在互联网络的时代,信息如同大海般没有边际。甚至我们获取信息的方法已经发生改变:从传统的翻书查字典,继而变成通过搜索引擎进行检索。我们从信息匮乏的时代一下子走到了信息极大丰富今天。
随着互联网的发展及普及,互联网用户迅速增长,上网已成为人们生活中的日常内容,人们通过网站阅读,发表,搜索,交流,购物等,所有这些上网行为,由点到线,都将汇聚庞大的商业价值。因此,互联网成为众多人的梦想帝国,淘金之地。不管您是腰缠万贯,还是身无分文,这里只谈信息为王,服务至上。因此信息的创造、收集、组织和再加工是网站的生存基础。信息采集系统可以自动获取网页内容,自动按照自身网站系统的数据结构抽取数据,并发布到网站系统中,让您不花丝毫心血和金钱,就可以使您的网站一夜之间网罗天下。
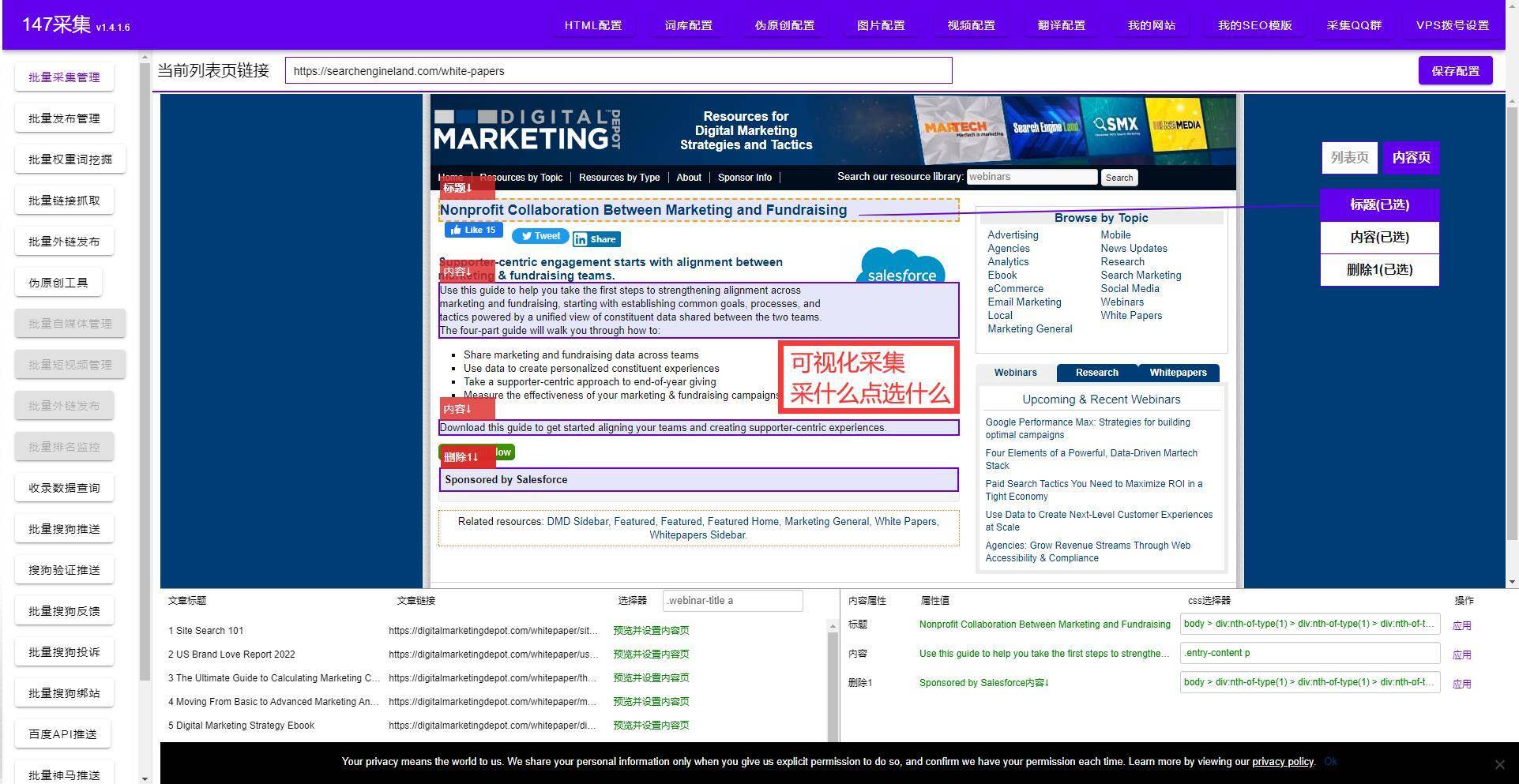
在今天,困扰我们的问题不是信息太少,而是太多,多得让你无从分辨,无从选择。因此,提供一个能够自动在互联网上抓取数据,并自动分拣、分析的工具有非常重要。
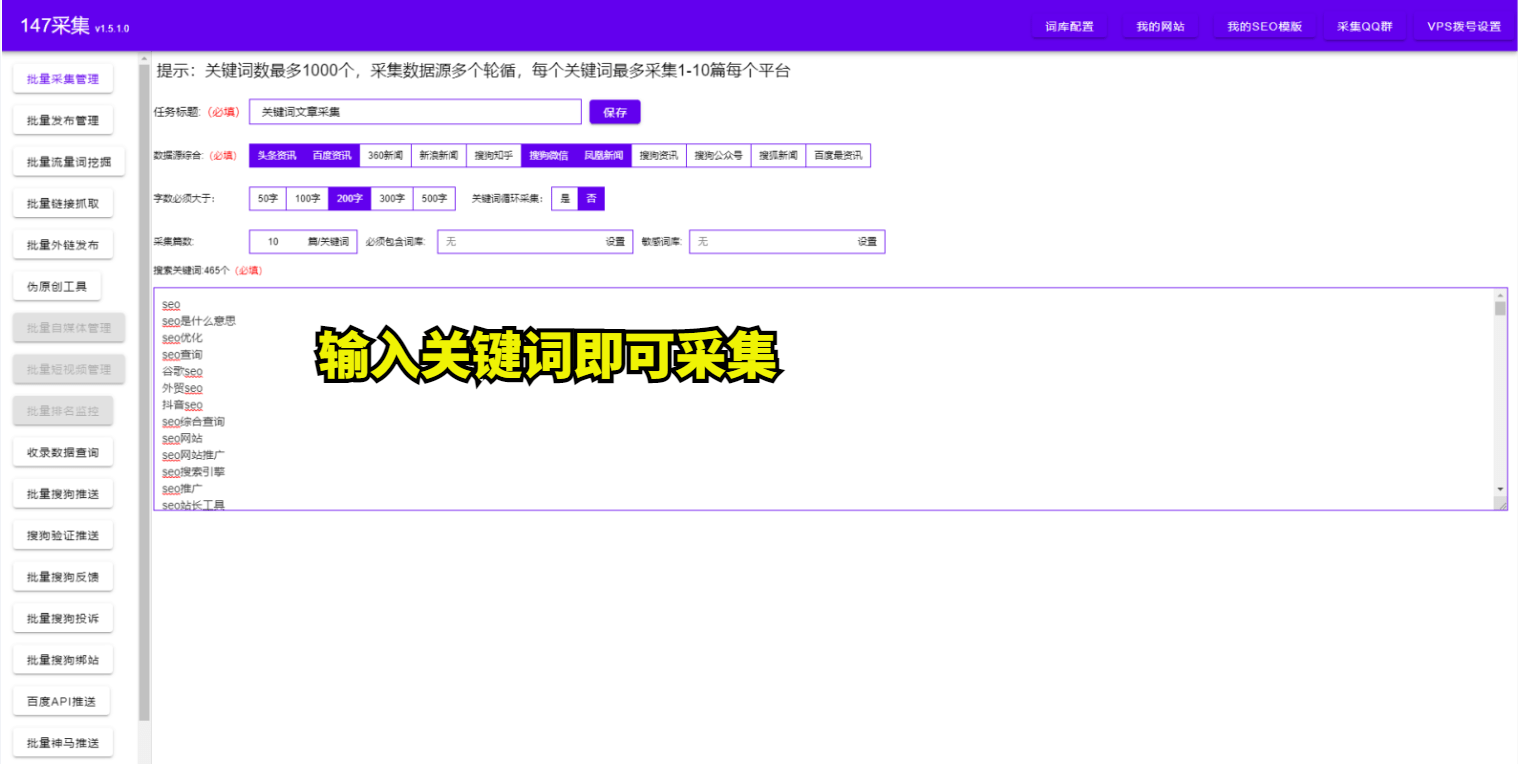
把简单易用做到极致, 任何人都能做数据采集, 根本不需要做什么配置,在网页上点击几下就可以采集数据。
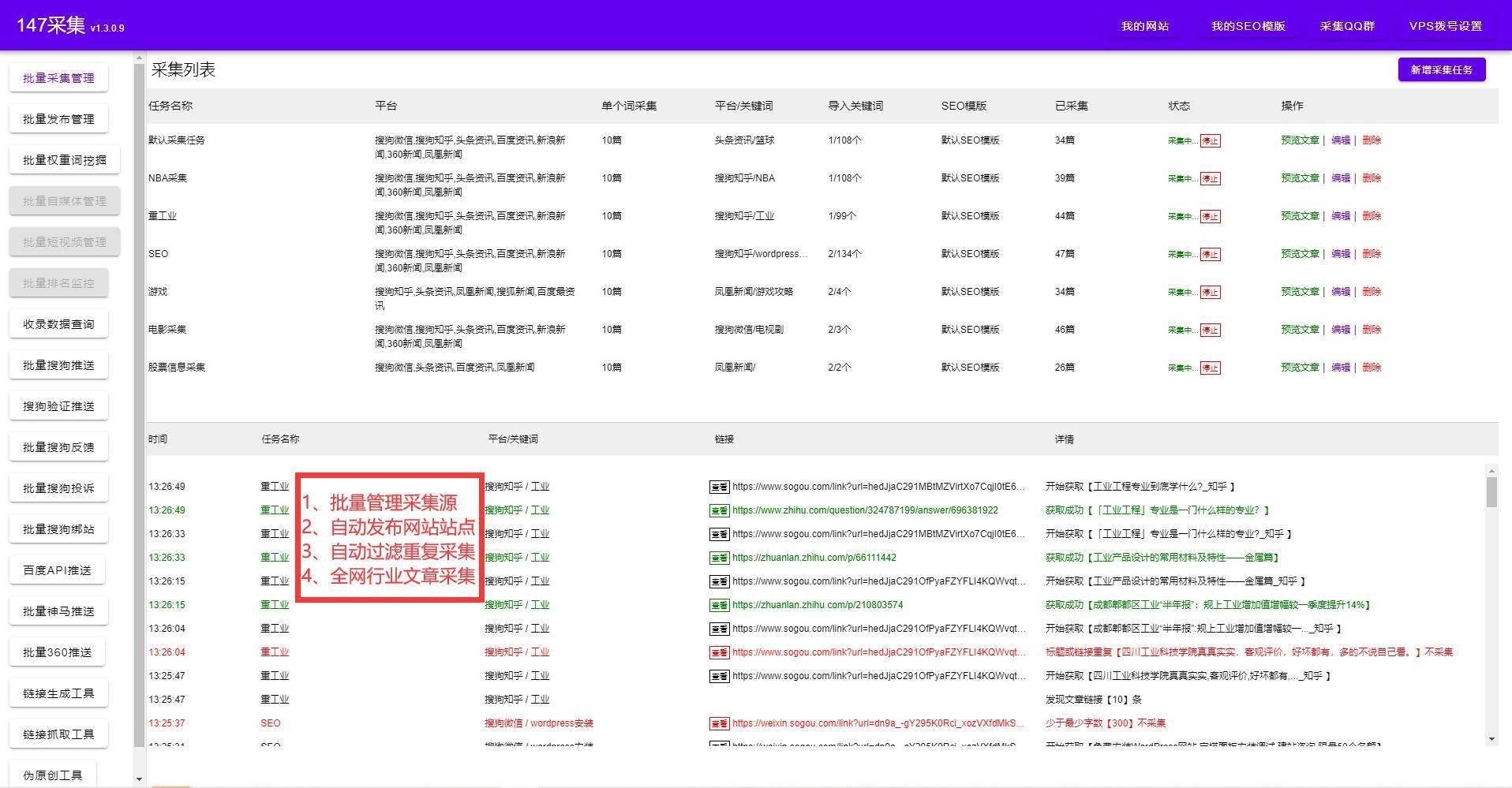
站长最大的心愿是提供最丰富的网站内容,吸引更多的人访问;市场营销人员每当通过蛛丝马迹而获取到隐藏的客户资源而兴奋不已;企业后勤人员做梦都想远离这些枯燥无味的文字录入。采集系统好比一双慧眼,让您看得更远,获得更多。
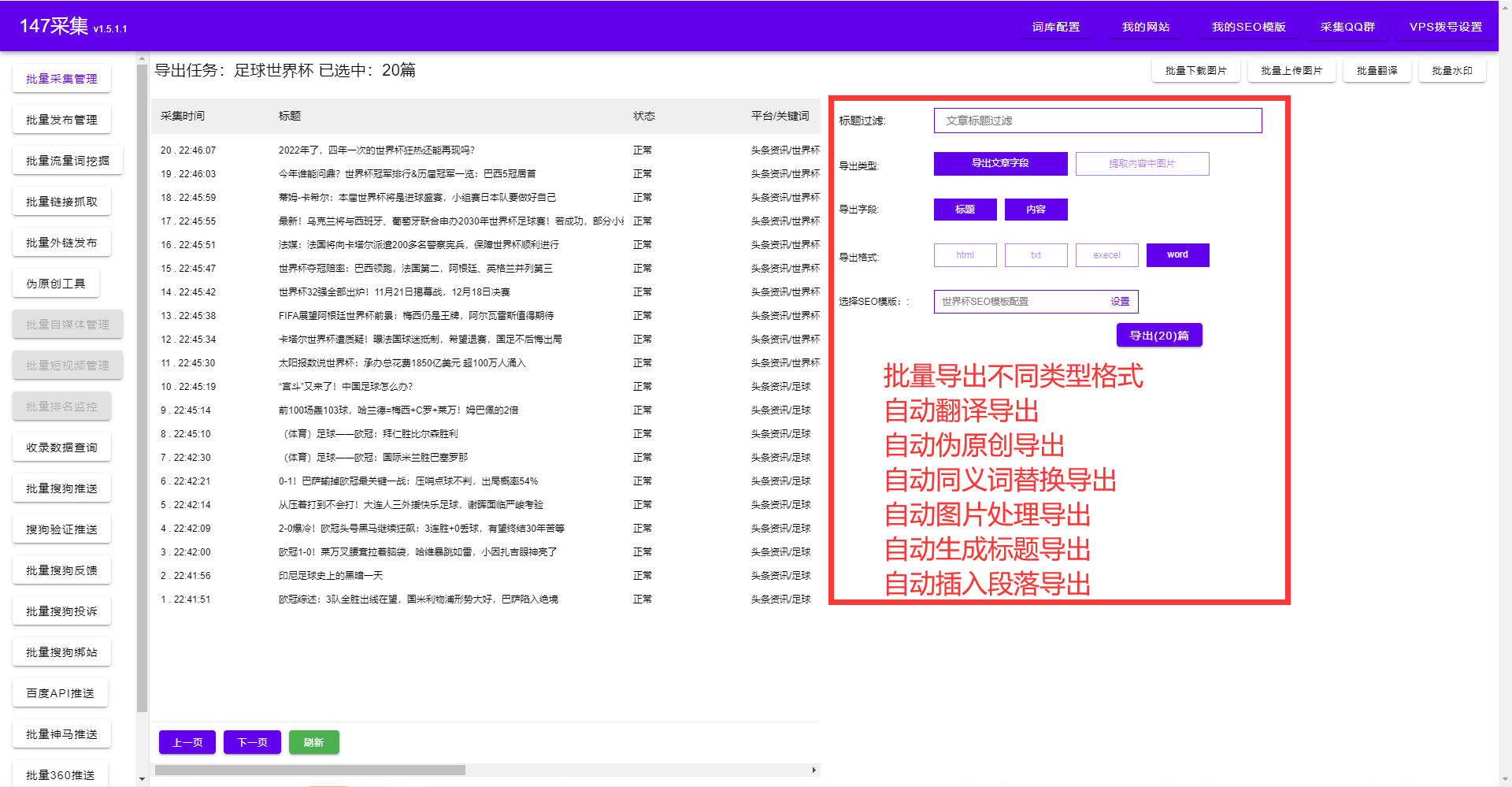
站长希望将别人的整站数据下载到自己的网站里或者将别人网站的一些内容保存到自己的服务器上。从内容中抽取相关的字段,发布到自己的网站系统中。
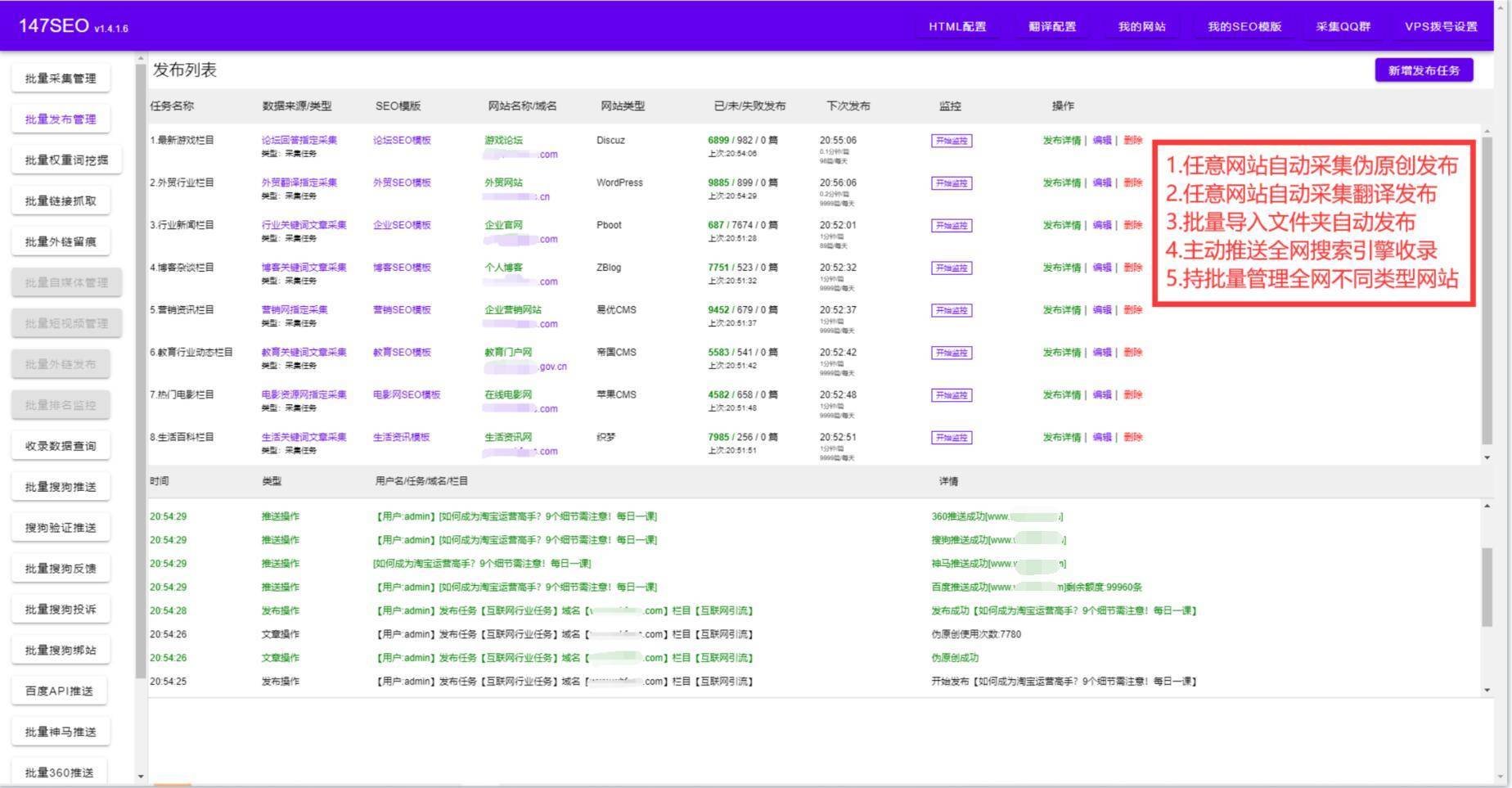
站长从互联网中收集各类图片、笑话、新闻、技术等各类信息,然后分类、编辑,发布到自己的网站系统中。网站管理员一般通过搜索引擎搜索各类关键字获取目标网址,然后再提取网页中的内容。关键字的组织决定获取内容的准确性和数量。

企业需要了解某一产品的信息,希望得到该类产品的报价、厂商等,以及这些信息的对比情况。并且能够得到报价、厂商的进一步信息。这些信息希望能够保存到企业的内部的ERP系统或其它系统中。