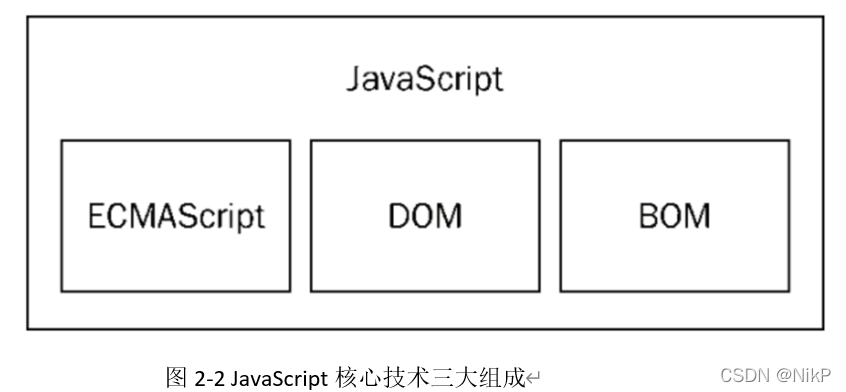
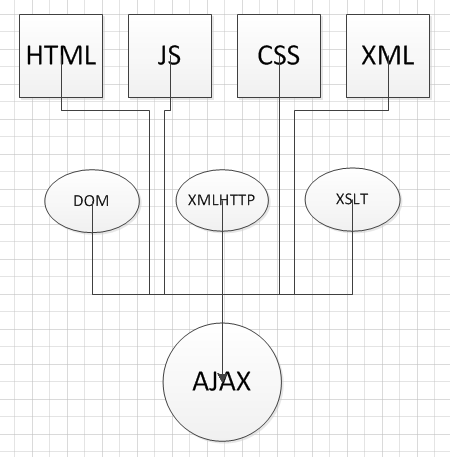
定义:
本意是蜘蛛网和网的意思,在网页设计中我们称为网页的意思。现广泛译作网络、互联网等技术领域。表现为三种形式,即超文本(hypertext)、超媒体(hypermedia)、超文本传输协议(HTTP)等。
-
超文本是一种用户接口方式,用以显示文本及与文本相关的内容(日常浏览的网页都属于超文本)
-
超媒体是超文本(hypertext)和多媒体在信息浏览环境下的结合。超级媒体的简称,用户不仅能从一个文本跳到另一个文本,而且可以激活一段声音,显示一个图形,甚至可以播放一段动画。
-
超文本传输协议(HTTP)HyperText Transfer Protocol超文本在互联网上的传输协议。
一、Web的发展历史
1、Web的起源
Web是World Wide Web的简称,中文称之为万维网,是用于发布、浏览、查询信息的网络信息服务系统,由许多遍布在不同地域内的Web服务器有机地组
成。
Web的不断完善都是基于各种Web技术的不断发展,Web的应用架构是由英国人Tim Berners-Lee在1989年提出的,而它的前(nian2 ti2 chu1 de0 _er2 ta1 de0 qian2)身是1980年Tim Berners-Lee负责的Enquire(Enquire Within Upon Everything的简称)项目。1990年11月第一个Web服务器nxoc01.cern.ch开始运行,由Tim Berners-Lee编写的图形化Web浏览器第一次出现在人们面前。1991年,CERN(European Particle Physics Laboratory)正式发布了Web技术标准。目前,与Web相关的各种技术标准都由著名的W3C组织(World Wide Web Consortium)管理和维护。
- 前端:网页上位用户呈现的部分
- 开发:编写代码
- 后端:与数据库 进行交互,完成数据存取

web开发种类:

网页开发:

网页效果图:

网页代码实现:

二、Web前端开发历程
1、World Wide Web 万维网(常指网页和网站),从1989年 - 2019年发展至今仅30年。
现在生活中与我们息息相关的App手机软件:

2、Sir Tim Berners-Lee蒂姆:伯纳斯-李爵士:万维网的发明者,是英国计算机科学家,南安普顿大学与麻省理工学院教授。1990年12月25日,罗伯特·卡里奥在CERN和他一起成功通过Internet实现了HTTP代理与服务器的第一次通讯。

3、发展历程:
起初的通信方式:


(1)1989年,Tim Berners-Lee 提出了World Wide Web的设计方案

(2)1990年 Tim Berners-Lee 完成了web所需的所有工具,并于1991年对外发布

(3)1991年 欧洲核子研究组织(CERN)对外发布的首页站点

(4)1993年4月,CERN宣布任何人都可以使用Web协议和代码免版税
(5)1994年10月,Tim Berners-Lee在MIT成立W3C

(6)

(7)1993年,Marc Andreessen 和 Eric Bina@UIUC 研发世界第一款流行浏览器 Mosaic


(8)1998年,IE市场占有率超过Netscape,并在2002年达到96%,第一次浏览器大战结束。

(9)2000年左右,雅虎等公司开始设立前端工程师职位。
(10)2005年,Ajax应用于 Gmail、Goole Maps。
(11)2009年,百度、阿里、腾讯 设立前端工程师职位。
3. (1)Web 1.0, 只读的互联网时代*
19世纪中期(1996年),HTML的出现推动了家用计算机的普及以技术创新为主导,注重点击浏览,通过门户整合,用户以流量为主,以网页制作为主,大多是静态页面,也有动态页面。
静态内容的网站:HTML技术,主要是文本和图片(包括gif动态图片)。
特点:简单,只能做信息的展示,无法同用户进行交互。
最早的动态网站:主要采用CGI/Perl脚本技术,能够实现内容动态,具备了交互性,服务器能够访问文件系统或数据库。
缺点:伸缩性差(为每个请求分配一个新的进程)、安全性差(直接使用系统环境变量和文件系统)、脚本组织混乱并且缺少一种结构化的构造动态应用程序的方式。
(2)Web 2.0 交互的互联网时代
大约在2004年左右,诞生了WEB2.0的概念,更注重用户的交互作用,用户既是浏览者,也是内容的制造者,在模式上有单纯的“读”向“写”以及共同建设发展。
(3)Web 3.0 聚合的互联网时代
WEB3.0是一个正在尝试概念,用户拥有自己的数据,并能在不同平台交互共享,强化虚拟货币及网络安全和网络财富的共识,以及语义化的实现。