目录
- 背景:
- B/S架构:
- 静态资源:
- 动态资源:
- Tomcat:
- Maven创建Web项目:
- 使用骨架:
- Tomcat Maven插件
- Servlet
- Servlet 执行流程
- Servlet 生命周期
- urlPattern配置
- Request
- 请求参数
- 中文乱码解决方案
- 请求转发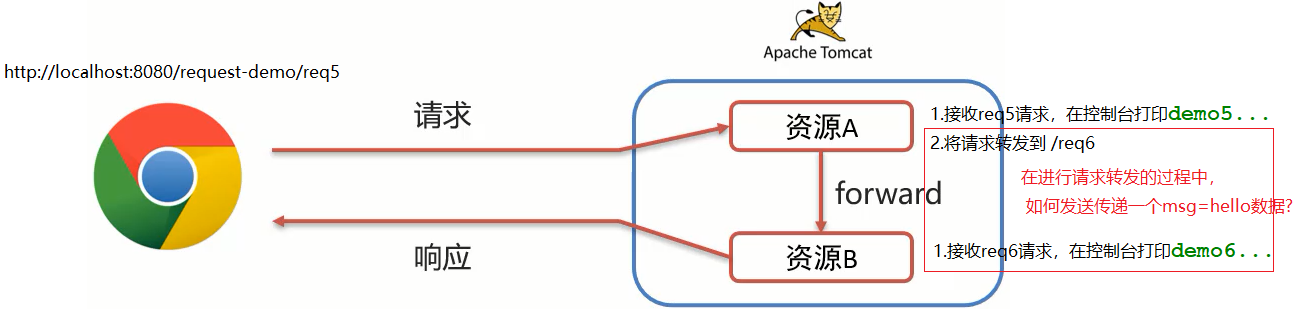
- 请求重定向
- 路径问题
- Response响应字符数据
- Response响应字节数据
背景:
B/S架构:
Browser/Server,浏览器/服务器 架构模式,它的特点是,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web资源,服务器把Web资源发送给浏览器即可。

资源分两种:静态资源和动态资源
静态资源:
静态资源主要包含HTML、CSS、JavaScript、图片等,主要负责页面的展示。
动态资源:
动态资源主要包含Servlet、JSP等,主要用来负责逻辑处理。

HTTP规定了浏览器和服务器之间数据传输的规则。(现在HTTP不用编写,而是直接用web服务器)
Tomcat:
Tomcat是Web服务器,对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作,让Web开发更加便捷。
Maven创建Web项目:
使用骨架:
- 创建Maven项目
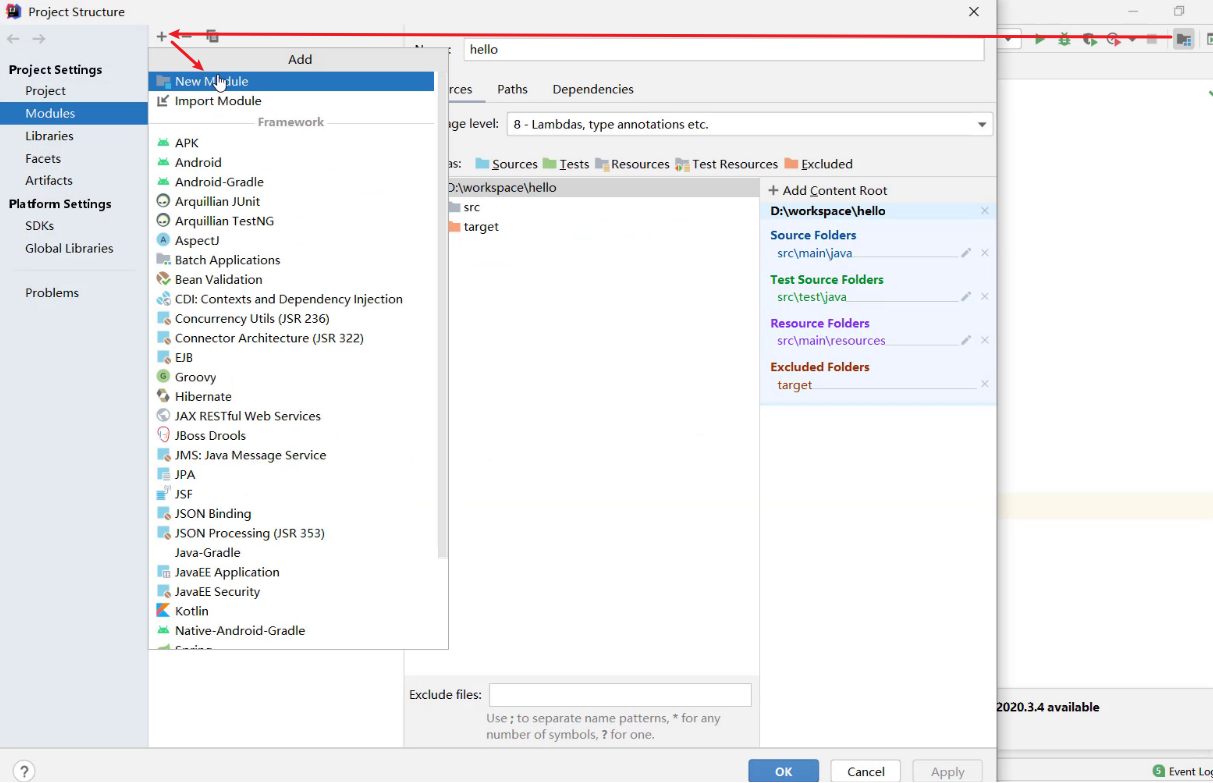
- 选择使用Web项目骨架
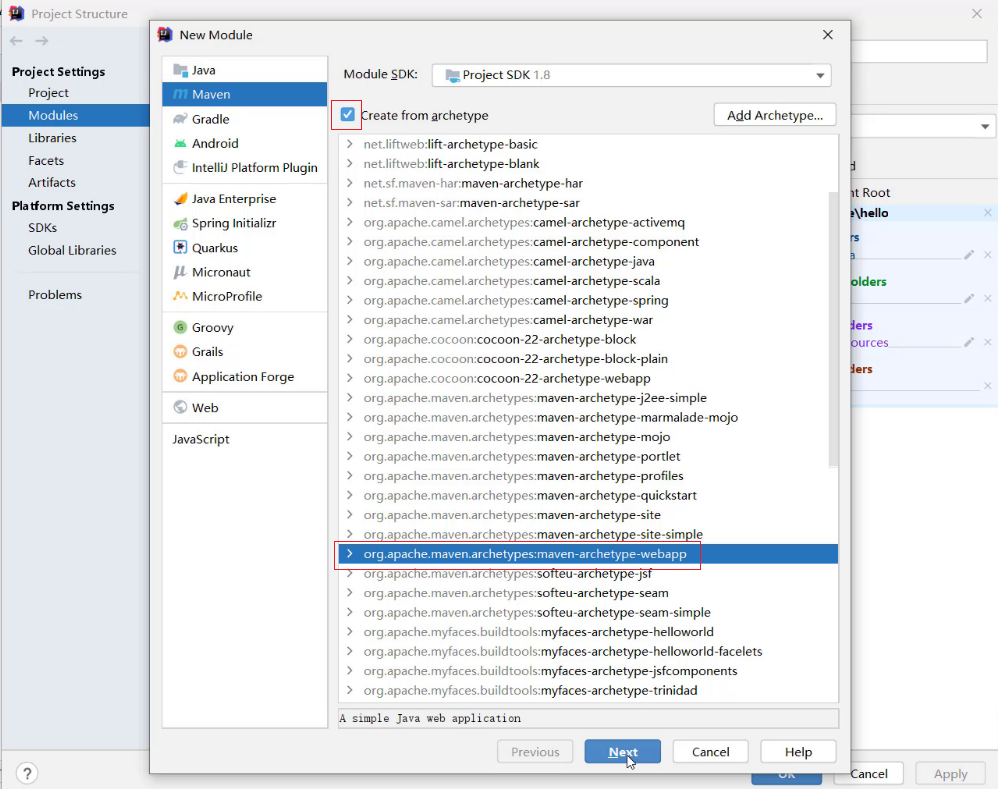
- 输入Maven项目坐标创建项目
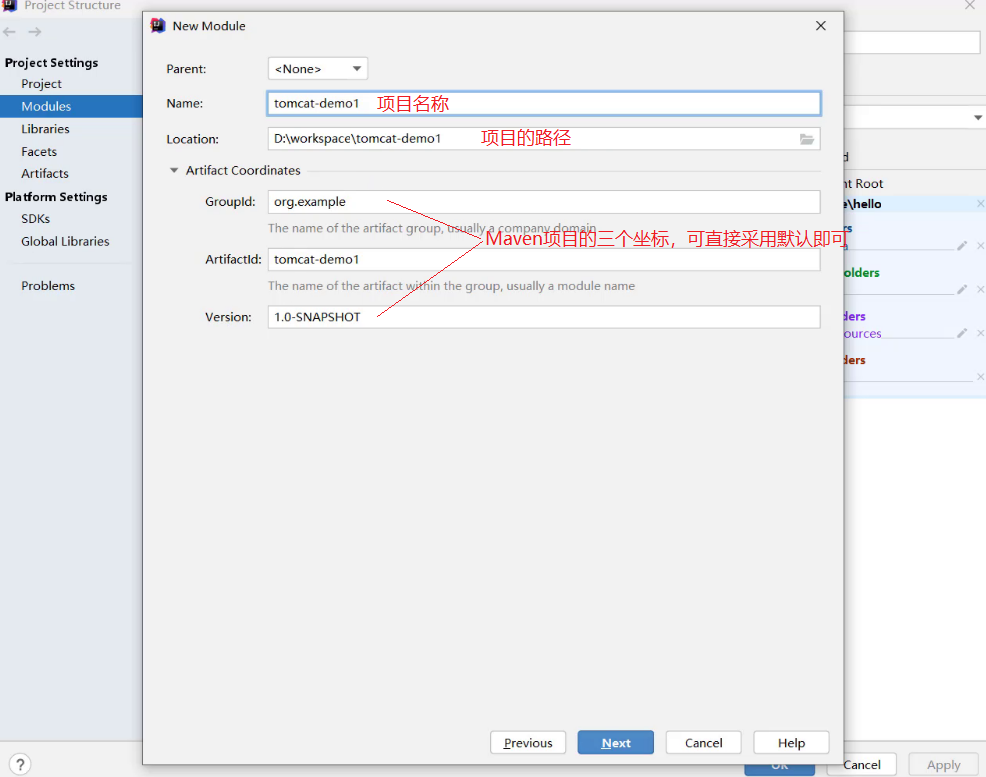
- 确认Maven相关的配置信息后,完成项目创建
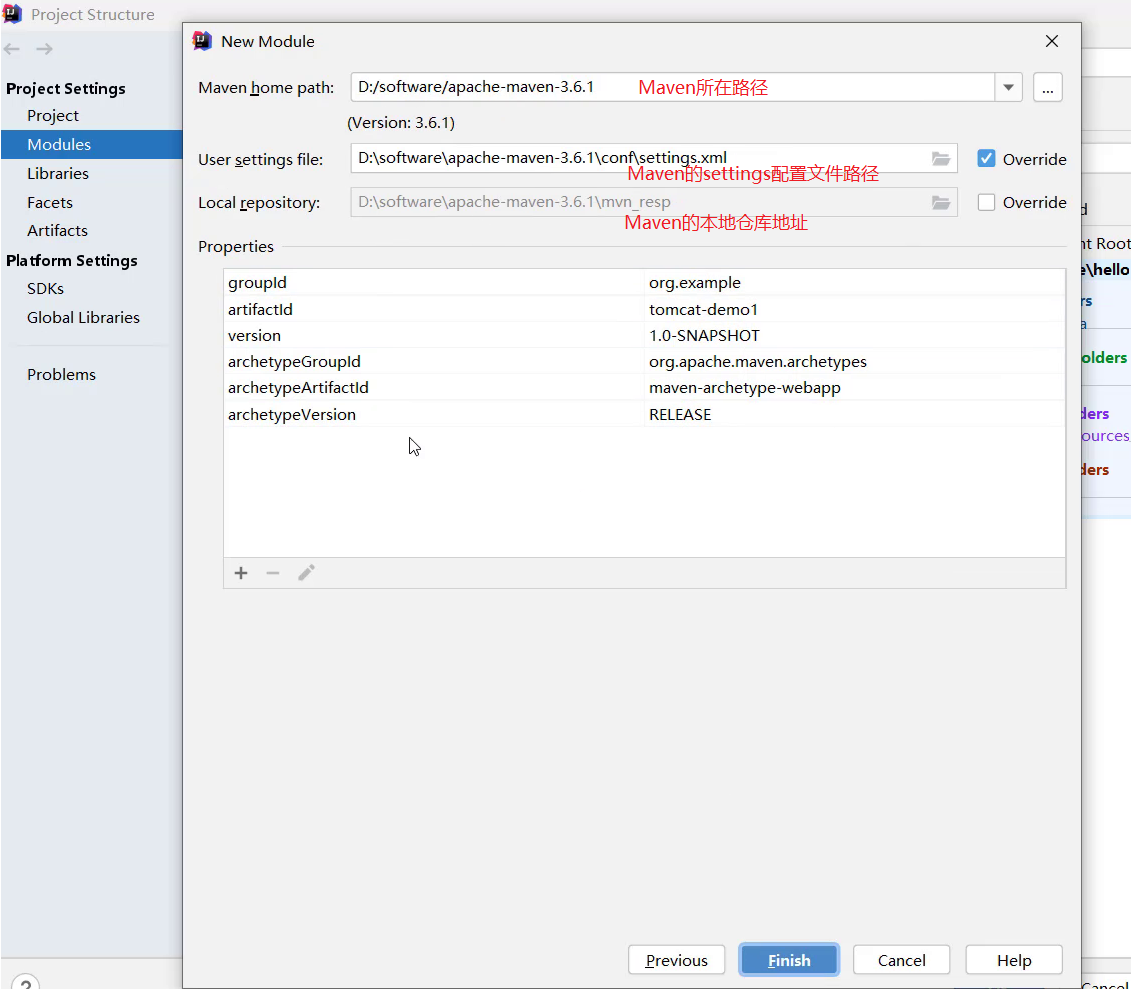
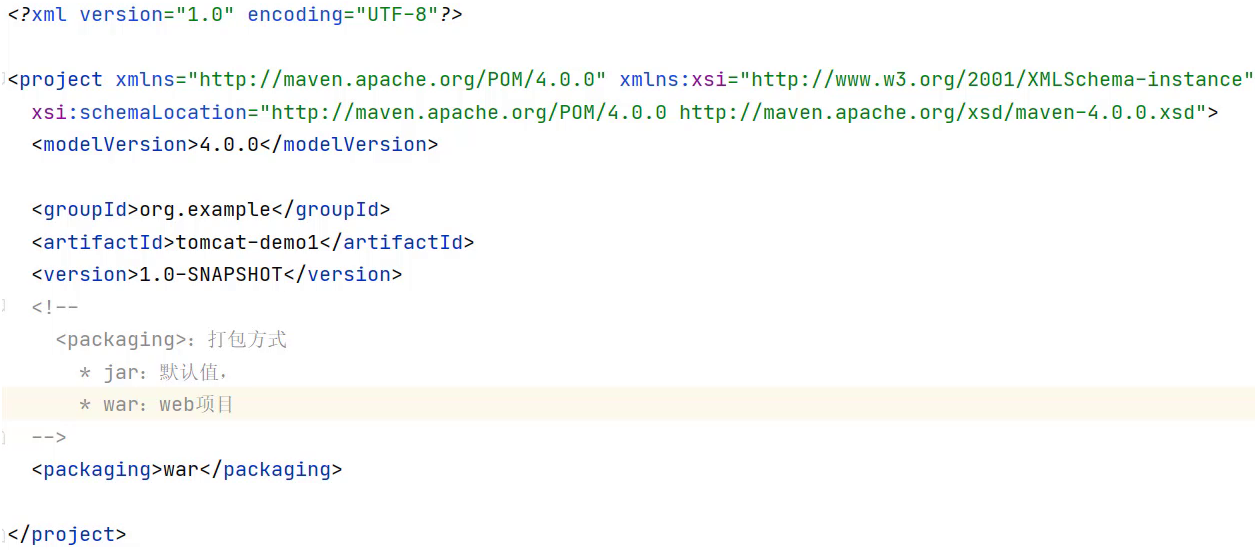
- 删除pom.xml中多余内容,只留下面的这些内容,注意打包方式 jar和war的区别
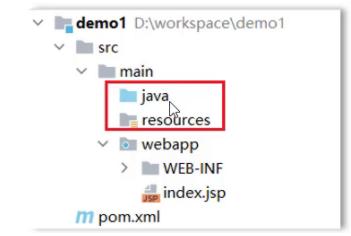
- 补齐Maven Web项目缺失的目录结构,默认没有java和resources目录,需要手动完成创建补齐,最终的目录结果如下
Tomcat Maven插件
在IDEA中使用本地Tomcat进行项目部署,相对来说步骤比较繁琐,所以我们直接使用Maven中的Tomcat插件来部署项目
-
在pom.xml中添加Tomcat插件
<build><plugins><!--Tomcat插件 --><plugin><groupId>org.apache.tomcat.maven</groupId><artifactId>tomcat7-maven-plugin</artifactId><version>2.2</version></plugin></plugins> </build> -
使用Maven Helper插件快速启动项目,选中项目,右键–>Run Maven --> tomcat7:run

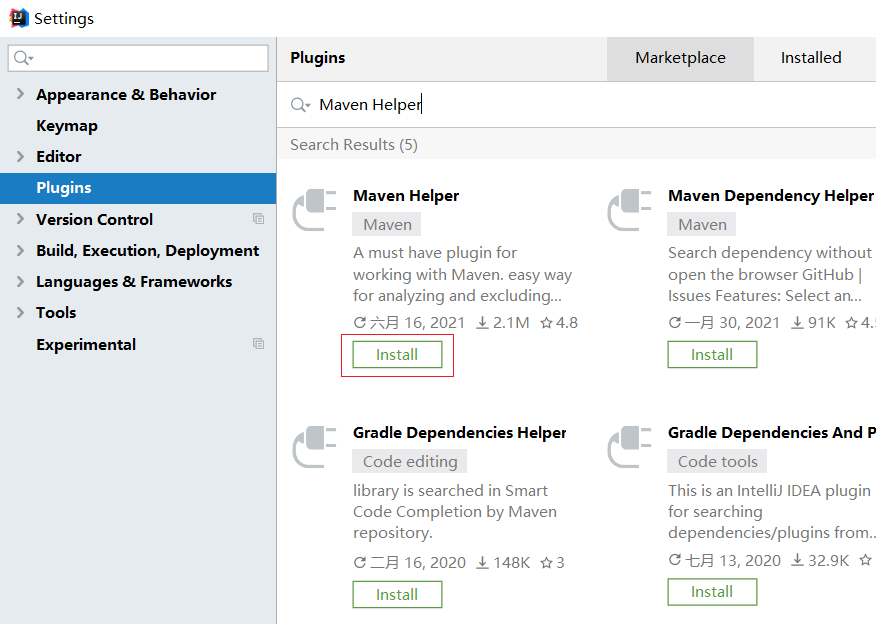
注意:
如果选中项目并右键点击后,看不到Run Maven和Debug Maven,这个时候就需要在IDEA中下载Maven Helper插件,具体的操作方式为: File --> Settings --> Plugins --> Maven Helper —> Install,安装完后按照提示重启IDEA,就可以看到了。
Servlet
-
Servlet是JavaWeb最为核心的内容,它是Java提供的一门动态web资源开发技术。
-
使用Servlet就可以实现,根据不同的登录用户在页面上动态显示不同内容。
-
Servlet是JavaEE规范之一,其实就是一个接口,将来我们需要定义Servlet类实现Servlet接口,并由web服务器运行Servlet
Servlet 执行流程
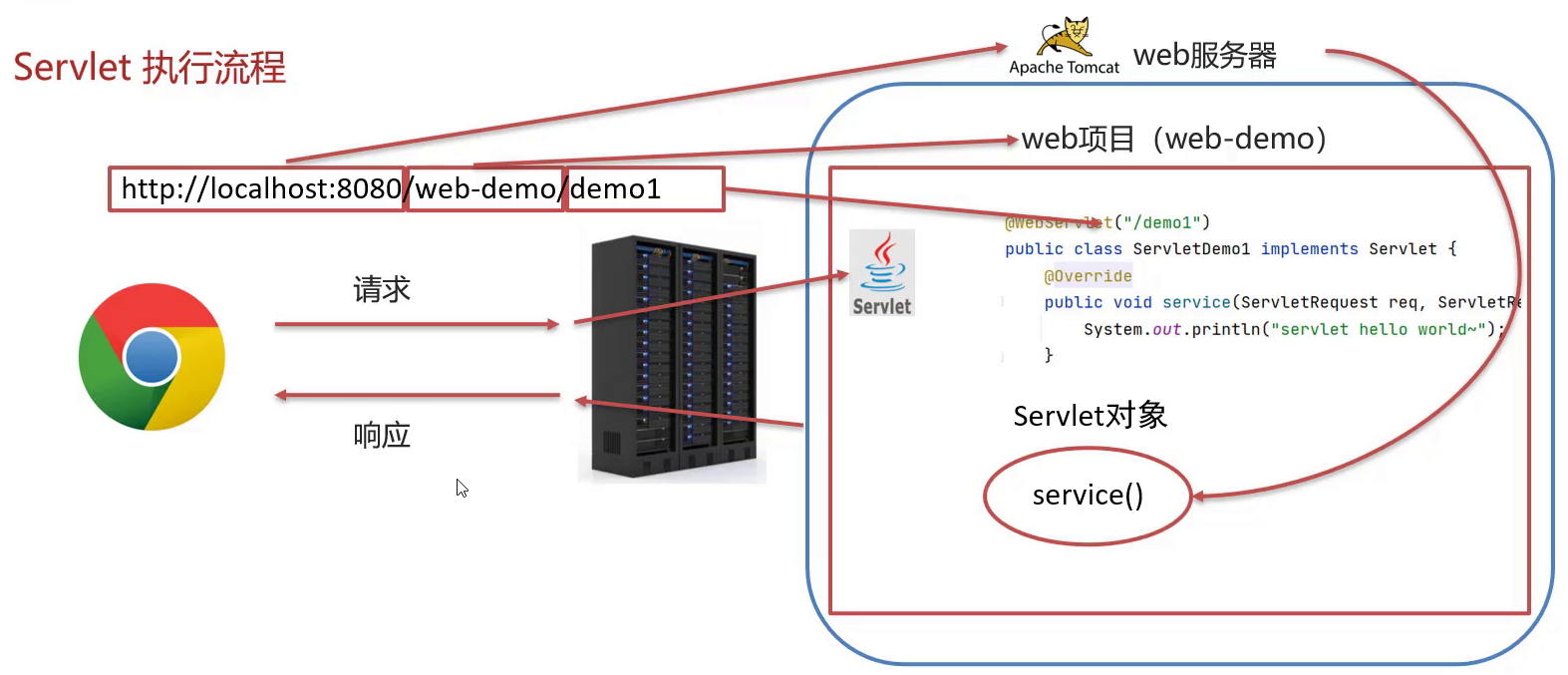
- 浏览器发出
http://localhost:8080/web-demo/demo1请求,从请求中可以解析出三部分内容,分别是localhost:8080、web-demo、demo1- 根据
localhost:8080可以找到要访问的Tomcat Web服务器 - 根据
web-demo可以找到部署在Tomcat服务器上的web-demo项目 - 根据
demo1可以找到要访问的是项目中的哪个Servlet类,根据@WebServlet后面的值进行匹配
- 根据
- 找到ServletDemo1这个类后,Tomcat Web服务器就会为ServletDemo1这个类创建一个对象,然后调用对象中的service方法
- ServletDemo1实现了Servlet接口,所以类中必然会重写service方法供Tomcat Web服务器进行调用
- service方法中有ServletRequest和ServletResponse两个参数,ServletRequest封装的是请求数据,ServletResponse封装的是响应数据,后期我们可以通过这两个参数实现前后端的数据交互
Servlet 生命周期
- Servlet对象在什么时候被创建的?
默认是第一次访问的时候被创建,可以使用@WebServlet(urlPatterns = “/demo2”,loadOnStartup = 1)的loadOnStartup 修改成在服务器启动的时候创建。
- Servlet生命周期中涉及到的三个方法,这三个方法是什么?什么时候被调用?调用几次?
涉及到三个方法,分别是 init()、service()、destroy()
init方法在Servlet对象被创建的时候执行,只执行1次
service方法在Servlet被访问的时候调用,每访问1次就调用1次
destroy方法在Servlet对象被销毁的时候调用,只执行1次
不需要编写service()方法方法,直接继承HttpServlet,然后重写父类中的doGet和doPost方法,就可以用来处理GET和POST请求的业务逻辑。
urlPattern配置
Servlet类编写好后,要想被访问到,就需要配置其访问路径(urlPattern)
一个Servlet,可以配置多个urlPattern

package com.itheima.web;import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebServlet;/**
* urlPattern: 一个Servlet可以配置多个访问路径
*/
@WebServlet(urlPatterns = {"/demo7","/demo8"})
public class ServletDemo7 extends MyHttpServlet {@Overrideprotected void doGet(ServletRequest req, ServletResponse res) {System.out.println("demo7 get...");}@Overrideprotected void doPost(ServletRequest req, ServletResponse res) {}
}
Request
获取请求数据
- 浏览器会发送HTTP请求到后台服务器[Tomcat]
- HTTP的请求中会包含很多请求数据[请求行+请求头+请求体]
- 后台服务器[Tomcat]会对HTTP请求中的数据进行解析并把解析结果存入到一个对象中
- 所存入的对象即为request对象,所以我们可以从request对象中获取请求的相关参数
- 获取到数据后就可以继续后续的业务,比如获取用户名和密码就可以实现登录操作的相关业务
在学习下面内容之前,我们先提出两个问题:
- 什么是请求参数?
- 请求参数和请求数据的关系是什么?
1.什么是请求参数?
为了能更好的回答上述两个问题,我们拿用户登录的例子来说明
1.1 想要登录网址,需要进入登录页面
1.2 在登录页面输入用户名和密码
1.3 将用户名和密码提交到后台
1.4 后台校验用户名和密码是否正确
1.5 如果正确,则正常登录,如果不正确,则提示用户名或密码错误
上述例子中,用户名和密码其实就是我们所说的请求参数。
2.什么是请求数据?
请求数据则是包含请求行、请求头和请求体的所有数据
3.请求参数和请求数据的关系是什么?
3.1 请求参数是请求数据中的部分内容
3.2 如果是GET请求,请求参数在请求行中
3.3 如果是POST请求,请求参数一般在请求体中
请求参数
request对象已经将上述获取请求参数的方法进行了封装,并且request提供的方法实现的功能更强大,以后只需要调用request提供的方法即可,在request的方法中都实现了哪些操作?
(1)根据不同的请求方式获取请求参数,获取的内容如下:

(2)把获取到的内容进行分割,内容如下:

(3)把分割后端数据,存入到一个Map集合中:
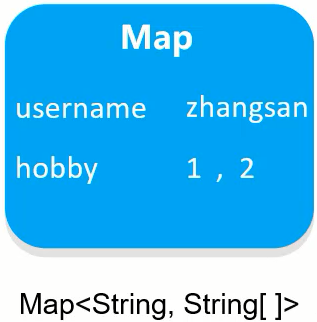
注意:因为参数的值可能是一个,也可能有多个,所以Map的值的类型为String数组。
基于上述理论,request对象为我们提供了如下方法:
- 获取所有参数Map集合
Map<String,String[]> getParameterMap()
- 根据名称获取参数值(数组)
String[] getParameterValues(String name)
- 根据名称获取参数值(单个值)
String getParameter(String name)
中文乱码解决方案
-
POST请求和GET请求的参数中如果有中文,后台接收数据就会出现中文乱码问题
GET请求在Tomcat8.0以后的版本就不会出现了
-
POST请求解决方案是:设置输入流的编码
request.setCharacterEncoding("UTF-8"); 注意:设置的字符集要和页面保持一致 -
通用方式(GET/POST):需要先解码,再编码
new String(username.getBytes("ISO-8859-1"),"UTF-8");
- URL编码实现方式:
-
编码:
URLEncoder.encode(str,"UTF-8"); -
解码:
URLDecoder.decode(s,"ISO-8859-1");
请求转发
(1)修改RequestDemo5中的方法
@WebServlet("/req5")
public class RequestDemo5 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {System.out.println("demo5...");//存储数据request.setAttribute("msg","hello");//请求转发request.getRequestDispatcher("/req6").forward(request,response);}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}
(2)修改RequestDemo6中的方法
/*** 请求转发*/
@WebServlet("/req6")
public class RequestDemo6 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {System.out.println("demo6...");//获取数据Object msg = request.getAttribute("msg");System.out.println(msg);}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}
(3)启动测试
访问http://localhost:8080/request-demo/req5,就可以在控制台看到如下内容:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8gWv0fmC-1646302239194)(assets/1628857213364.png)]](https://img-blog.csdnimg.cn/e609166a278a4ceca1cc732d63a37719.png)

请求重定向
(1)创建ResponseDemo1类
@WebServlet("/resp1")
public class ResponseDemo1 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {System.out.println("resp1....");}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}
(2)创建ResponseDemo2类
@WebServlet("/resp2")
public class ResponseDemo2 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {System.out.println("resp2....");}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}
(3)在ResponseDemo1的doGet方法中给前端响应数据
@WebServlet("/resp1")
public class ResponseDemo1 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {System.out.println("resp1....");//重定向resposne.sendRedirect("/request-demo/resp2");}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}
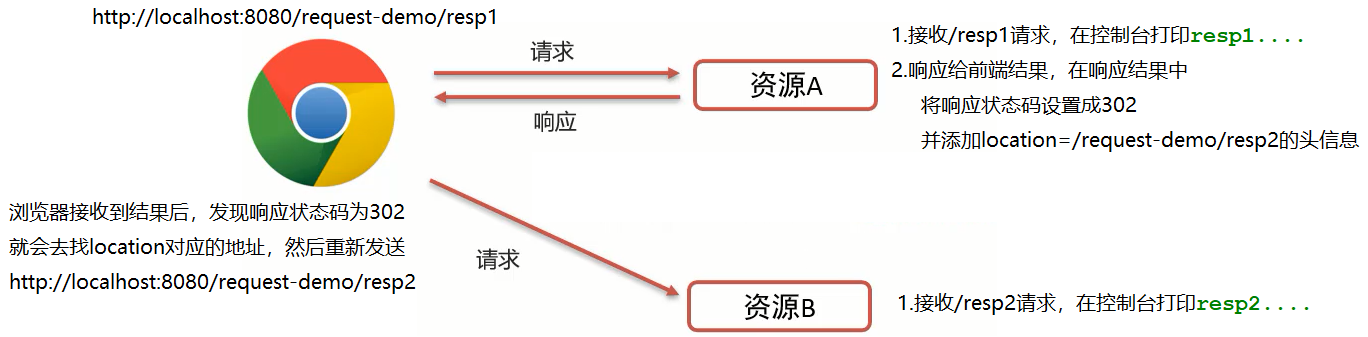
(4)启动测试
访问http://localhost:8080/request-demo/resp1,就可以在控制台看到如下内容:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fc2s41gp-1646302415773)(assets/1628861404699.png)]](https://img-blog.csdnimg.cn/c212d901374240939e153886517b0cab.png)
说明/resp1和/resp2都被访问到了。到这重定向就已经完成了。
路径问题
什么时候加/
- 浏览器使用:需要加虚拟目录(项目访问路径)
- 服务端使用:不需要加虚拟目录
1.超链接,从浏览器发送,需要加
2.表单,从浏览器发送,需要加
3.转发,是从服务器内部跳转,不需要加
4.重定向,是由浏览器进行跳转,需要加。
Response响应字符数据
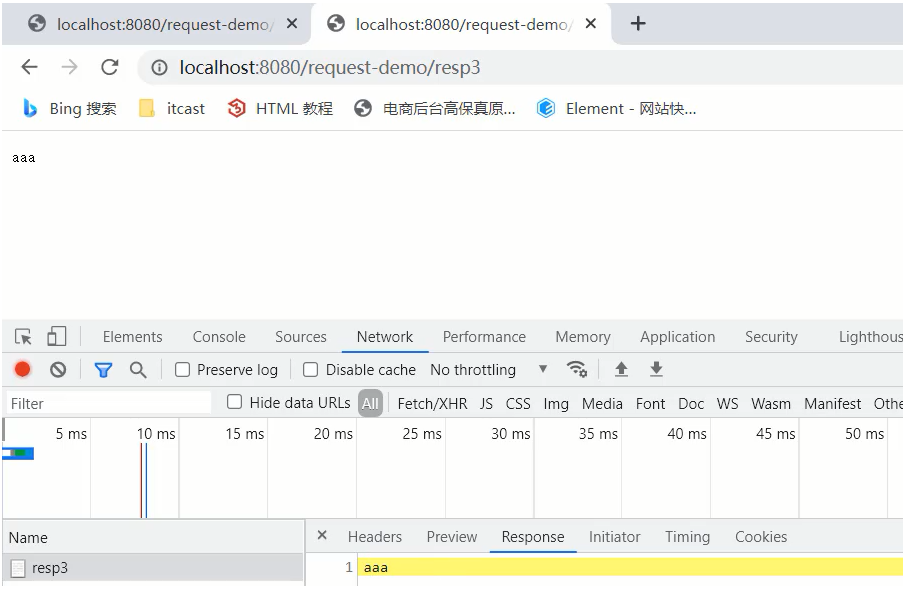
1.返回一个简单的字符串aaa:
通过Response对象获取字符输出流: PrintWriter writer = resp.getWriter();
通过字符输出流写数据: writer.write("aaa");
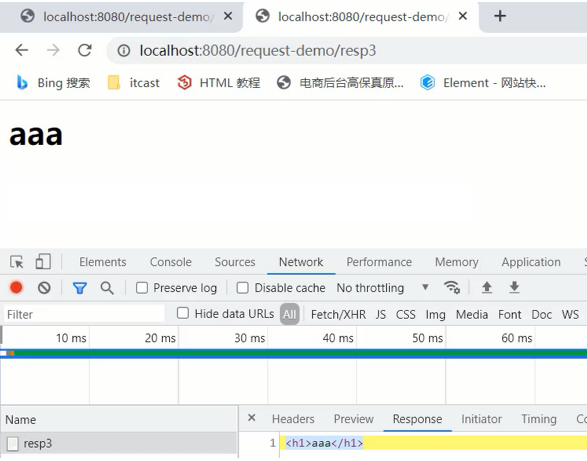
2.返回一串html字符串,并且能被浏览器解析:
PrintWriter writer = response.getWriter();
//content-type,告诉浏览器返回的数据类型是HTML类型数据,这样浏览器才会解析HTML标签
response.setHeader("content-type","text/html");
writer.write("<h1>aaa</h1>");
3. 返回一个中文的字符串你好,需要注意设置响应数据的编码为utf-8:
//设置响应的数据格式及数据的编码
response.setContentType("text/html;charset=utf-8");
writer.write("你好");
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-luhdIpGO-1646303068046)(assets/1628864390263.png)]](https://img-blog.csdnimg.cn/260e13187a6a47b6ab6e0e0bf6971c8f.png)
Response响应字节数据
返回一个图片文件到浏览器:
(1)pom.xml添加依赖
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version>
</dependency>
(2)调用工具类方法
//fis:输入流
//os:输出流
IOUtils.copy(fis,os);
优化后的代码:
/*** 响应字节数据:设置字节数据的响应体*/
@WebServlet("/resp4")
public class ResponseDemo4 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {//1. 读取文件FileInputStream fis = new FileInputStream("d://a.jpg");//2. 获取response字节输出流ServletOutputStream os = response.getOutputStream();//3. 完成流的copyIOUtils.copy(fis,os);fis.close();}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}
}