@R星校长
第3关:网页数据分析

任务描述
下图是2016年国防科技大学分数线的网页,在浏览器中我们可以看到,各省的最高分、最低分、平均分都整齐地排列自在表格中。一个网页的源代码时常有成百上千行,其中很多代码都是为了布局页面样式服务的,而我们时常关心的是网页上的数据,而并不关心样式代码。所以如何从冗长的网页源代码中提取我们关心的数据,是这一关我们将要一起学习和体验的内容。

相关知识
课程视频 1《网页数据 - 使用正则表达式提取数据》
上面的课程视频1介绍了如何使用正则表达式提取网页数据,下面通过文字进一步详细描述正则表达式在Python中的使用。
网页代码中的规律

河南省一本线、工程类最高分、最低分、平均分、合训类最高分最低分平均分分别为523,665,644,652,659,629,638。

用浏览器查看网页源代码,在河南这一行的表项中这些数据依次排列,而且省份和分数都在标签</span>前面。有关html表格的知识请参见背景知识。
Python内容匹配的re模块
re模块是Python的正则表达式模块,有关正则表达式的更多知识参见预背景知识,下面我们来介绍re模块的常用函数。
函数re.findall(pattern, string[, flags])
从string中查找所有符合pattern正则表达式模式的子串,以这些子串作为列表元素返回一个列表。
参数说明:
pattern:要搜寻的正则表达式;string:要检索的字符串;flag:可选项,可设置搜索的要求。可以选择输入
re.S,re.I等。re.S:如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将\n当做一个普通的字符加入到这个字符串中,在整体中进行匹配;re.I:忽略大小写。
下面给出了具体的使用示例:
# coding=utf-8
import re
string = 'o1n27m3k486'
pattern = r'[1-9]+'
print(re.findall(pattern, string))
输出结果:
['1', '27', '3', '486']
函数re.search(pattern,string,flags)
参数与re.findall()的参数意义相同。re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回MatchObject对象,如果字符串没有匹配,则返回None。
下面给出了具体的使用示例:
# coding=utf-8
import re
string = 'o1n27m3k486'
pattern = r'[1-9]+'
print(re.search(pattern, string).group(0))
输出结果:
1
函数re.compile(pattern,flags=0)
编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
参数与re.findall()、re.search()的参数意义相同。
下面给出了具体的使用示例:
# coding=utf-8
import re
string = 'o1n27m3k486'
pattern = r'[1-9]+'
obj = re.compile(pattern)
print(obj.findall(string))
输出结果:
['1', '27', '3', '486']
下面的课程视频2介绍了使用正则表达式提取网页中表格数据的方法。
课程视频 2《网页数据 - 表格数据提取》
编程要求
仔细阅读网页源代码信息,补全step3()函数。通过2016年国防科技大学分数线的网页源代码按省抽取最高分、最低分、平均分信息,并保存下来,具体任务如下:
- 按tr标签获取表格中所有行,保存在列表rows中;
- 迭代rows中的所有元素,获取每一行的td标签内的数据,并把数据组成item列表,将每一个item添加到scorelist列表;
- 将由省份,分数组成的8元列表(分数不存在的用/代替)作为元素保存到新列表score中。
注意:本关只要抽取具体的数值,该表中前三行分别为标题、类别和分数分类的具体描述,这三行的数据不需要保存。
测试说明
预期输出:
[['甘肃', '490', '632', '621', '625', '630', '597', '608'], ['吉林', '530', '658', '639', '649', '634', '599', '615'], ['新疆', '464', '673', '617', '630', '612', '534', '578'], ['广西', '502', '642', '601', '620', '603', '584', '592'], ['上海', '360', '489', '475', '480', '/', '/', '/'], ['广东', '508', '641', '600', '613', '619', '585', '597'], ['内蒙古', '484', '641', '615', '627', '623', '558', '597'], ['陕西', '470', '665', '628', '638', '639', '596', '615'], ['四川', '532', '665', '626', '643', '651', '612', '623'], ['黑龙江', '486', '667', '623', '641', '628', '580', '600'], ['安徽', '518', '655', '620', '631', '647', '608', '621'], ['河北', '525', '682', '654', '667', '669', '640', '649'], ['江西', '529', '645', '614', '629', '613', '589', '599'], ['浙江', '600', '692', '670', '679', '676', '652', '661'], ['湖南', '517', '662', '635', '644', '646', '593', '609'], ['宁夏', '465', '637', '565', '597', '590', '481', '526'], ['山东', '537', '679', '655', '665', '660', '597', '637'], ['河南', '523', '665', '644', '652', '659', '629', '638'], ['山西', '519', '639', '617', '625', '638', '579', '599'], ['天津', '512', '659', '634', '649', '600', '537', '567'], ['北京', '548', '662', '607', '629', '613', '570', '592'], ['重庆', '525', '671', '644', '655', '654', '634', '642'], ['云南', '525', '680', '653', '663', '663', '627', '639'], ['青海', '416', '596', '562', '580', '571', '502', '533'], ['江苏', '353', '404', '376', '386', '384', '355', '366'], ['福建', '465', '632', '614', '623', '606', '485', '576'], ['海南', '602', '829', '710', '750', '737', '672', '700'], ['贵州', '473', '671', '627', '643', '658', '600', '616'], ['辽宁', '498', '660', '624', '637', '641', '607', '621'], ['湖北', '512', '665', '622', '640', '637', '604', '614']]
开始你的任务吧,祝你成功!
# -*- coding: utf-8 -*-
import urllib.request as req
import re# 国防科技大学本科招生信息网中2016年录取分数网页URL:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html'webpage = req.urlopen(url) # 根据超链访问链接的网页
data = webpage.read() # 读取超链网页数据
data = data.decode('utf-8') # byte类型解码为字符串# 获取网页中的第一个表格中所有内容:
table = re.findall(r'<table(.*?)</table>', data, re.S)
firsttable = table[0] # 取网页中的第一个表格
# 数据清洗,将表中的 ,\u3000,和空格号去掉
firsttable = firsttable.replace(' ', '')
firsttable = firsttable.replace('\u3000', '')
firsttable = firsttable.replace(' ', '')def step3():score = []
# 请按下面的注释提示添加代码,完成相应功能,若要查看详细html代码,可在浏览器中打开url,查看页面源代码。
#********** Begin *********#
# 1.按tr标签对获取表格中所有行,保存在列表rows中:rows = re.findall(r'<tr(.*?)</tr>', firsttable, re.S)# 2.迭代rows中的所有元素,获取每一行的td标签内的数据,并把数据组成item列表,将每一个item添加到scorelist列表:scorelist = []for row in rows:items = []tds = re.findall(r'<td.*?>(.*?)</td>', row, re.S)for td in tds:rightindex = td.find('</span>') # 返回-1表示没有找到leftindex = td[:rightindex].rfind('>')items.append(td[leftindex+1:rightindex])scorelist.append(items)# 3.将由省份,分数组成的7元列表(分数不存在的用\代替)作为元素保存到新列表score中,不要保存多余信息for record in scorelist[3:]:record.pop()score.append(record)
####### End #######return score
# print("各省分数线如下:")
# print(step3())
# if step3() == step3():
# print("结果正确")
# else:
# print("结果错误")

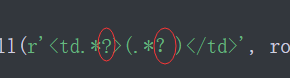
我 问号 敲错,输入中文问号,结果给我报错,查不出哪里出问题

写代码的时候一定要万分谨慎,马虎会让你多做事,浪费20%-50%的时间成本