Web Scraper,官网自称为排名第一的网页抓取/提取插件,可以安装在Chrome和Firefox上。
安装路径:
https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn?hl=en![]() https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
Web Scraper – Get this Extension for 🦊 Firefox (en-US)![]() https://addons.mozilla.org/en-US/firefox/addon/web-scraper/
https://addons.mozilla.org/en-US/firefox/addon/web-scraper/
也可以用浏览器打开官网,点击Install,则自动选择安装。
Web Scraper - The #1 web scraping extension![]() https://webscraper.io/
https://webscraper.io/
也可以在浏览器右上方找到Extensions图标,点开,下拉菜单,找到Manage Extensions,也就是进入了chrome://extensions。
左上角点开,然后左下角进入Web Store,之后打开新页面,在里面搜索web scraper,安装即可。
相关使用说明,最好看一下视频:
Web Scraper Tutorials![]() https://webscraper.io/tutorials
https://webscraper.io/tutorials
不过是Youtube链接,可能有点困难,网上也可随便搜搜也有教学。
这个插件普通版是免费的,加强版要收费,如果有钱有需要,不花就浪费。
使用这个插件,因为集成在浏览器里,使用起来很方便,很适合菜鸟和普通非专业技术人员使用,如果是需要更强大更定制化的网页数据抓取,可能需要更专业的工具或者自己编程实现了。
下面就我使用这个插件的情况做一下介绍,以作记录供你我他参考。
--------------------------------------------------------------------
第一步,安装,如上介绍。
第二步,以Chrome为例,在浏览器地址栏输入:chrome://extensions/
查看Web Scraper是否安装成功并启用。
第三步,F12或者Ctrl+Shift+I,打开开发者工具:
打开后,选择底部显示模式:
然后找到最后一个WebScraper标签,点击进入。
好了,准备工作已经完成。
----------------------------------------------------------
第一个例子,按照官网的教学视频,操作一遍。
打开官方提供的测试网站:
Web Scraper Test Sites![]() https://webscraper.io/test-sites/e-commerce/allinone
https://webscraper.io/test-sites/e-commerce/allinone
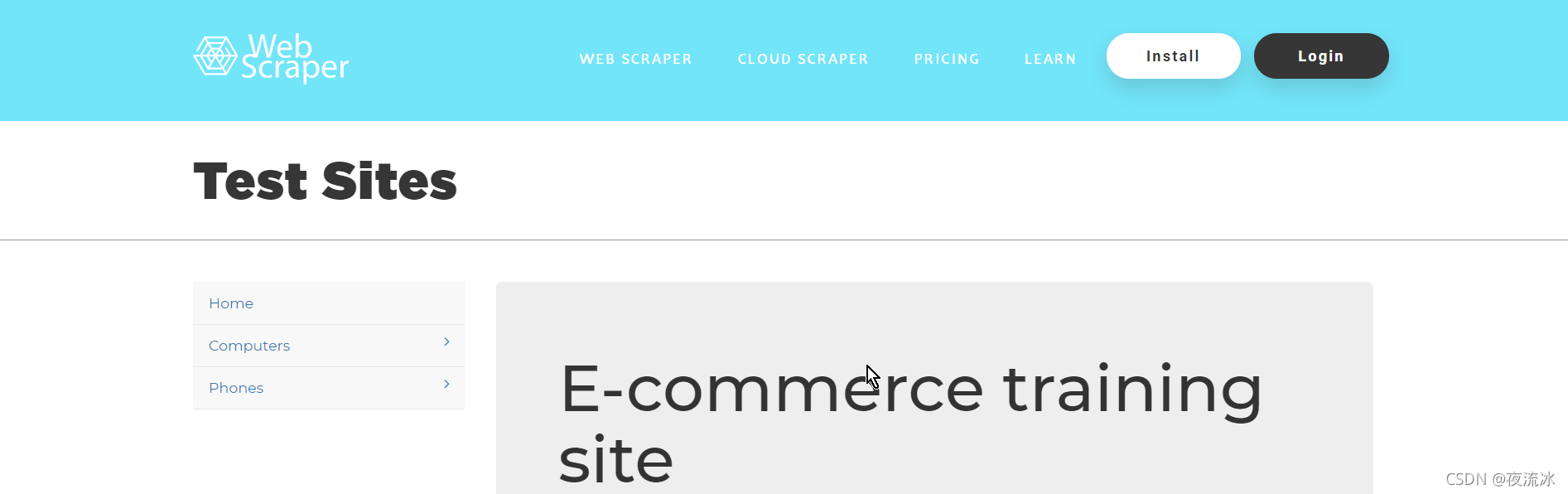
官方提供的测试网站是一个电商网站,我们先简单浏览一下,里面分了两级,一级是主分类:电脑和手机;一级是子分类,在电脑和手机下面的分类包含具体的产品项,产品项点开是具体的产品信息。
我们的目标是要通过浏览两级的目录结构,把所有的产品信息提取出来。
先设置登录页面,入口网址,landing page。从这个页面开始,Web scraper会浏览整个网站,我们需要创建多个选择器,形成一个树结构,类似于网站构建时的结构。
这些选择器定义了网站如何被浏览和数据如何被提取。
如下图所示操作,就是要Create Sitemap,输入地址为上面的浏览器显示地址:Web Scraper Test Sites![]() https://webscraper.io/test-sites/e-commerce/allinone
https://webscraper.io/test-sites/e-commerce/allinone
一个完整数据提取就是基于一个sitemap,我们配置好sitemap后,设置可以保存后下次继续使用,需要重新提取直接执行即可。
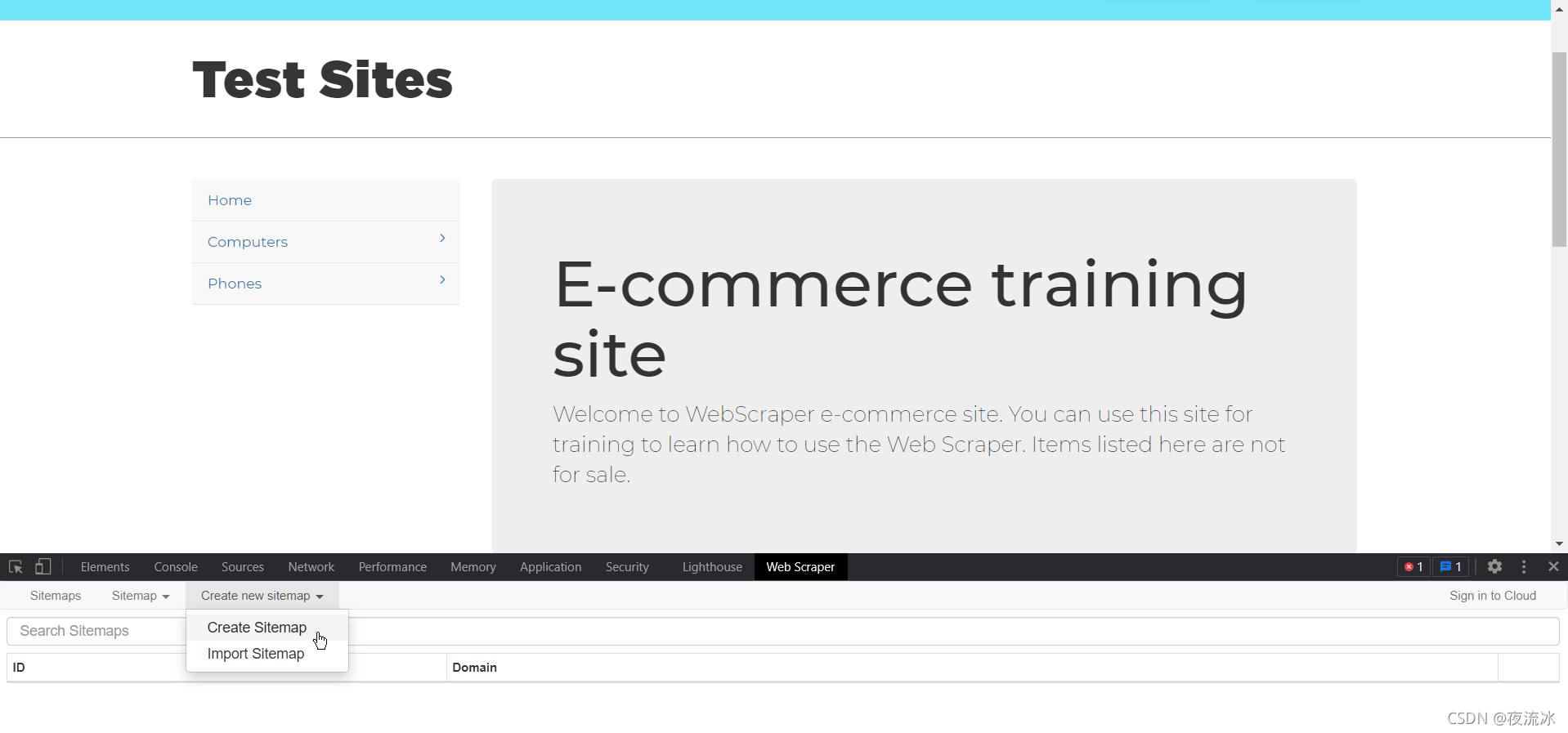
Create site时命名为E-commerce。

这时后面有个Data preview按键,点开后发现目前是什么数据都没有的,需要添加选择器。

初始页面里的分级的栏目,为了访问,我们要创建链接形式的选择器。点击Add new selector。
然后点击select进行选择链接形式的网页元素。
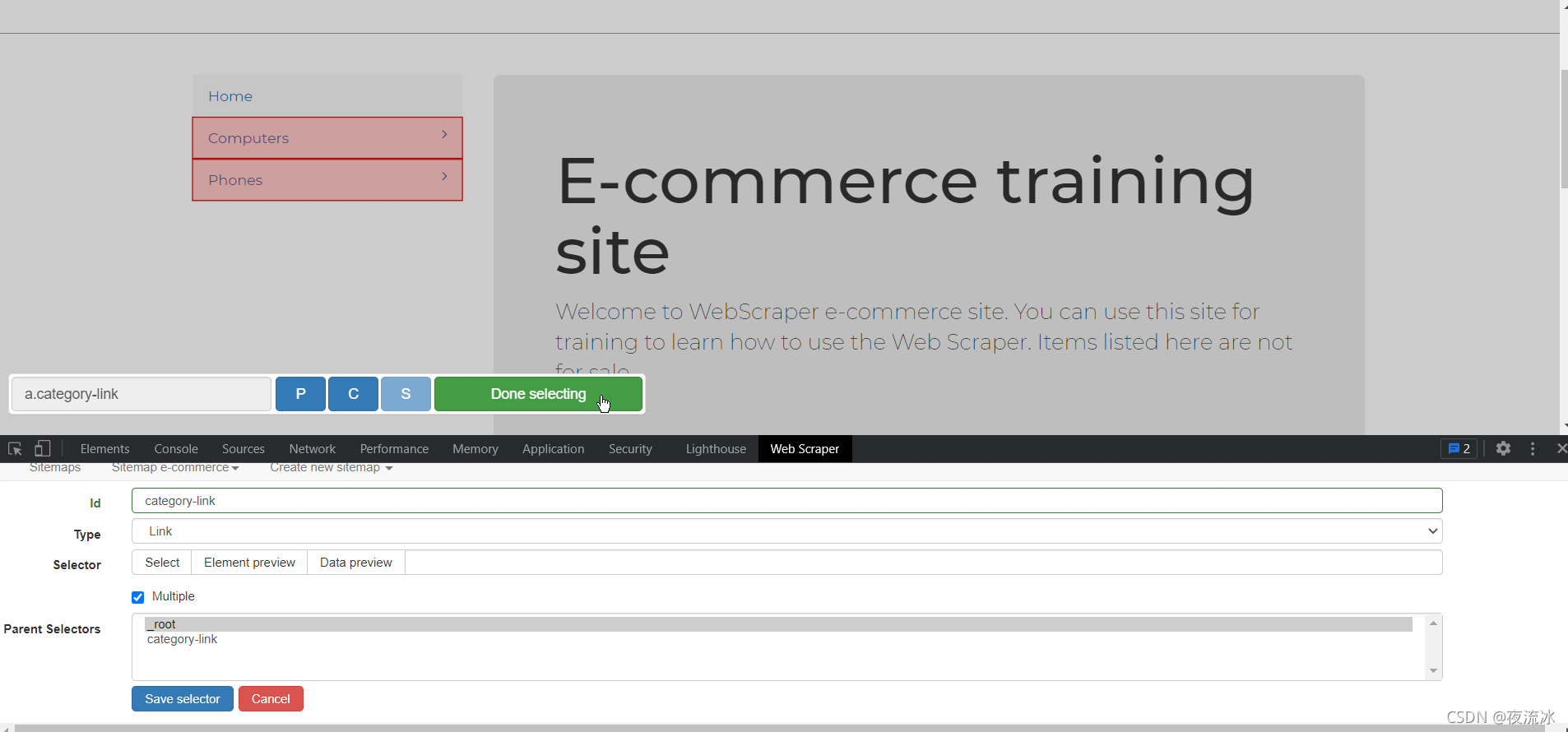
选择器命名为category-linkm,类型为link,点击select后选择两个链接,勾选Multiple,Parent Selectors就是登录页面。
点击Select后在网页上选择元素,完成后点击Done selecting。
验证选择结果,可以点击Element preview查看选择是否正确,并点击data preview看是否正常工作。
然后Save selector。
下一步我们创建下一级链接的选择器。
网页上点击Computer,继续创建链接形式的选择器。
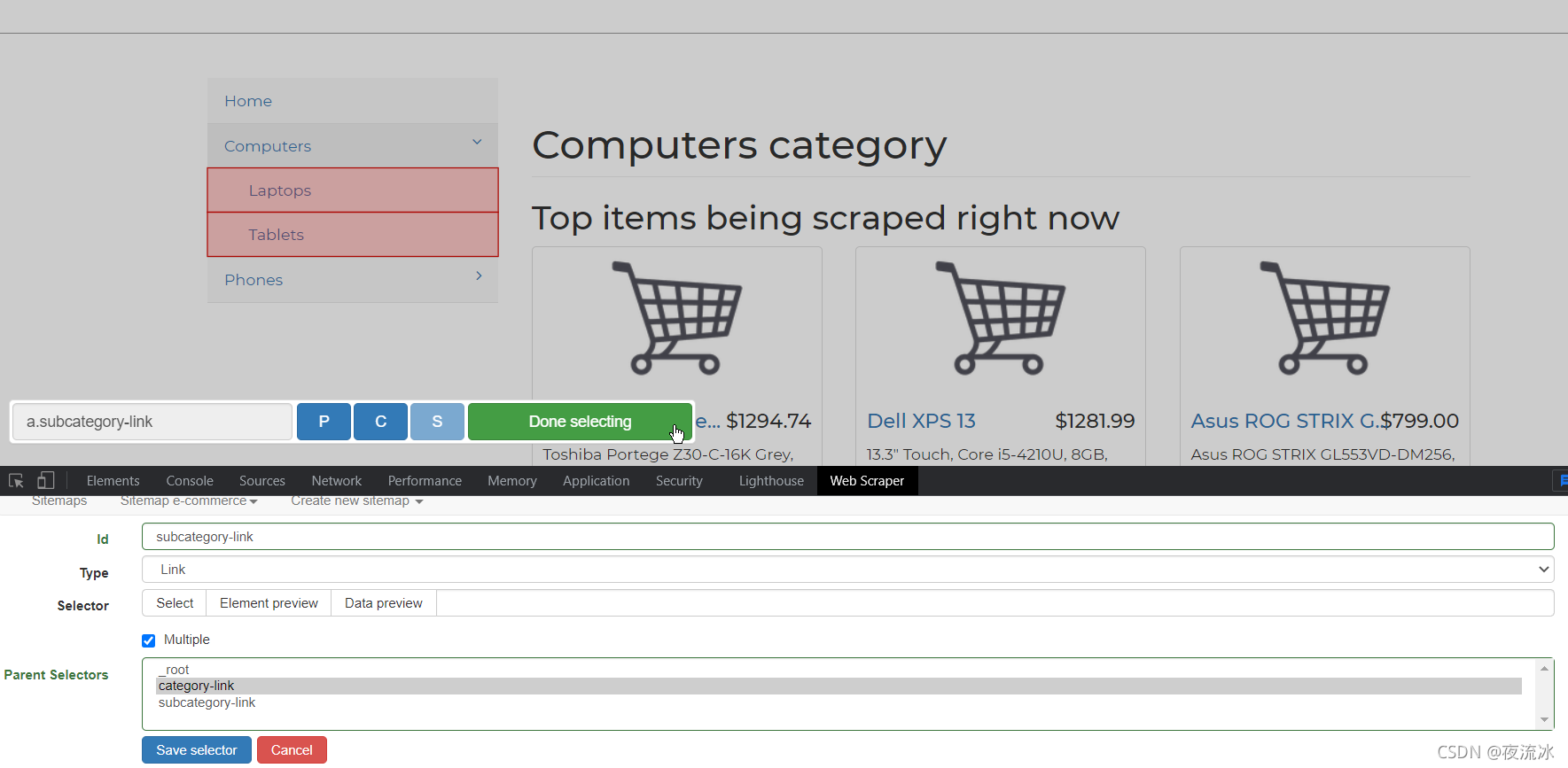
点击保存。然后创建产品页的链接选择器,先点击Laptops进入产品列表页。
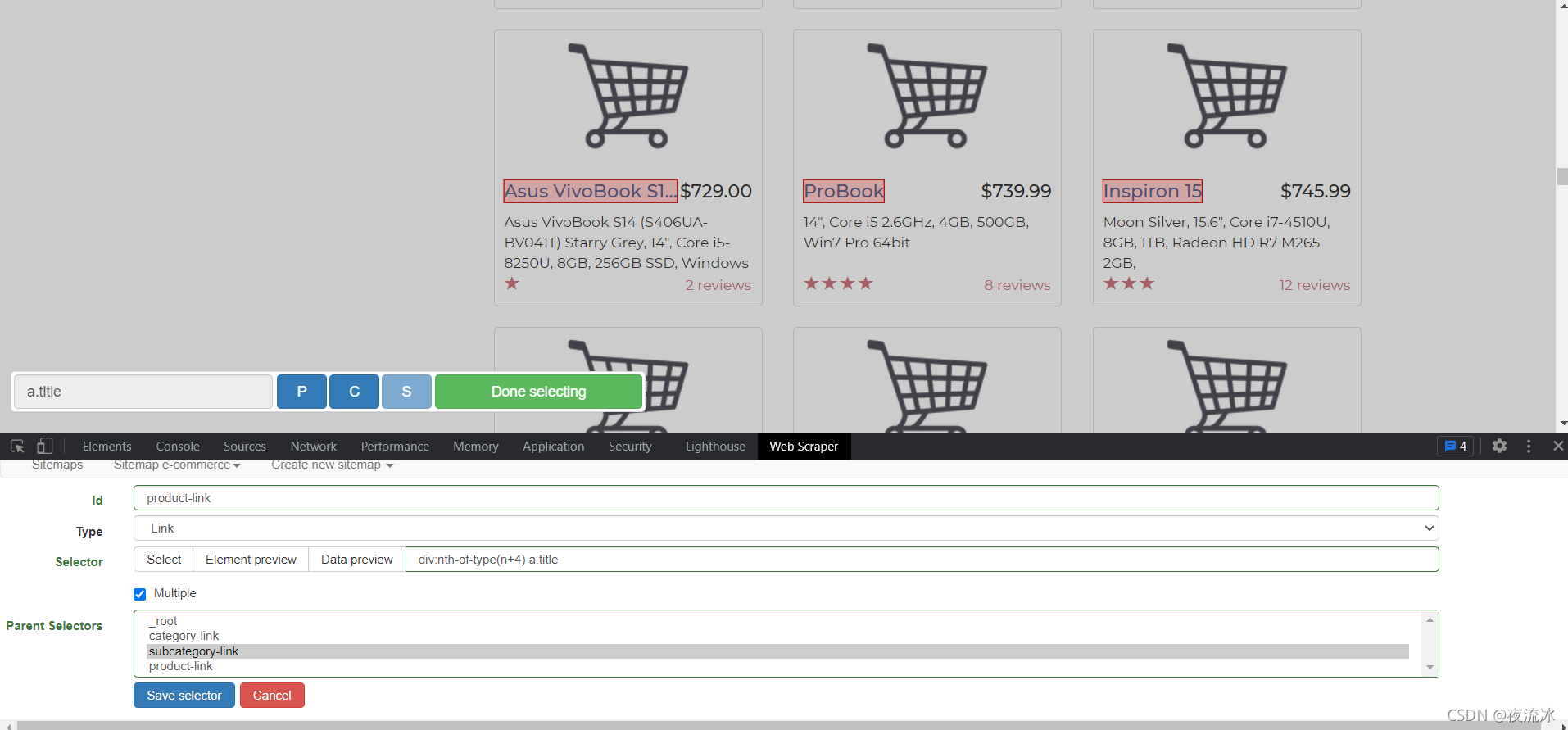
点击产品链接进入产品页,创建Text类型的选择器,将需要的数据提取出来。
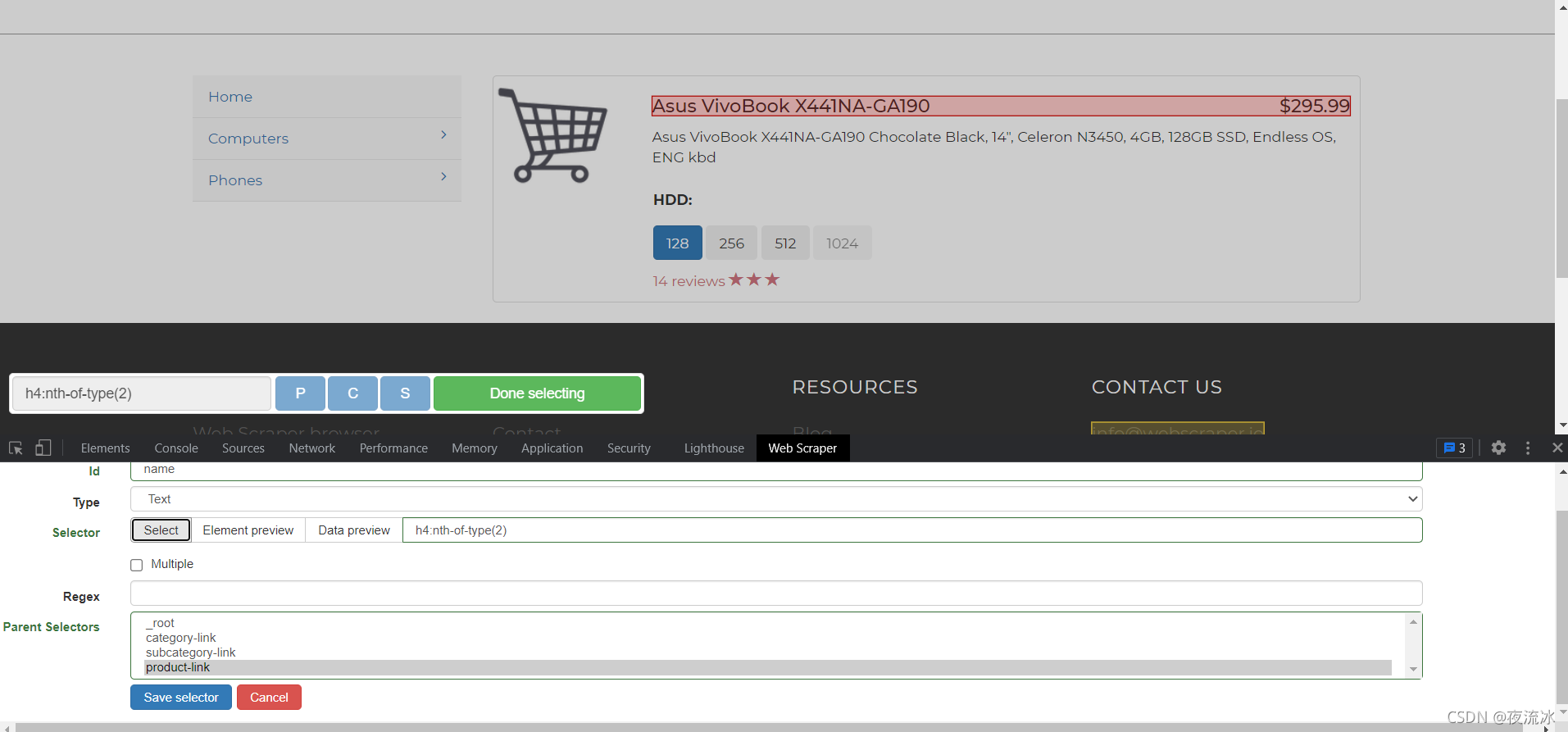
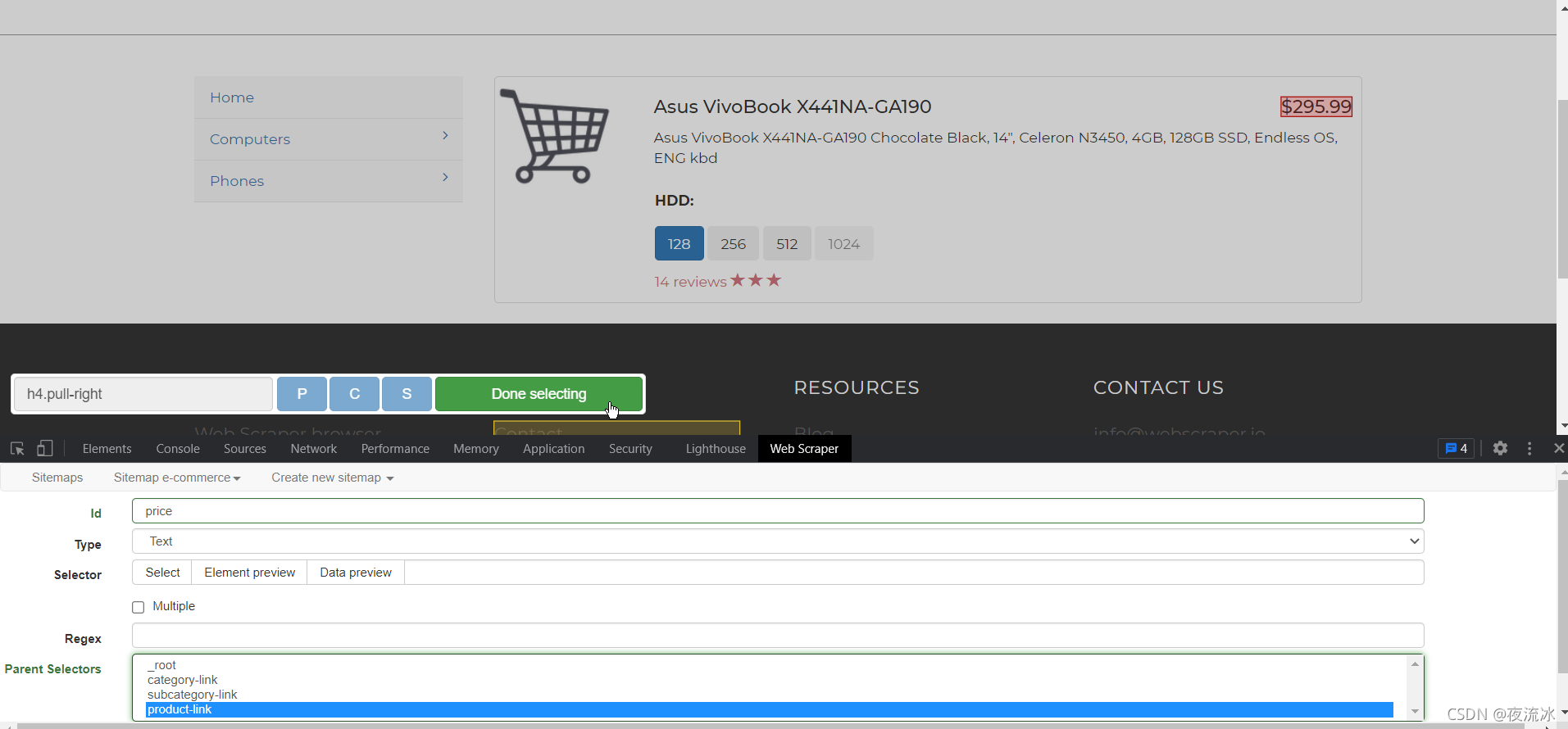
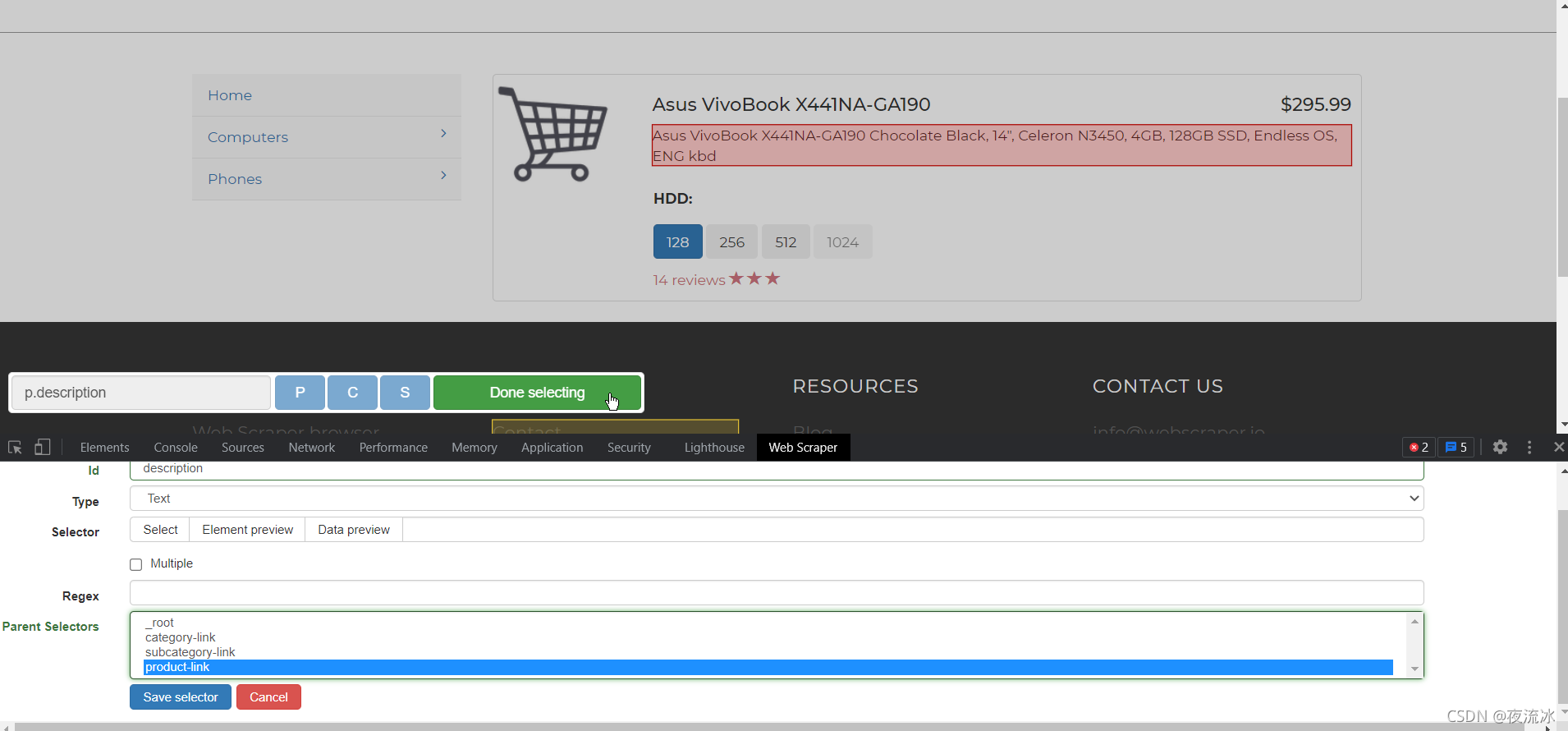
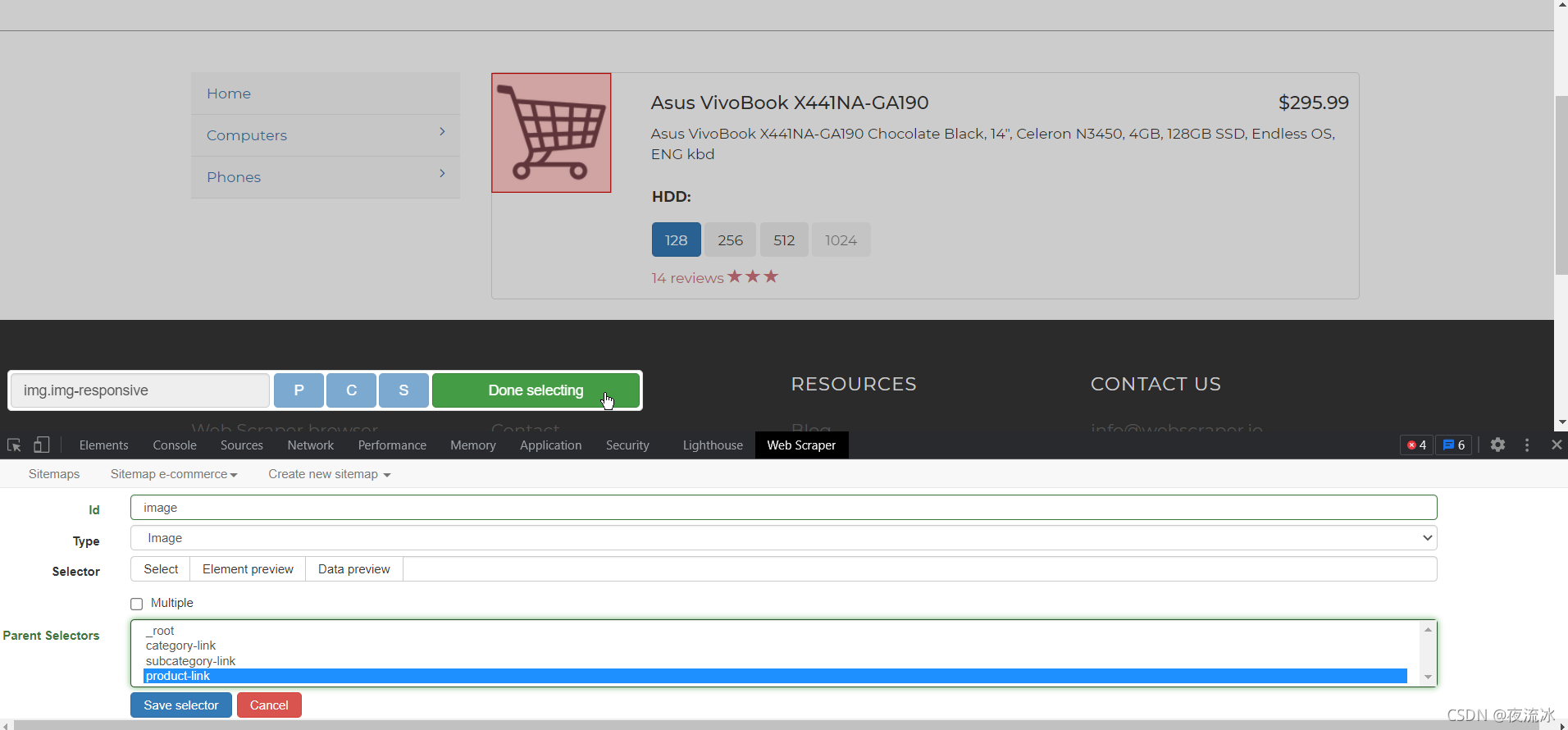
选择器创建完毕,让我们看一下,按照层级关系点开selectors,并随时点开选择器后面的Data preview查看数据是否正常。

还可以使用selectors graph查看我们创建的选择器的结构。


点击Scrape开始抓取数据,会看到新网页打开,按照我们设置的登录网址和选择器,浏览页面,提取数据。

休息一下,等待数据提取。
完成后会关闭弹出的网页,并有提示。
然后点击Refresh,显示提取的数据。
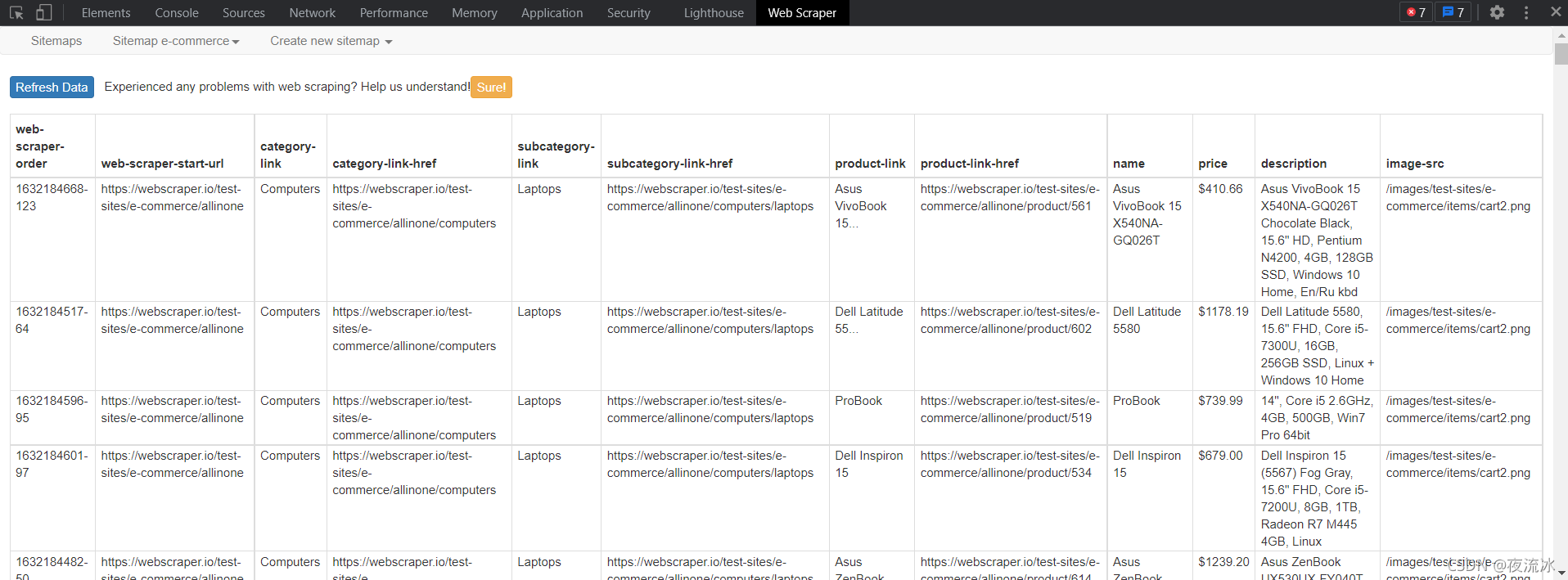
选择导出到CSV文件。

打开CSV文件,数据如下:
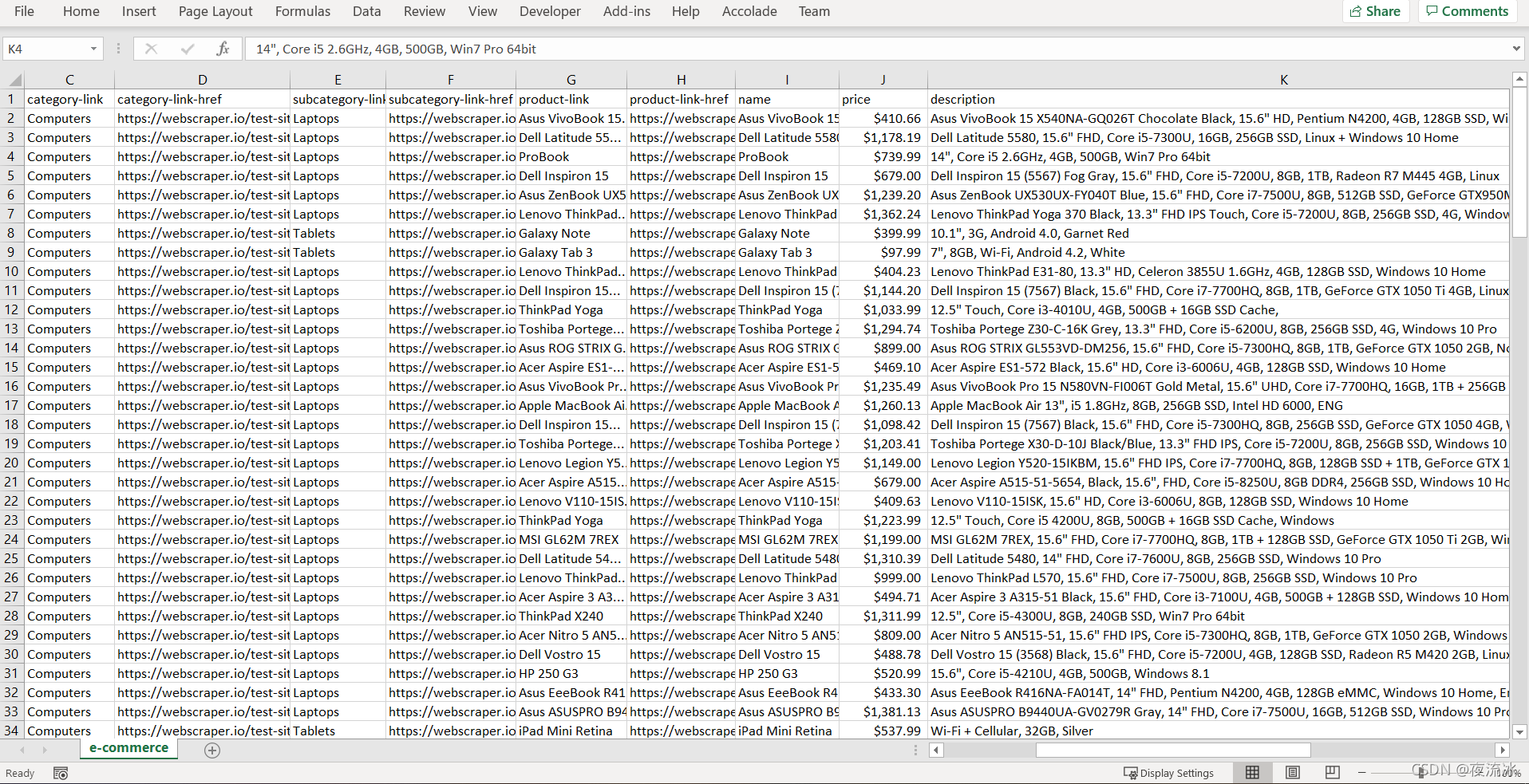
OK,CSV文件到手,告一段落。
点击Browse回到数据显示。

还可以导出Export Sitemap,将Sitemap JSON内容保存下来,下次创建Sitemap时直接导入,更加方便快捷。
如果有多个Sitemap,操作前可以选择或切换执行数据提取的Sitemap。