作为区域的终止字符bufferReceive.resize(1);iDataReceive = 0;// Keep checking for data until there is nothing left.if (bResults){do{// Check for available data.dwSize = 0;if (!WinHttpQueryDataAvailable(hRequest, &dwSize))printf("Error %u in WinHttpQueryDataAvailable.\n",GetLastError());//=========================== new code here ===============================// Allocate space for the buffer.pszOutBuffer = new char[dwSize + 1];if (!pszOutBuffer){printf("Out of memory\n");dwSize = 0;}else{// Read the data.ZeroMemory(pszOutBuffer, dwSize + 1);if (!WinHttpReadData(hRequest, (LPVOID)pszOutBuffer,dwSize, &dwDownloaded))printf("Error %u in WinHttpReadData.\n", GetLastError());else{//Here we can record how many times this is calledprintf("\nreceiving the data...\n");
// printf("%s", pszOutBuffer);bufferReceive.resize(bufferReceive.size() + dwDownloaded);CopyMemory(&bufferReceive[iDataReceive] , pszOutBuffer, dwDownloaded);iDataReceive += dwDownloaded;} // Free the memory allocated to the buffer.delete[] pszOutBuffer;}//===========================================================================//========================== original code here ==========================// // Allocate space for the buffer.
// pszOutBuffer = new char[dwSize + 1];
// if (!pszOutBuffer)
// {
// printf("Out of memory\n");
// dwSize = 0;
// }
// else
// {
// // Read the data.
// ZeroMemory(pszOutBuffer, dwSize + 1);
//
// if (!WinHttpReadData(hRequest, (LPVOID)pszOutBuffer,
// dwSize, &dwDownloaded))
// printf("Error %u in WinHttpReadData.\n", GetLastError());
// else
// printf("%s", pszOutBuffer);
//
// // Free the memory allocated to the buffer.
// delete[] pszOutBuffer;
// }
// //========================================================================} while (dwSize > 0);}//print all the data receivedprintf("\nall data received are as follows: \n");printf("%s", &bufferReceive.front());printf("\nrequest completed!\n");// Report any errors.if (!bResults)printf("Error %d has occurred.\n", GetLastError());// Close any open handles.if (hRequest) WinHttpCloseHandle(hRequest);if (hConnect) WinHttpCloseHandle(hConnect);if (hSession) WinHttpCloseHandle(hSession);
}修改后的效果:
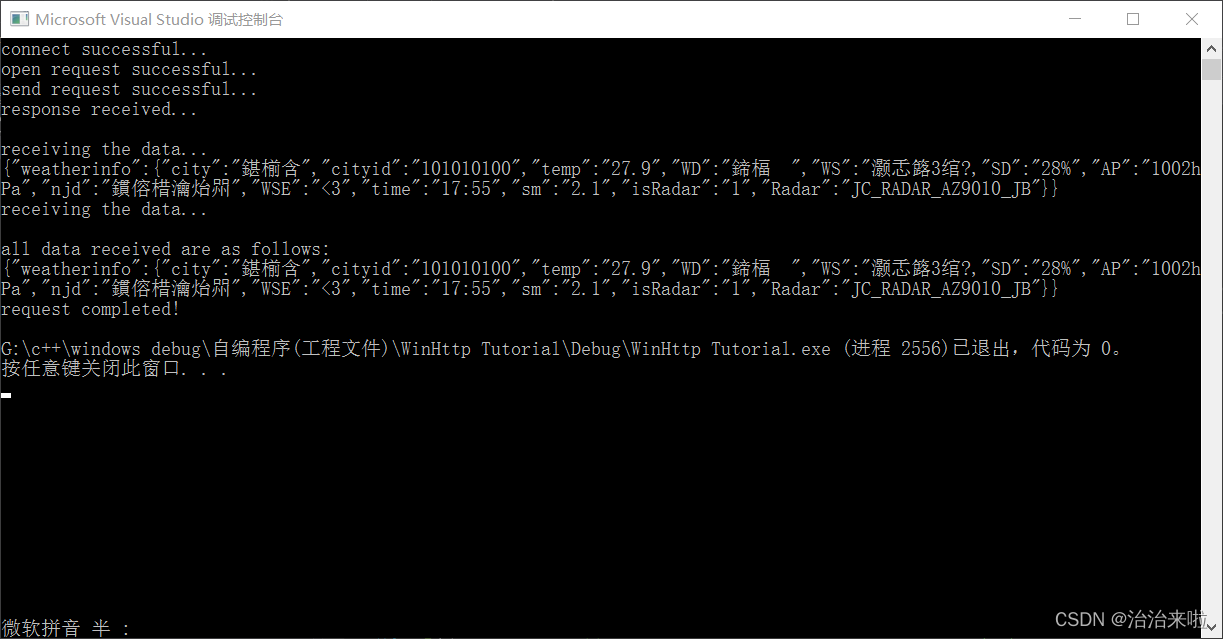
ok,现在我们换一个网站再来测试一下你就可以更加清晰的看出来效果了,这个网站由于数据量比较少,所以客户端一次便接收完成了。修改代码中的如下位置内容(访问链接为:http://www.weather.com.cn/weather/101030100.shtml):
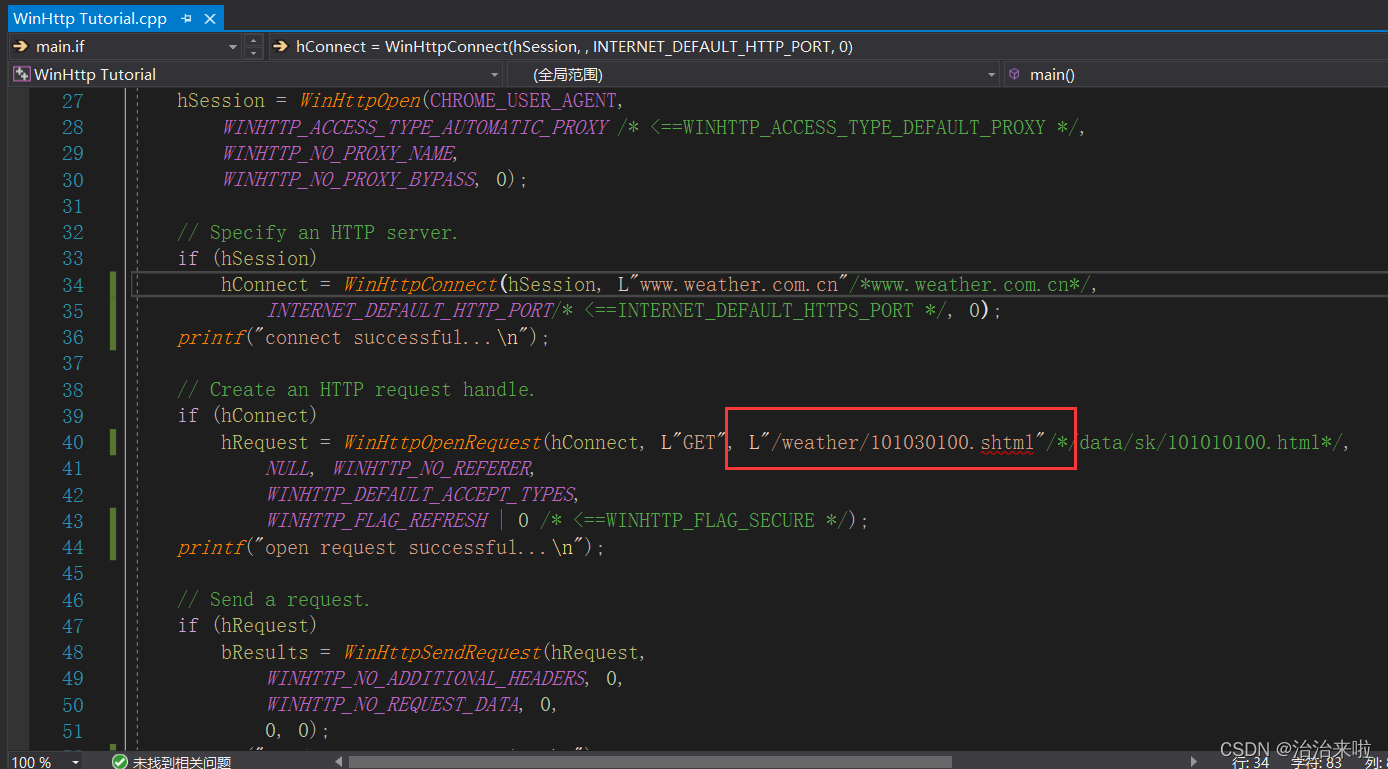
效果为:
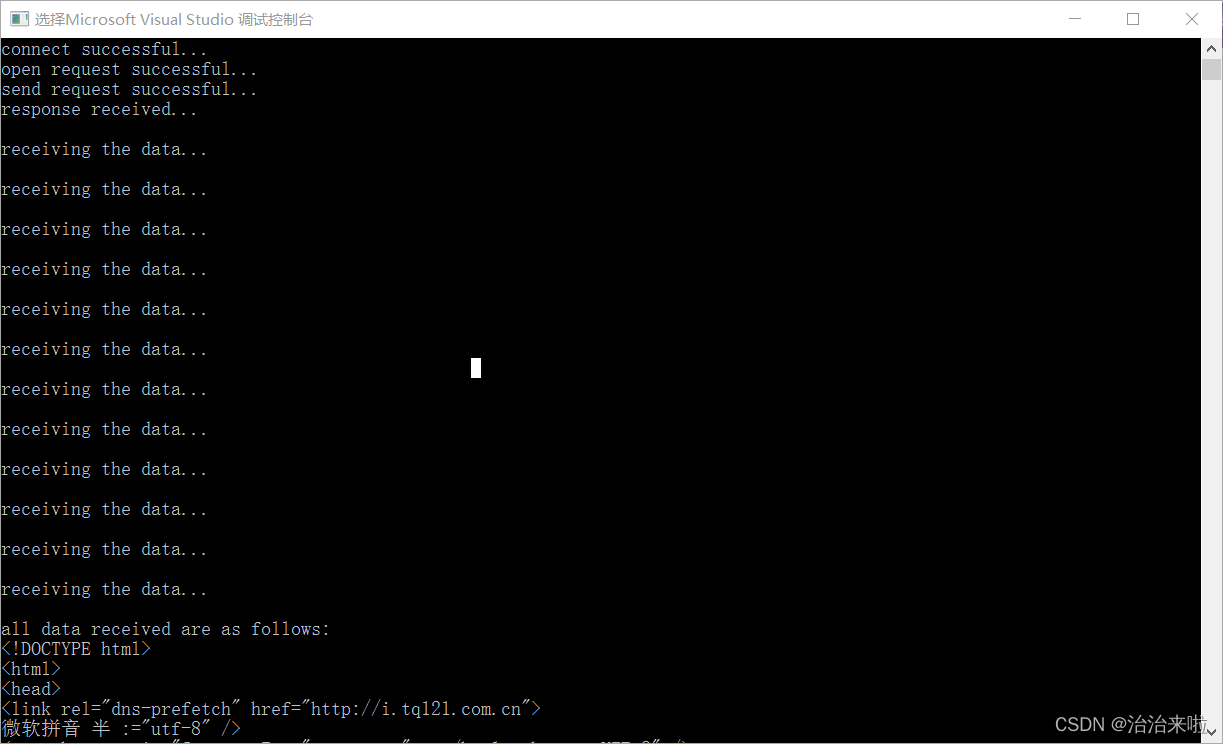
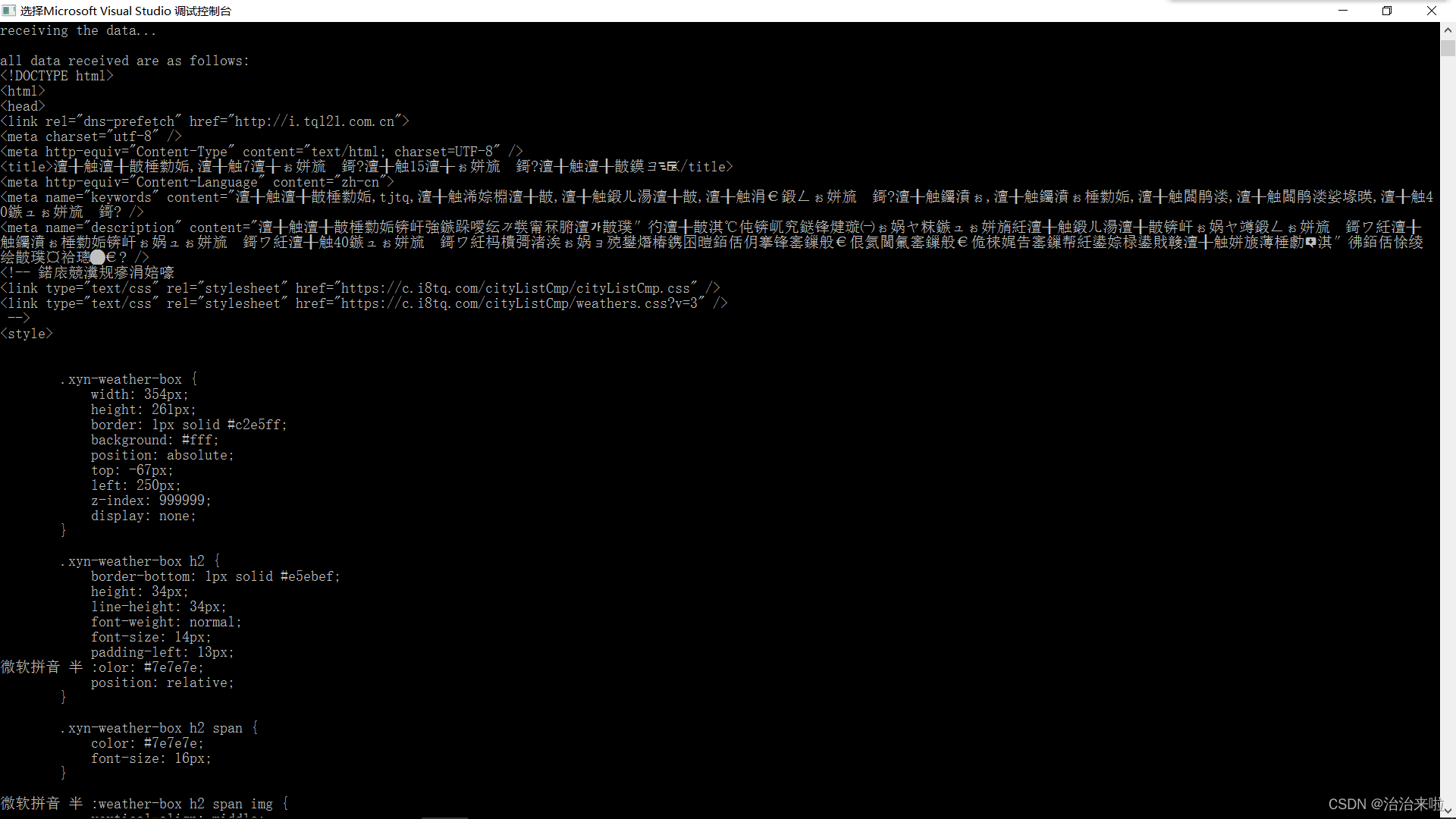
这里我们可以很明显的看出来,多次打印了receiving the data...内容,表明所有的内容并非一次读取完成,如果我们不能够很好的处理内存的话我们是无法很好的处理整个内容的编码解码操作的。(因为可能会由于部分文本接收不完整导致编码解码出现乱码)
关于内存操作的其他方法简介:
new 和 delete 的搭配使用(利用BYTE申请空间)
操作内存块的相关函数
ZeroMemory:ZeroMemory macro (Windows) | Microsoft Docs,
CopyMemory:CopyMemory function (Windows) | Microsoft Docs,
memset:memset | Microsoft Docs,
memcopy:memcpy, wmemcpy | Microsoft Docs)
前面已经用到,此处不具体讲解。
数据的编码转换
下面的内容,我不太想告诉你细节问题,因为这个东西听起来会很无聊,如果你是在特别特别想知道细节的话,那么你可以自己去查一查相关的资料哈哈哈哈哈,我不要讲这种东西,因为网络上好多这种编码解码都是错误的,当初摸索了好久真的是。
UNICODE ==> UTF8 or ANSI
string UnicodeToUTF8(wstring src)
{string sUTF8;int iLenBytes = 0;// 获得结果字符串所需字符个数,参数 -1 使函数自动计算 szUnicode 的长度iLenBytes = WideCharToMultiByte(CP_UTF8, 0, src.c_str(), -1, NULL, 0, NULL, NULL);// 分配结果字符串的空间sUTF8.resize(iLenBytes);// 转换:用 aLenBytes 因函数需要的是字节数非字符数WideCharToMultiByte(CP_UTF8, 0, src.c_str(), -1, (LPSTR)sUTF8.c_str(), iLenBytes, NULL, NULL);return sUTF8;
}
string UnicodeToANSI(wstring src)
{string sUTF8;int iLenBytes = 0;// 获得结果字符串所需字符个数,参数 -1 使函数自动计算 szUnicode 的长度iLenBytes = WideCharToMultiByte(CP_ACP, 0, src.c_str(), -1, NULL, 0, NULL, NULL);// 分配结果字符串的空间sUTF8.resize(iLenBytes);// 转换:用 aLenBytes 因函数需要的是字节数非字符数WideCharToMultiByte(CP_ACP, 0, src.c_str(), -1, (LPSTR)sUTF8.c_str(), iLenBytes, NULL, NULL);return sUTF8;
}UTF8 or ANSI ==> UNICODE
wstring UTF8ToUnicode(string src)
{wstring sUnicode;int iLen = 0;// 获得结果字符串所需字符个数,参数 -1 使函数自动计算 szAnsi 的长度iLen = MultiByteToWideChar(CP_UTF8, 0, src.c_str(), -1, NULL, 0);// 分配结果字符串的空间sUnicode.resize(iLen + 1);// 转换MultiByteToWideChar(CP_UTF8, 0, src.c_str(), -1, (LPWSTR)sUnicode.c_str(), iLen);sUnicode[iLen] = '\0';return sUnicode;
}
wstring ANSIToUnicode(string src)
{wstring sUnicode;int iLen = 0;// 获得结果字符串所需字符个数,参数 -1 使函数自动计算 szAnsi 的长度iLen = MultiByteToWideChar(CP_ACP, 0, src.c_str(), -1, NULL, 0);// 分配结果字符串的空间sUnicode.resize(iLen + 1);// 转换MultiByteToWideChar(CP_ACP, 0, src.c_str(), -1, (LPWSTR)sUnicode.c_str(), iLen);sUnicode[iLen] = '\0';return sUnicode;
}string <==> wstring
wstring stringTowstring(string src)
{return ANSIToUnicode(src);
}
string wstringTostring(wstring src)
{return UnicodeToANSI(src);
}url编码解码
unsigned char CharToHex(unsigned char x) {return (unsigned char)(x > 9 ? x + 55 : x + 48);
}
string UrlEncode(const string src)
{string str_encode;unsigned char* p = (unsigned char*)src.c_str();unsigned char ch;while (*p) {ch = (unsigned char)*p;if (*p == ' '){str_encode += '+';}else if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || (ch >= '0' && ch <= '9')/*IsAlphaNumber(ch)*/ || strchr("-_.~!*'();:@&=+$,?#", ch)) //其中 /[] 字符被去掉{str_encode += *p;}else{str_encode += '%';str_encode += CharToHex((unsigned char)(ch >> 4));str_encode += CharToHex((unsigned char)(ch % 16));}++p;}return str_encode;
}
string UrlDecode(const string src)
{string str_decode;int i;char* cd = (char*)src.c_str();char p[2];for (i = 0; i < (int)strlen(cd); i++) {memset(p, '\0', 2);if (cd[i] != '%') {str_decode += cd[i];continue;}p[0] = cd[++i];p[1] = cd[++i];p[0] = p[0] - 48 - ((p[0] >= 'A') ? 7 : 0) - ((p[0] >= 'a') ? 32 : 0);p[1] = p[1] - 48 - ((p[1] >= 'A') ? 7 : 0) - ((p[1] >= 'a') ? 32 : 0);str_decode += (unsigned char)(p[0] * 16 + p[1]);}return str_decode;
}解码测试
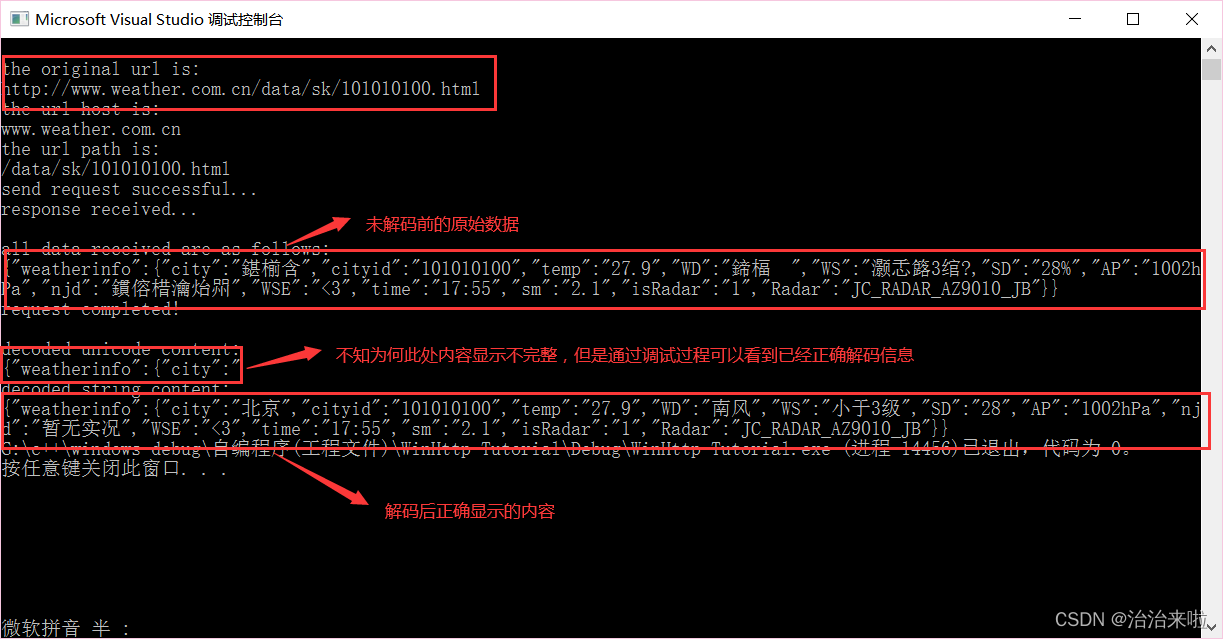
ok,我们把访问链接改为最原始的那个:http://www.weather.com.cn/data/sk/101010100.html,然后加入如下的代码:
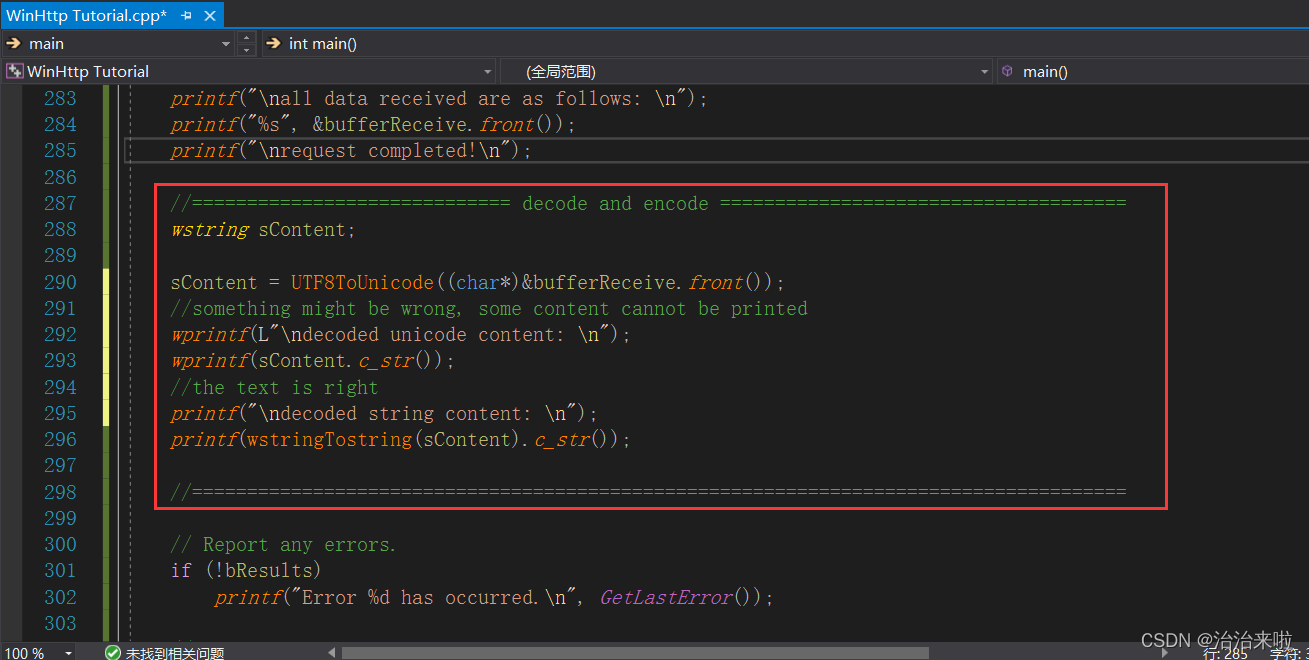
效果:
json数据的编码转换
下图是实际的需要接送解析的文件内容,文件下载地址为:
http://open-source-parsers.github.io/jsoncpp-docs/doxygen/index.html,具体下载地址在这里:
当然写代码的最怕这种代码升级,修改后就容易出现不兼容的情况,所以我也自己在百度网盘留存了一份内容:
链接:https://pan.baidu.com/s/1M23KcAa7D-fg3IW4x5lk9Q
提取码:n543
下载添加完路径后便可以使用改代码了,为了测试功能特意编写如下代码:
#include <iostream>
#include <fstream>
#include "json/json.h"using namespace std;
using namespace Json;int main()
{//读取 json 文件//对简单 json 文件内容解析//对复杂的 json 格式文件进行解析cout << "hello, world!\n";//===================================== 解析文件中的json数据 ===============================cout << "the data here are the json parsed from file stream\n";Reader a;Value root;Value data1;ifstream fileStream;CharReaderBuilder builder;fileStream.open("F:\\test.json");builder["collectComments"] = true;JSONCPP_STRING errs;if (!parseFromStream(builder, fileStream, &root, &errs)) {cout << errs << endl;return EXIT_FAILURE;}cout << root << endl;FastWriter w;String str = w.write(root["programmers"]);Reader readerSubData;if (readerSubData.parse(str.substr(1, str.length()-1), data1)){cout << data1["firstName"] << endl;}else{cout << "parse data wrong\n";return EXIT_FAILURE;}//===================================== 解析json字符串 ========================================cout << "the data here are the json parsed from the json format string\n\n";string rawJson = R"({ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" })";Reader rawReader;Value root2;rawReader.parse(rawJson, root2);cout << root2 << endl;cout << "firstName: " << root2["firstName"].asString() << endl;//========================================== 将json数据转换为对应的字符串 ==========================Value root3;Value data;FastWriter writer;data["snack"] = "icecream";data["location"] = "TJU";root3["firstName"] = "zwb";root3["subJsonData"] = data;cout << writer.write(root3) << endl;return EXIT_SUCCESS;
}获取http请求头的信息
WinHttpQueryHeaders:WinHttpQueryHeaders function (winhttp.h) - Win32 apps | Microsoft Docs
三、实现自己的WinHttp class
Winhttp的更多用法扩展
如何使用Https
如何设置请求的代理服务器
如何设置winHttp函数的更多参数
异步实现WinHttp Session
回调函数
异步实现winhttp首先应该了解的一个内容便是回调函数,回调函数指的是该函数会在合适的时候由系统调用执行,但是在此之前我们应该设置好回调函数的指针。
函数指针
大家可能最熟悉的是字符串指针,函数指针和字符串指针类似,他指向的是一个函数的地址,由于C++是一个强类型的语言。对于函数而言,不同的函数指针不能复用。
不同的函数首先来讲函数参数不同,函数返回值不同。因此定义函数指针必须要注意这两个地方。例如我们要定义一个参数为 int, double 类型,返回值为 bool 的函数指针,那么我们应该按照如下的方式来写对应的代码:
。。。(等我有时间补上)
在 winhttp 中设置回调函数是通过 WinHttpSetStatusCallback 来设置的,该函数的官网说明如下:
WINHTTPAPI WINHTTP_STATUS_CALLBACK WinHttpSetStatusCallback(
[in] HINTERNET hInternet,
[in] WINHTTP_STATUS_CALLBACK lpfnInternetCallback,
[in] DWORD dwNotificationFlags,
[in] DWORD_PTR dwReserved
);参数说明:
hInternet 该参数表示的是哪个句柄的事件,通常应该设置为???
lpfnInternetCallback 回调函数的地址
dwNotificationFlags 通知事件的种类,通常设置为WINHTTP_CALLBACK_FLAG_ALL_COMPLETIONS,关于其他的 flag 种类,自行对比官网介绍
dwReserved 保留参数,,必须是null
返回内容:
如果之前设置过回调函数地址,返回内容为现在替换的之前的回调函数地址,如果没有,返回null
tips:
如果要清除现在的回调函数地址,那么只需要将新的回调函数地址设置为null即可。