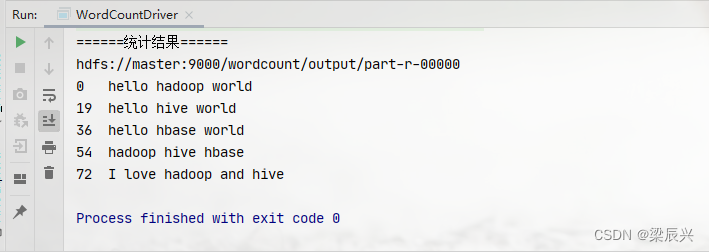
http://maiqiuzhizhu.blog.sohu.com/110325150.html
wavedec2函数:
1.功能:实现图像(即二维信号)的多层分解.
多层,即多尺度.
2.格式:[c,s]=wavedec2(X,N,'wname')
[c,s]=wavedec2(X,N,Lo_D,Hi_D)(我不讨论它)
3.参数说明:对图像X用wname小波基函数实现N层分解,
这里的小波基函数应该根据实际情况选择,具体选择办法可以搜之.输出为c,s.
c为各层分解系数,s为各层分解系数长度,也就是大小.
4.c的结构:c=[A(N)|H(N)|V(N)|D(N)|H(N-1)|V(N-1)|D(N-1)|H(N-2)|V(N-2)|D(N-2)|...|H(1)|V(1)|D(1)]
可见,c是一个行向量,即:1*(size(X)),(e.g,X=256*256,then c大小为:1*(256*256)=1*65536)
A(N)代表第N层低频系数,H(N)|V(N)|D(N)代表第N层高频系数,分别是水平,垂直,对角高频,以此类推,到H(1)|V(1)|D(1).
s的结构:是储存各层分解系数长度的,即第一行是A(N)的长度,第二行是H(N)|V(N)|D(N)|的长度,第三行是
H(N-1)|V(N-1)|D(N-1)的长度,倒数第二行是H(1)|V(1)|D(1)长度,最后一行是X的长度(大小)
那么S有什么用呢?
s的结构:是储存各层分解系数长度的,即第一行是A(N)的长度(其实是A(N)的原矩阵的行数和列数),
第二行是H(N)|V(N)|D(N)|的长度,
第三行是
H(N-1)|V(N-1)|D(N-1)的长度,
倒数第二行是H(1)|V(1)|D(1)长度,
最后一行是X的长度(大小)

从上图可知道:cAn的长度就是32*32,cH1、cV1、cD1的长度都是256*256。
到此为止,你可能要问C的输出为什么是行向量?
1、没有那一种语言能够动态输出参数的个数,更何况C语言写的Matlab
2、各级详细系数矩阵的大小(size)不一样,所以不能组合成一个大的矩阵输出。
因此,把结果作为行向量输出是最好,也是唯一的选择。
另:MATLAB HELP 里面说得非常明白了,呵呵.
wavedec2
Multilevel 2-D wavelet decomposition Syntax [C,S] = wavedec2(X,N,'wname')
[C,S] = wavedec2(X,N,Lo_D,Hi_D)
Description wavedec2 is a two-dimensional wavelet analysis function.
[C,S] = wavedec2(X,N,'wname') returns the wavelet decomposition of the matrix X at level N, using the wavelet named in string 'wname' (see wfilters for more information).
Outputs are the decomposition vector C and the corresponding bookkeeping matrix S. N must be a strictly positive integer (see wmaxlev for more information).
Instead of giving the wavelet name, you can give the filters. For [C,S] = wavedec2(X,N,Lo_D,Hi_D), Lo_D is the decomposition low-pass filter and Hi_D is the decomposition high-pass filter.
Vector C is organized as C = [ A(N) | H(N) | V(N) | D(N) | ... H(N-1) | V(N-1) | D(N-1) | ... | H(1) | V(1) | D(1) ]. where A, H, V, D, are row vectors such that A = approximation coefficients H = horizontal detail coefficients V = vertical detail coefficients D = diagonal detail coefficients Each vector is the vector column-wise storage of a matrix.
Matrix S is such that S(1,:) = size of approximation coefficients(N) S(i,:) = size of detail coefficients(N-i+2) for i = 2, ...N+1 and S(N+2,:) = size(X)
Examples% The current extension mode is zero-padding (see dwtmode).
% Load original image.
load woman;
% X contains the loaded image.
% Perform decomposition at level 2
% of X using db1.
[c,s] = wavedec2(X,2,'db1');
% Decomposition structure organization.
sizex = size(X)
sizex =
256 256
sizec = size(c)
sizec =
1 65536
val_s = s
val_s =
64 64
64 64
128 128
256 256
Algorithm For images, an algorithm similar to the one-dimensional case is possible for two-dimensional wavelets and scaling functions obtained from one-dimensional ones by tensor product. This kind of two-dimensional DWT leads to a decomposition of approximation coefficients at level j in four components: the approximation at level j+1, and the details in three orientations (horizontal, vertical, and diagonal). The following chart describes the basic decomposition step for images: So, for J=2, the two-dimensional wavelet tree has the form See Alsodwt, waveinfo, waverec2, wfilters, wmaxlev ReferencesDaubechies, I. (1992), Ten lectures on wavelets, CBMS-NSF conference series in applied mathematics. SIAM Ed. Mallat, S. (1989), "A theory for multiresolution signal decomposition: the wavelet representation," IEEE Pattern Anal. and Machine Intell., vol. 11, no. 7, pp. 674-693. Meyer, Y. (1990), Ondelettes et opérateurs, Tome 1, Hermann Ed. (English translation: Wavelets and operators, Cambridge Univ. Press. 1993.