前言
当我们还没有接触Web时,可能处理的都是静态网页如Html,这个网页的数据都是直接写在标签里写死的,那么如果我们要做类似淘宝的一个网站,数据每天都会更新,那么静态网页就不支持了,就需要从数据库里去拿数据,来用动态网页解决,也就是Web技术。
什么是Web技术呢?
Web称为网页,该技术分为Web服务器端和Web客户端,Web应用中的每一次信息交换都要涉及客户端和服务端,客户端也就是浏览器和服务器交互的技术称为Web技术。
理解B/S架构
1.概念
当我们去开发一个Web应用程序时,如,在线购物,网上银行,用户只需打开一个浏览器,不需要安装任何其他软件,就可以轻松搞定,这种被广泛应用的Web应用程序(Web技术)就是B/S架构。
2.工作原理
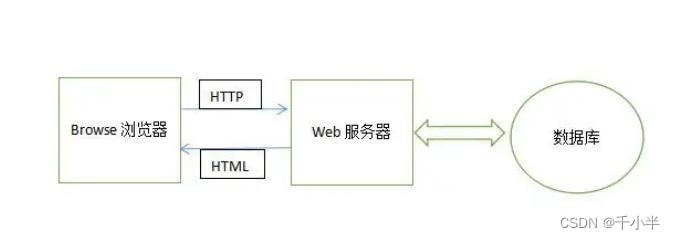
在B/S架构中,浏览器和服务器采用请求/响应模式进行交互,浏览器通过http协议向web服务器发送一个请求,服务器去数据库拿数据,拿到数据后以html的形式或jsp动态网页的形式响应到浏览器,浏览器进行解析,页面显示。
3.优点
- 用户访问简单: 用户不需要安装复杂的软件,只需要一个浏览器即可。
- 维护升级快捷 :当系统升级时,只需升级服务器端的代码,最后发送到客户端。
- 开发的跨平台性 : 相对于C/S架构而言,它必须安装软件,用户才可以使用,但B/S架构可以很好的做到跨平台的支持。
URL
1. 什么是URL?
URL被称为统一资源占位符,用于完整的描述网页资源地址的一种标识方法,分为静态资源和动态资源,URL就是网址。
2.URL的组成
- 协议 : 一般使用HTTP超文本传输协议,该协议支持简单的请求和响应会话,用来保持浏览器和服务器之间的通信。
- 服务器名称或IP地址 :localhost就代表本地的服务器地址,也可以使用IP地址替代,如果是企业级网站可以用域名代替IP地址。
- 端口号 : 服务器的端口号,TomCat服务器的端口号是8080。
- 路径 : 该Web应用的上下文路径,如: JSP或html等。
示例
http://localhost:8080/hello.jsp
Http协议
1.GET方法和POST方法
- 在客户端和服务端之间通过HTTP进行请求/响应时,GET和POST是两个最常用到的方法,其中,GET方法主要用来从指定资源中获取数据,POST方法主要用于向指定资源提交需要处理的数据。
Get方法
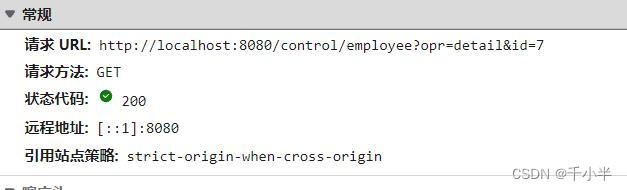
- get请求将数据(用户需要发送给服务器的数据)放在请求的URL中发送
/test/index.jsp?name1=value&name2=value;
get发送的请求的参数跟在?后面表示,多个参数使用&连接。
使用get发送的格式:
Post方法
- post请求将数据放在请求体中发送,不会跟在URL后面。
使用post发送的格式: 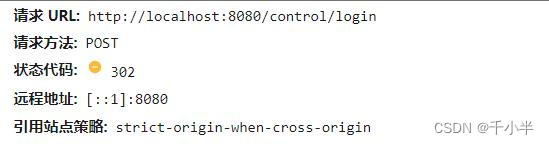
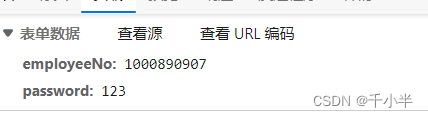
post请求的参数写在请求体里
对比get和post
| 对比方面 | GET方法 | POST方法 |
| 对数据长度的限制 | 传送数据量较小,不能大于2KB | 传送数据量无限制 |
| 数据可见性 | 数据在URL中对所有人都是可见的 | 数据不会显示在URL中 |
| 安全性 | 安全性低 | 安全性高 |
| 缓存 | 能被缓存 | 不能被缓存 |
3.状态码
在浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头,用以响应浏览器的请求。
HTTP常见状态码:
| 状态码及消息 | 描述 |
| 200 OK | 请求成功 |
| 302 Found | 所请求的页面已经转移至新的URL中 |
| 400 Bad Request | 服务器未能理解请求(客户端传递的参数不对等等) |
| 404 Not Found | 服务器无法找到请求的页面(路径不对) |
| 500 | 请求未完成(服务器出错) |
TomCat服务器
1.简介
我们大概已经了解到Web应用的执行原理和一些交互方式,大家也知道服务器中保存着网页或数据等,浏览器是通过请求去拿,那么我们用什么服务器呢?
这里我用的是Apache旗下的一个Tomcat服务器,是一个免费开源的容器,目前也很流行。
2.下载地址
Apache Tomcat® - Apache Tomcat 8 Software Downloads https://tomcat.apache.org/download-80.cgi
https://tomcat.apache.org/download-80.cgi
3.TomCat目录介绍
| /bin | 存放各种平台下用于启动和停止TomCat的脚本文件(各种指令) |
| /conf | 存放TomCat服务器的各种配置文件 |
| /lib | 存放TomCat服务器所需的jar文件 |
| /logs | 存放日志文件 |
| /webapps | Web应用的发布目录 |
| /work | 存放JSP生成的Servlet |
4.TomCat服务器部署Web应用
1.在webapps目录中,创建Web应用项目
2.注意Web项目格式

| / | Web应用的根目录,WEB-INF的上一级 |
| /WEB-INF | 存放各种资源,注意: 客户端对该目录和子目录都不可以直接访问 |
| /WEB-INF/classes | 存放Web应用的所有.class文件 |
| /WEB-INF/lib | 存放jar包 |
| /WEB-INF/web.xml | Web应用的核心配置文件。 |
注意: /WEB-INF的上一级用来定义页面,默认访问index.jsp
3.编写Web应用的代码 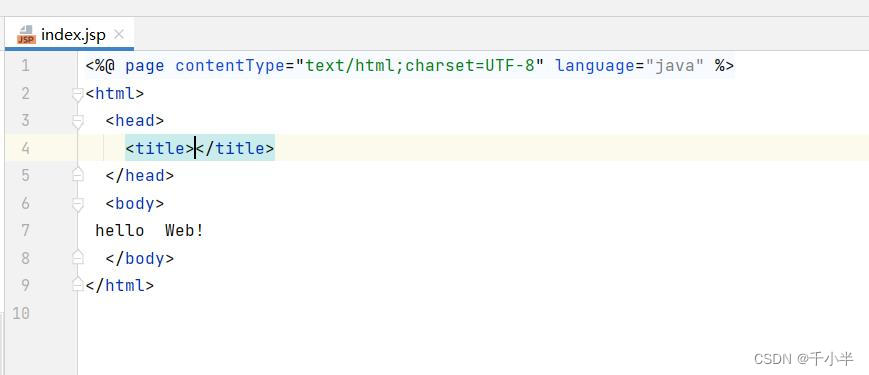
4./bin目录下点击startup.bat启动服务器
输入URL显示页面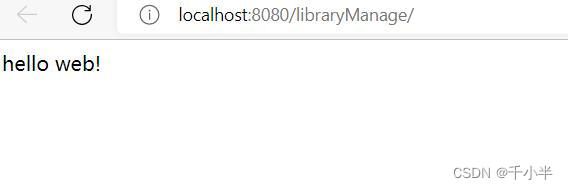
注意: 我们可以看到上面的地址为url组成地址,http 会自动添加,所以没有显示,librartMange是项目名称,/底下没有页面地址是因为index.jsp动态页面为自动显示。
5./bin目录下点击shutdown.bat关闭服务器
5.使用idea来部署Web应用
1.新建普通java项目
2.项目右击点击Add FrameWork support(添加框架支持) 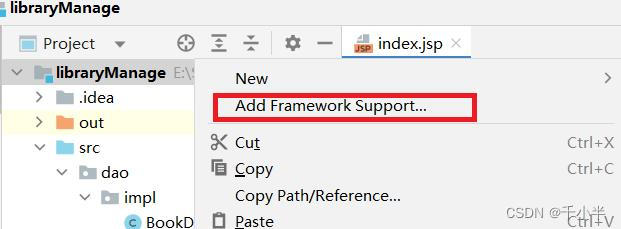
3.勾选 Web application(部署了一个Web项目)
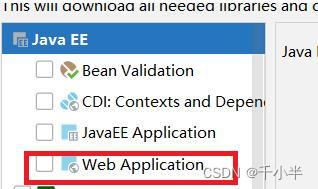
4.点击Edit ...部署Tomcat服务器