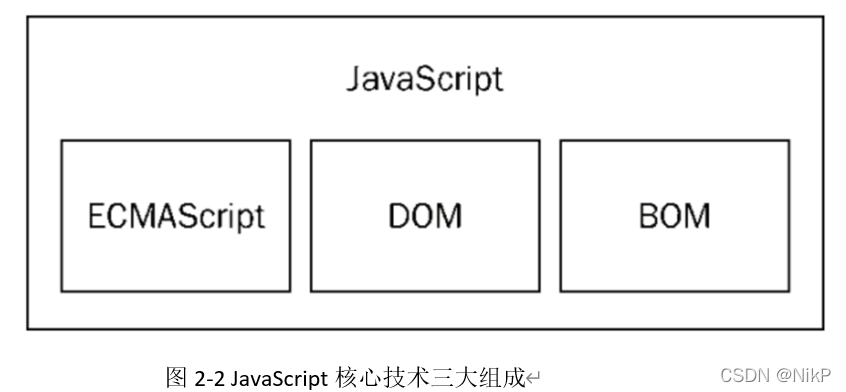
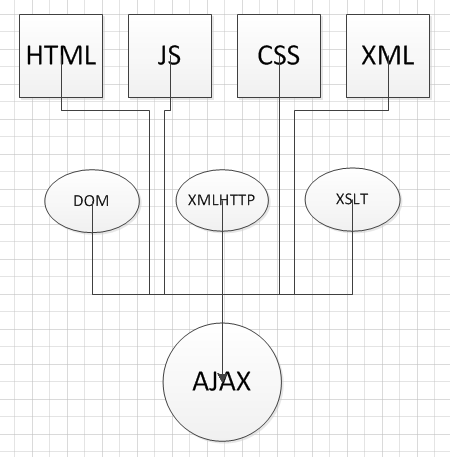
WEB技术与应用–概述
万维网
概述:万维网www(world wide web)
1.web模型
2.web客户端
3.web服务器
-
超链接:
超链接指向的资源可以处于lnternet的任一Web服务器之中, 利用超链接Web页面可以与其他Web页面进行关联。
-
万维网是分布式超媒体( hypermedia )系统,它是超文本(hypertext)系统的扩充
一个超文本由多个信息源链接成。利用一个链接可使用户找到另一个文档。这些文档可以位于世界上任何一个接在Internet上的超文本系统中。超文本是万维网的基础。
超媒体与超文本的区别是文档内容不同。超文本文档仅包含文本信息,而超媒体文档还包含其他表示方式的信息,如图形、图像、声音、动画,甚至活动视频图像。
-
地址
1.ip地址
-
我们把整个Internet看成为一个单一的、抽象的网络。IP地址就是给每个连接在Internet上的主机(或路由器)分配一个在全世界范围是唯一的32 bit的标识符(IPv4),这个标识符采用点分十进制表示(即:X.X.X.X,每个X为8bit ,采用十进制表示,范围为0~255 ),例如:128.11.3.31。
-
在IPv4协议中,每个IP地址由两部分组成︰网络号( Netid )和主机号(Hostid )。网络号用于标识一个网络,主机号用于标识在该网络中的一个主机。
-

2.域名
顶级域名 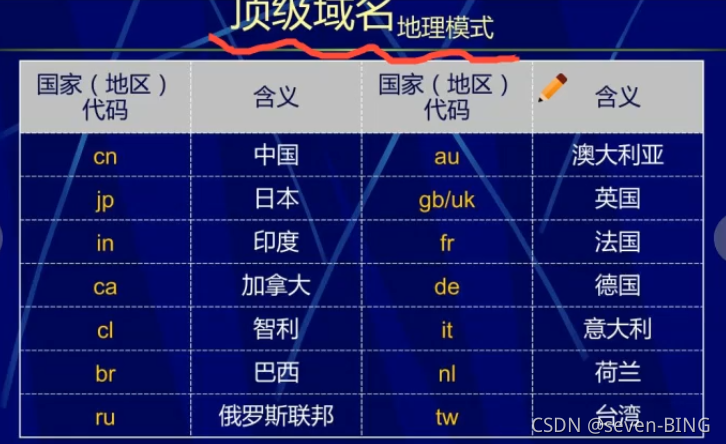
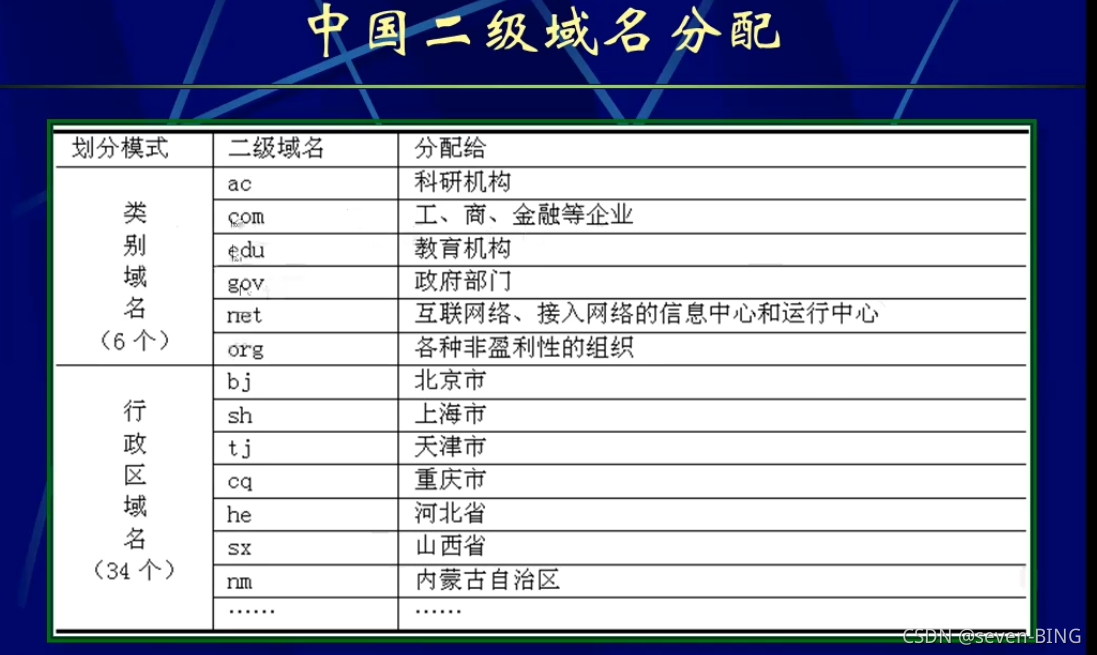

域名解析:
将域名映射为对应的P地址(或将IP地址映射为对应的域名),域名解析采用一个联机分布式数据库系统,利用客户/服务器模式进行工作,需要借助于一组既相互独立又相互协作的域名服务器完成。
3.url
统一资源定位符URL( UniformResource Locator )是对可以从因特网上得到的资源的位置和访问方法的一种简洁的表示。URL 给资源的位置提供一种抽象的识别方法,并用这种方法给资源定位。只要能够对资源定位,系统就可以对资源进行各种操作,如存取、更新、替换和查找其属性。
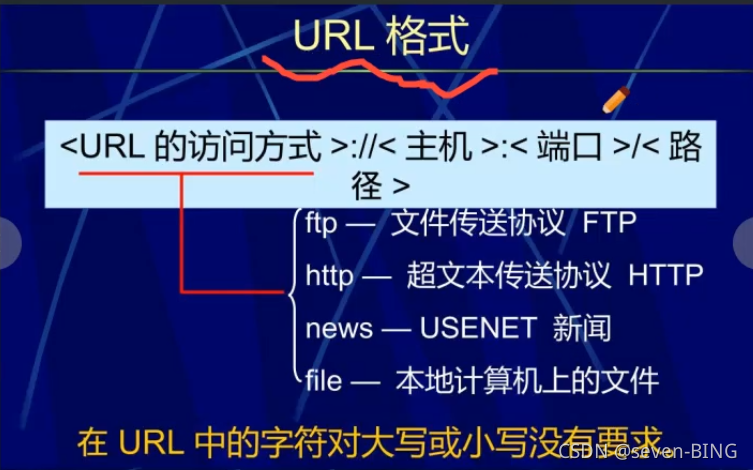


-
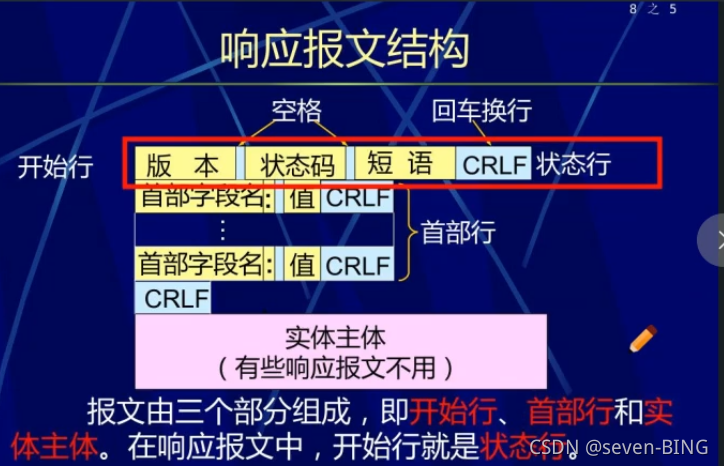
HTTP
超文本传送协议HTTP ( HyperTextTrahsfer Protocol)是web客户机与Web服务器之间的传输协议。它建立在TCP的基础上,是一种面向事务的( transaction-oriented )应用层协议,它是万维网上能够可靠地交换文件(包括文本、声音、图像等)的重要基础。
Http是面向事务的客户服务器协议:
所谓事务就是指一系列的信息交换,而这一系列的信息交换是一个不可分割的整体,即:要么所有的信息交换都完成,要么一次交换都不进行。




web文档
1. 静态web文档
-
基本概念
静态Web文档是固定内容的文档,它由服务器创建,开存储在服务器中,客户只能得到文档的一个副本。
-
HTML(超文本标记语言)
超文本标记语言HTML( HyperText Markup Language )是一种制作Web文档的标准语言,是一种描述了如何格式化文档的标记语言。

常用标签:
<html></html> //声明要用HTML编写的网页
<head></head>//限定页面的页眉
<title></title>//定义标题(不显示在页面上)
<body></body>//定义页面的正文
<h1></h1>//划定n级标题
<b></b>//设置黑体字
<i></i>//设置斜体字
<center></center>//居中水平放置在页面上
<ul></ul>//将无序(项目符号)列表括起来
<ol></ol>//用括号括起编号的清单
<li>//启动列表项(没有</li>)
<br>//在这里强制换行
<p></p>//开始一段
<hr>//插入水平规则
<img src="...">//在此处显示图像
<a href="....">...</a>//定义超链接 HTML的缺点:
HTML缺乏可扩展能力
HTML只能描述数据的显示样式
HTML数据的可重用性差
HTML缺乏表达数据语义的能力
XML和XSL:
为实现可扩展性和结构化, W3C开发出两种新的语言:
XML 可扩展标记语言(eXtensible Markup Language):
用一种结构化的方式来描述Web内容.
XSL 可扩展样式表语言(eXtensible Style Language):
以一种独立于内容的方式来描述格式。
XHMTL(可扩展的超文本标记语言):
本质是重新用XML来表示的HTML 4,它与HTML 4有六个主要差别,以及许多小差别
2.动态web文档
静态和动态的区别:
静态Web文档是指该文档创作完毕后就存放在万维网服务器中,在被用户浏览的过程中,内容不会改变。
动态Web文档是指文档的内容是在浏览器访问万维网服务器时才由应用程序动态生成。内容的生成既可以发生在服务器端,也可以发生在客户端。
注:主要差别体现在文档内容的生成方法不同。
ASP.NET(ASP+)
1.ASP.NET简介
.NET的核心内容之一就是要搭建第三代互联网平台,,这个网络平台将打破不同的上网设备、不同的操作系统、不同的网站以及各大机构和工业界的网络障碍,将解决网站之间的协同合作,使网站之间形成自动交流,从而最大程度的共享资源。
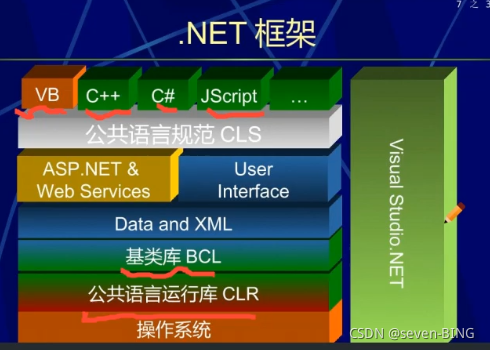
ASP.NET是NET框架中专门用来开发网上应用程序的,它其实不是一种语言,而更像一个框架,在这个框架中可以采用VB.NET 、C#等
ASP.NET的功能和特点:
效率增强,顶级开发工具支持,程序结构清晰,开发简单,移植方便,Web服务
2.ASP.NET的运行环境
llS是 Microsoft提供的一种 Web服务组件,包括Web服务器、FTP服务器、NNTP服务器和SMTP服务器等。IIS通过使用超文本传输协议HTTP传输信息。如果操作系统平台是 Windows 的Server 版本,则已默认安装了IIS。
3.ASP.NET的开发工具
4.创建ASP.NET页面
ASP.NET文件的扩展名一般为.aspx,一般由程序代码和HTM代码两部分组成。

实验上机路径:
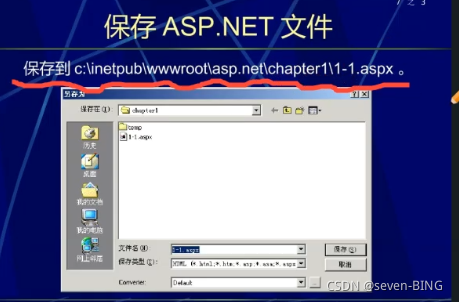
运行ASP.NET文件的方式:

注:我的内容不完善,自己学习笔记,仅供参考