爬虫的目标
爬取猫眼电影TOP100的电影名称,时间,评分,图片等信息
抓取分析
查看网页源代码,找到对应的目标信息,发现一部电影对应的源代码是一个dd节点
抓取首页
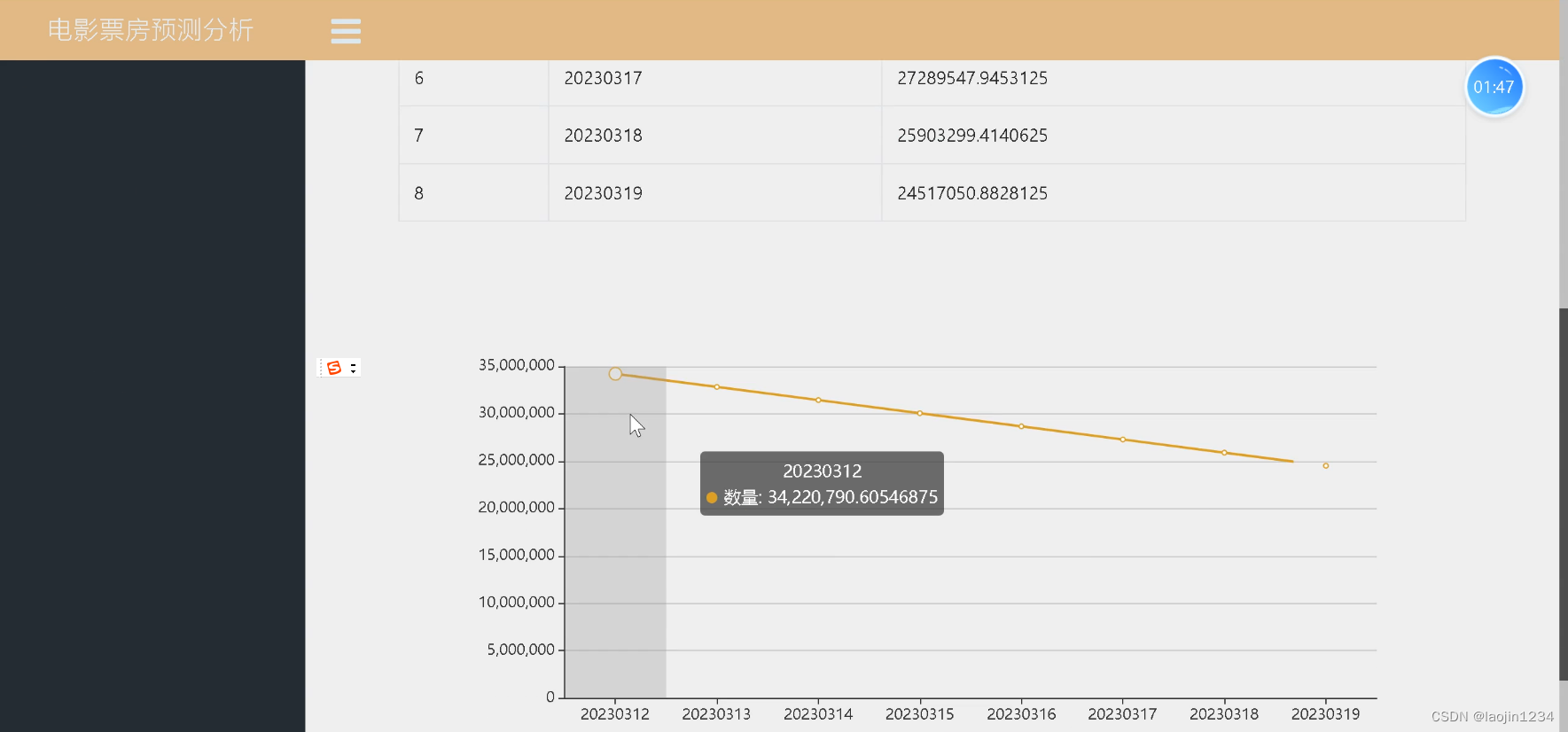
为了方便,这里先抓取第一页的内容,运行之后,可以查看到网页的源代码,之后需要对页面进行解析。
import requests
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
} #头信息,爬取一些网站时需要加上,否则可能会爬取失败
response = requests.get(url,headers=headers)
if (response.status_code==200):
return response.text #返回网页内容
return None
def main():
url = 'http://www.maoyan.com/board/4'