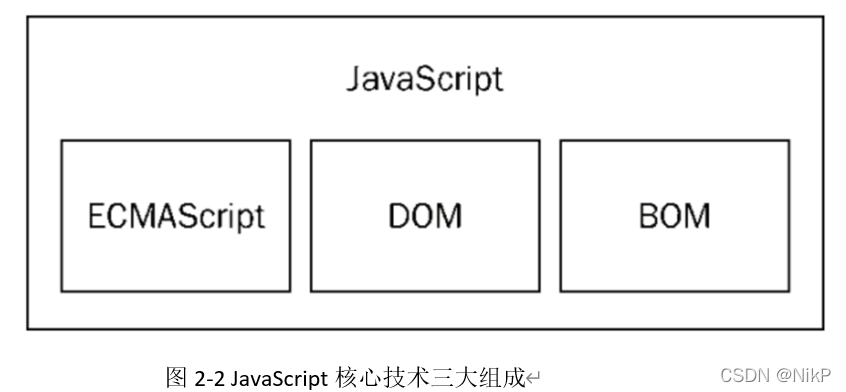
Web
知识框架
- 控制浏览器行为技术:HTML 、CSS 、JavaScript
- 控制硬盘上数据库行为技术:MySql数据库服务器管理使用(SQL重点)、JDBC规范
- 控制服务端Java行为技术:Http服务器、Servlet、JSP
- 互联网通信流程开发规则:MVC
- 贯穿项目-------在线考试管理系统
一、互联网通信流程
1.2 什么是互联网通信
- 两台计算机通过网络共享文件行为
1.3 互联网通信过程角色划分
- 客户端计算机:发送请求索要文件
- 服务端计算机:接收请求返回对应文件
1.4 互联网通信模型
- C/S:客户端/服务器
- 客户端:
- 客户端软件安装在客户端计算机
- 发送请求给指定的服务器索要文件
- 解析服务器返回的二进制数据
- 服务器:
- 服务器软件安装在服务器
- 接收特定的客户端请求
- 根据请求定位资源文件 编译成二进制通过网络返回
- 优点:安全性高、降低服务端工作压力
- 缺点:增加用户使用成本 更新较为繁琐
- 客户端:
- B/S:浏览器/服务器
- 浏览器:
- 安装浏览器在客户端计算机
- 发送请求到任意服务器 索要文件
- 解析服务器返回的二进制数据
- 服务器:
- 安装服务器软件在客户端计算机
- 可以接收任何的浏览器请求
- 定位资源以二进制形式通过网络发送到请求浏览器上
- 优点:几乎不会增加用户使用成本 几乎不用更新浏览器
- 缺点:几乎不能有效保护好服务器资源安全 使服务端计算机工作压力大
- 浏览器:
1.5 共享资源文件
- 能通过网络共享的文件 是共享资源文件
- Http服务器共享文件的分类:
- 静态资源文件:固定文件【图片、视频、文档等】文件内容存命令 只能在浏览器编译运行的【js、html、css】
- 动态资源文件:文件内容是命令 只能在服务器编译运行【class】
- 静态动态文件调用:
- 静态文件服务器直接通过输出流以二进制形式返回
- 动态文件服务器创建实例化对象 通过实例化对象调用对应方法 以二进制返回处理结果
1.6 开发人员在互联网通信流程担负职责
- 控制浏览器行为
- 开发动态文件解决用户请求
二、 HTML
2.2 介绍
- HTML编程语言只能在浏览器编译运行
- HTML又称为超文本标记式编程语言
2.3 作用
- 用指定方式将返回数据展示在浏览器窗口
- 控制浏览器的请求
2.4 HTML编程语言语法规范
- 只能在标签内
- 不区分大小写
- 命令是规定好 程序员不能创建命令 只能使用
- 标签分为 单目标签 双目标签
- 单目标签 可以省略’/’ 双目标签不能省略
- HTML命令开发是通过属性赋值实现开发目的 可以双引号 单引号 省略 空格间隔
2.5 控制浏览器请求三要素
- 请求地址
- 请求方式
- 请求携带参数
2.6 控制浏览器发送请求地址
-
<!--超链接标签命令--> <!--浏览器不会自动执行 需要用户用鼠标点击超链接标签命令 才会执行 按href地址发送请求--> <a href = "地址">提示信息</a> -
<!--表单标签命令--> <!--浏览器不会自动执行 需要用户用鼠标点击按钮 才会执行 按action地址发送请求--> <form action = "地址"><input type = "submit"><!--按钮--> </form>
2.7 控制浏览器发送请求采用请求方式
-
决定浏览器发送请求时行为特征
-
浏览器可以选择7种请求方式 目前只考虑 GET、POST请求方式
- GET:
- 携带请求参数数量不能超过4K
- 地址栏显示参数信息
- 参数保存在HTTP请求协议包的请求头中
- 返回的资源文件缓存在浏览器缓存中
- POST:
- 不限制携带参数数量
- 隐藏地址栏的参数信息
- 参数信息保存在HTTP请求协议包中的请求体中
- 返回资源文件不缓存 阅后即焚
- GET:
-
HTML控制请求方式:
- 超链接标签:必须是GET
- 表单标签:存在一个method属性 通过该属性可以要求浏览器采用对应请求方式 默认GET
2.8 请求方式适用场景【面试】
- 用户会上传病毒文件到服务器 绝大多数门户级网站拒绝POST请求方式 基本上都是GET
- 什么时候使用POST:
- 登录验证
- 文件上传
- 实时更新的数据
2.9 控制浏览器发送请求携带请求参数
-
请求参数格式:地址?参数名1=值&参数名2=值
-
携带参数来源:超链接标签、表单域标签
-
超链接标签:
<a href = "地址?参数名1=值&参数名2=值">提示信息</a> -
表单域标签:
<form action = "地址" method = "post"><input type = "text" name = "xxx"><!--下拉列表--><select name = "xx"><option value ="volvo">Volvo</option></select><!--多行输入文本框--><textarea rows="3" cols="20">输出</textarea><input type = "submit"> </form> <!--name属性是参数名 value是参数值-->
-
-
表单域标签value默认值:基本上是空字符串 radio和checkbox是"no"字符串
-
表单域标签作为参数的条件:
- 必须在>标签内
- 必须赋值name属性
- radio和checkbox必须选中
- 表单域标签使用【disabled】不能作为参数
-
【readOnly】只能看不能修改value值 还是请求参数
三、CSS
3.2 介绍
- 专门在浏览器编译运行的编程语言
- 用于定位浏览器的HTLM标签并对定位的标签进行【样式属性】的统一管理
3.3 HTML标签属性分类
- 基本属性:id name等
- 样式属性:style
- 工作状态属性:
- readOnly:只读状态 可以做参数
- checked:radio和checkbox是否选中
- disabled:不可用 不可做参数
- selected:存在option标签 是否被选中
- 监听属性:监听用户对当前标签是否进行操作 通知浏览器调用对应javaScript方法处理
3.4 样式属性开发难度
- 大量标签拥有同样样式属性
- 如果用户修改业务 需要前端工程师大量重复维护工作
3.5 CSS选择器
- 九种分类
- 语法格式:
<html><head><style type = "text/css">定位条件{"样式属性1":"值";"样式属性2":"值"}</style></head>
</html>
- ID选择器:【#id】
- 标签类型选择器 :【标签类型名】
- 层次选择器:【定位条件1 定位条件2】
- 自定义选择器:需要在标签给class属性赋值 【.class】
四、mysql
4.1 表文件数据行的管理
- 插入命令:insert into 表名(,) values(,)
- 查询命令:select * from 表名
- 删除命令:delete from 表名 where 条件
- 更新命令:update 表名 set 字段="" where 条件
- 删除命令不能和查询命令操作同一张表
4.2 查询命令详解
-
as 别名 也可以省略 空格即可
-
WHERE 遍历临时表 判断 创建新临时表保存符合数据行
-
GROUP BY 有机会在内存中生成多个临时表
-
HAVING 不会生成新临时表 负责将GROUP BY生成的临时表中不满足条件的临时表从内存中进行删除处理
-
临时表由group by提供 可能有多张临时表 聚合函数select只会读取指定字段的第一行 合成新的临时表
-
多字段分组 从第二个分组字段操作的是上一个分组字段的生成的临时表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yyqHjuBJ-1635209667676)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20211024161937954.png)]
4.3 多表查询
-
一方表 多方表
- 外键字段只存在多方表
-
多表查询就是两张表合成一张临时表进行查询
- 连接查询合并方案 水平连接 两个表需要【隶属关系】
- 一方表 join 多方表 on 合法数据条件
- 联合查询合并方案 垂直连接
- 查询语句1 union 查询语句2
- 以第一个查询语句为表头
- union all 不会对重复的过滤
- 子查询
五、jdbc
- javaEE需要与服务器进行沟通
- 13种服务器接口规范的一种
5.1 使用
String sql_1 = "select * from student";
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","root");
ps = conn.prepareStatement("sql语句");
rs = ps.executeQuery();
while(rs.next()){String id = rs.getString("id");String name = rs.getString("name");Integer age = rs.getInt("age");System.out.println(id+name+age);
}//预编译一次执行多个sql语句
String sql_1 = "insert into student(name,age) values (?,?)";
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","root");
ps = conn.prepareStatement(sql_1);
ps.setString(1,"D1");
ps.setInt(2,10);
ps.addBatch();
ps.setString(1,"D2");
ps.setInt(2,20);
ps.addBatch();
ps.executeBatch();//事务
Connection conn = null;
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","root");
conn.setAutoCommit(false);//开启事务
conn.commit();//提交事务
conn.rollback();//回滚事务
5.2 互联网流程图第二版
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dG4fODO6-1635209667680)(G:\复习\web\06-Http协议与Tomcat\01-文档\第二版互联网通信流程图.png)]](https://img-blog.csdnimg.cn/6bc7ae840c14478fbaeb5440a1e316c8.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA562R5qKmIyM=,size_20,color_FFFFFF,t_70,g_se,x_16)
六 、Http网络协议、tomcat
6.1 知识框架
- 网络协议包
- http网络协议包
- tomcat
6.2 网络协议包
-
网络中传输的都是二进制数据 接收方收到二进制信息第一时间编译成对应【文字、视频、图片等】
- 传递信息数据往往比较大 导致接收方很难在一组连续的二进制获得相关信息
- 网络协议包时一组有规律的二进制数据 数据中有固定空间 固定空间存放特定信息
- 接收方接收到网络协议包 就可以在固定空间获得相关信息
- 降低了接收方接收二进制数据编译难度
-
常见FTP、HTTP
6.3 HTTP网络协议包
- 请求协议包:浏览器准备发送请求 创建 将请求信息以二进制放入请求协议包各个空间 推送给服务器
- 请求行:url请求地址 method请求方式
- 请求头:get请求参数
- 空白行:没有信息 隔离作用
- 请求体:post请求参数
- 响应协议包:服务器定位到资源文件 创建 将定位文件内容以二进制放入响应协议包各个空间 推送给浏览器
- 状态码:HTTP状态码
- 响应头:content-type 指定浏览器采用对应编译器对响应体二进制数据进行解析
- localhost地址
- 空白行:没有信息 隔离作用
- 响应体:返回数据 以二进制存放
6.4 tomcat
- 安装
- 配置环境
- 启动
七、servlet
7.2 介绍
- javaEE规范的一种
- 作用:指定动态资源文件开发步骤、调用动态资源文件规则、动态资源文件实例对象管理
- Servlet接口存在Tomcat的lib下servlet-api.jar
- 调用动态资源文件必须是一个Servlet接口实现类
7.3 开发步骤
-
创建java类继承HttpServlet类
-
实现HttpServlet的doGet或doPost方法
-
将Servlet实现类信息注册到Tomcat
<servlet><servlet-name></servlet-name><!--别名--><servlet-class></servlet-class><!--Servlet接口实现类全限定名--><load-on-startup>30<load-on-startup><!--填一个大于0的整数 服务器启动时创建实例对象--> </servlet> <servlet-mapping><servlet-name></servlet-name><!--别名--><url-pattern></url-pattern><!--访问别名前面必须‘/’开头--> </servlet-mapping>
- Servlet生命周期:默认浏览器第一次访问时创建
- 可以手动设置服务器启动时创建
- 服务器运行期间 一个实现类 只能创建一个是实例化对象
- 服务器关闭时销毁所有实例对象
- 网站中所有实例对象只能Http服务器创建
7.4 HttpServletRequest、HttpServletResponse接口
-
实现类由服务器提供
-
HttpServletRequest:请求对象 获取请求协议包的信息
- 请求行
- 请求头、请求体:请求参数
- 代替浏览器向服务器申请资源文件调用
-
HttpServletResponse:响应对象 将处理信息写入响应协议包
- 响应头:设置content-type属性控制浏览器采用对应的编译器
- 设置location属性 赋值请求地址 控制浏览器向指定服务器发起请求
- 响应体:将处理信息二进制写入
- 响应头:设置content-type属性控制浏览器采用对应的编译器
- 生命周期:
- 服务器收到请求协议包 生成请求对象 响应对象
- 服务器调用doGet、doPost方法 负责将请求、响应对象作为实参传入
- 在服务器推送响应协议包之前 销毁
7.5 欢迎资源文件
- Tomcat安装位置/conf/web.xml
<!--默认欢迎资源文件-->
<welcome-file-list><welcome-file>index.html</welcome-file><welcome-file>index.htm</welcome-file><welcome-file>index.jsp</welcome-file>
</welcome-file-list>
- 设置资源文件 Tomcat服务器自带定位失效
<welcome-file-list><welcome-file>login.html</welcome-file><!--默认访问欢迎资源文件-->
</welcome-file-list>
7.6 状态行
100:不是独立资源文件 根据响应包 继续向服务器索要依赖资源文件
200:返回完整独立资源文件
302:返回资源文件地址 浏览器继续通过该地址自动发起请求
404:定位不到资源文件
405:定位到对应Servlet实现类 但是没有对应请求方法
500:Servlet可以接收请求方式 但是处理请求发生java异常
7.7 多个Servlet之间调用规则
-
浏览器发送请求往往需要多个Servlet协同处理
- 用户需要发起多次请求 降低服务质量
-
重定位解决方案
- 工作原理:用户第一次手动访问 Tomcat因location 将302写入状态行
- 浏览器根据302状态行 浏览器自动根据location地址发起第二次请求
- 实现命令:用响应对象将地址写入响应头的location属性【 response.sendRedirect(“请求地址”)】
- 特征:本网站、别的服务器的资源文件【/网站名/资源文件名】【http://ip地址:端口号/网站名/资源文件名】
- 请求方式最少两次 第一次手动 第二次自动
- 地址栏发起请求 GET
- 缺点:在浏览器和服务器之间往返多次 大量时间消耗在往返次数上 增加用户等待时间
- 工作原理:用户第一次手动访问 Tomcat因location 将302写入状态行
-
请求转发解决方案
-
工作原理:请求对象代替浏览器向服务器发起请求
-
实现命令:
//1.通过当前请求对象生成资源文件申请报告对象 RequestDispatcher report = request.getRequestDispatcher("/资源文件名");//一定要以"/"为开头 //2.将报告对象发送给Tomcat report.forward(当前请求对象,当前响应对象); //简化 request.getRequestDispatcher("/资源文件名").forward(当前请求对象,当前响应对象) -
优点:Servlet之间的调用在服务器内 节省了服务器 浏览器之间的往返
-
特点:发起一次请求
- 只能访问本网站下的资源文件
- 浏览器只发起了一次请求 共享请求对象 响应对象 所以请求方式是一致的
-
7.8 多个Servlet之间共享数据方案
7.9.1 全局 ServletContext接口
-
两个Servlet来自同一个网站
-
相当全局共享的一个Map
-
生命周期:服务器启动时创建一个全局作用域对象
- 服务器运行期间 一个网站只有一个全局作用域 一直存活
- 服务器关闭时销毁
-
实现命令:
//通过请求对象向服务器索要全局作用域 ServletContext application = request.getServletContext(); //往全局作用域添加数据application.setAttribute("key1",数据); //获取数据 application.getAttribute("key1");
7.9.2 会话 HttpSession接口
-
两个Servlet来自于同一个网站,并且为同一个浏览器/用户提供服务
-
存放在服务器计算机内存 相当于一个Map
-
服务器如何把用户和HttpSession关联起来 返回 Cookie的手牌 缓存在浏览器中 下次请求 携带手牌
-
实现命令:
resp.getSession();//如果该用户没有会话对象 会创建
resp.getSession(false);//如果该用户没有会话对象 不会创建 返回null
session.setAttribute("key","值");//添加数据
session.getAttribute("key");//获取value数据
-
销毁时机:
-
用户与会话作用域 通过Cookie关联
- Cookie存放在浏览器缓存 浏览器关闭 就失联
- 服务器不能判断浏览器何时关闭
- 服务器为会话对象默认设置一个空闲时间 超过销毁 默认30分钟
-
手动设置空间时间
-
/web/WEB-INF/web.xml
<session-config><session-timeout>5</session-timeout> <!--当前网站中每一个session最大空闲时间5分钟--> </session-config>
-
-
7.9.3 请求 HttpServletR接口
- 通过请求转发共享一个请求对象
- 实现命令:
//将数据添加进请求对象的Attribute属性中
req.setAttribute("key",数据); //数据类型可以任意类型Object
req.getAttrubute("key");//获取数据value
7.9.4 Cookie 类
-
两个Servlet来自同一个网站 为同一个浏览器/用户服务
-
将Cookie写入到响应头 返回浏览器cookie存储在浏览器的缓存
- 再次访问Cookie写入请求头中发送过去 Servlet就可以获取Cookie
-
实现命令:
Cookie cookie = new Cookie("key","value");//一个Cookie只能存一个键值对 cookie.setMaxAge(秒);//设置Cookie存活时间 resp.addCookie(cookie);//写入响应头 可以写入多个 Cookies[] cookies = req.getCookies();//获取请求头中Cookie数组 for(Cookie c:cookies){c.getName();//获取keyc.getValue();//获取value } -
生命周期:
- 存在浏览器缓存中 浏览器关闭就销毁
- 手动设置Cookid对象的存活时间 存放在计算机硬盘上 关闭浏览器 服务器 计算机 都不会销毁
- 直到存活时间到 自动销毁
7.9 监听器
- 服务器提供jar包并没有对应的实现类
- 监听器接口用于监控【作用域对象生命周期变化时刻】以及【作用域对象共享数据变化时刻】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sw3udvDR-1635209667684)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20211025225038392.png)]](https://img-blog.csdnimg.cn/64ac53cf192c4d5485c25154a0e670f8.png)
-
方法
public void contextInitlized();//在全局作用域对象被Http服务器初始化被调用 public void contextDestory();//在全局作用域对象被Http服务器销毁时候触发调用public void contextAdd();//在全局作用域对象添加共享数据 public void contextReplaced();//在全局作用域对象更新共享数据 public void contextRemove();//在全局作用域对象删除共享数据 -
注册到Tomcat服务器
<listener><listener-class></listener-class><!--监听实现类全限定名称-->
</listener>
7.10 过滤器
-
介绍:Filter接口在Http服务器调用文件之前 对服务器进行拦截过滤
- 服务器不提供Filter接口实现类 需要开发人员手动实现
-
作用:拦截服务器 检测请求是否合法 对当前请求进行增强操作
-
开发实现:
-
创建类实现接口Filter
-
实现接口doFilter方法
void init(FilterConfig config);//用于完成Filter 的初始化。 void destroy();//用于Filter 销毁前,完成某些资源的回收 //实现过滤功能,该方法就是对每个请求及响应增加的额外处理 void doFilter(ServletRequest request, ServletResponse response,FilterChain chain); -
将接口实现类注册到Tomcat服务器
<filter><filter-name></filter-name><!--别名--><filter-class></filter-class><!--Filter接口实现类全限定名--> </filter> <filter-mapping><filter-name></filter-name><!--别名--><!--拦截地址指定文件【/xxx.xx】指定目录下【/xx/*】指定文件后缀【*.xxx】 网站下所有【/*】--><url-pattern></url-pattern></filter-mapping>
-