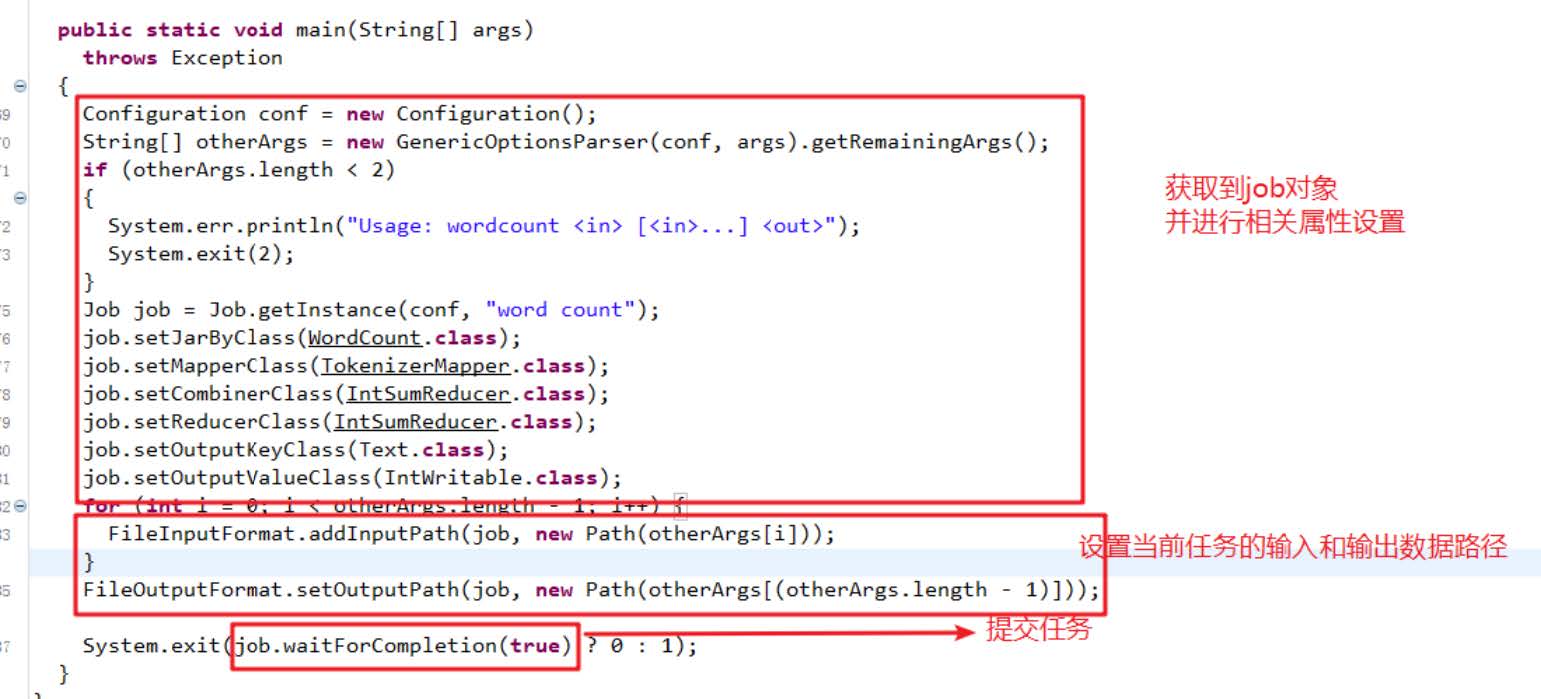
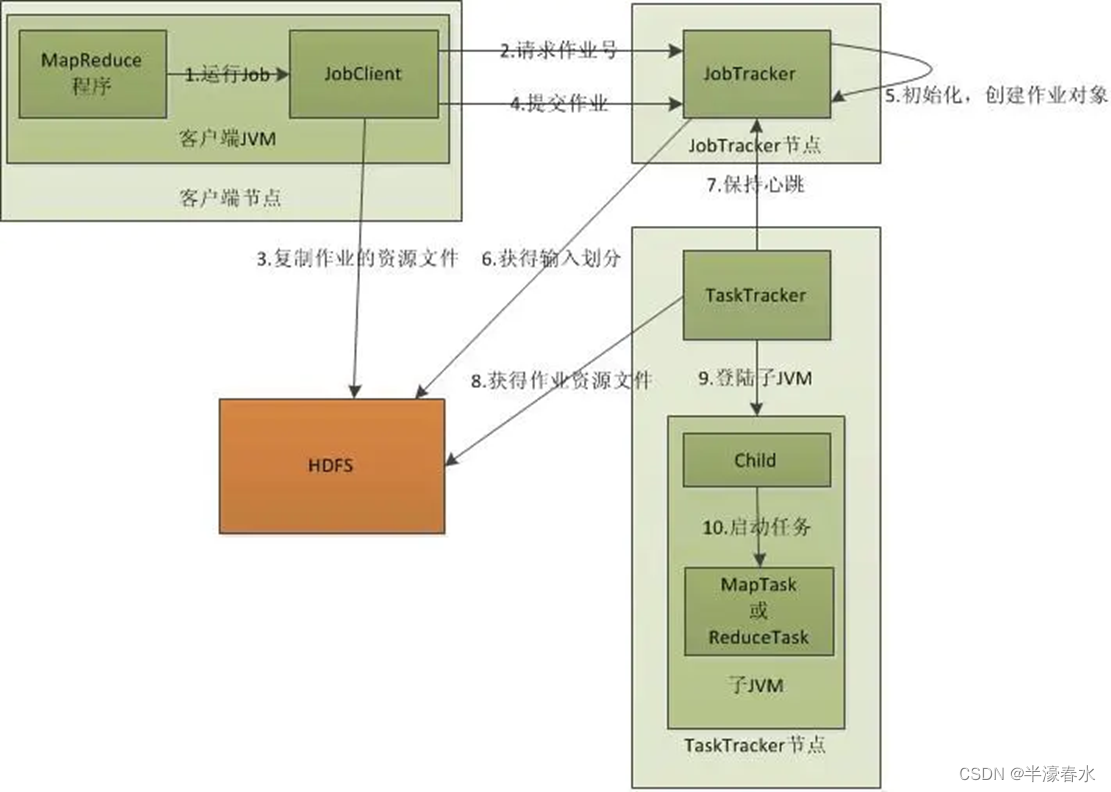
MapReduce 采用了「分而治之」的思想。在分布式计算中,MapReduce 框架负责处理并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map,把一个任务分解成多个任务;reduce,将任务的处理结果汇总。MapReduce 处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
在 Hadoop 中,每个 MapReduce 任务都被初始化为一个 Job,每个 Job 又可以分为两种阶段:map 阶段和 reduce 阶段,分别用两个函数表示。map 函数接收一个 <key, value> 形式的输入,同样产生一个 <key, value> 形式的输出;Hadoop 函数接收一个如 <key, List> 形式的输入,然后对 list 进行处理,每个 reduce 产生 0 或 1 个输出,reduce 的输出也是 <key, value> 形式的。
数据去重
编写测试文件并上传

cat

put
上传jar包,执行程序
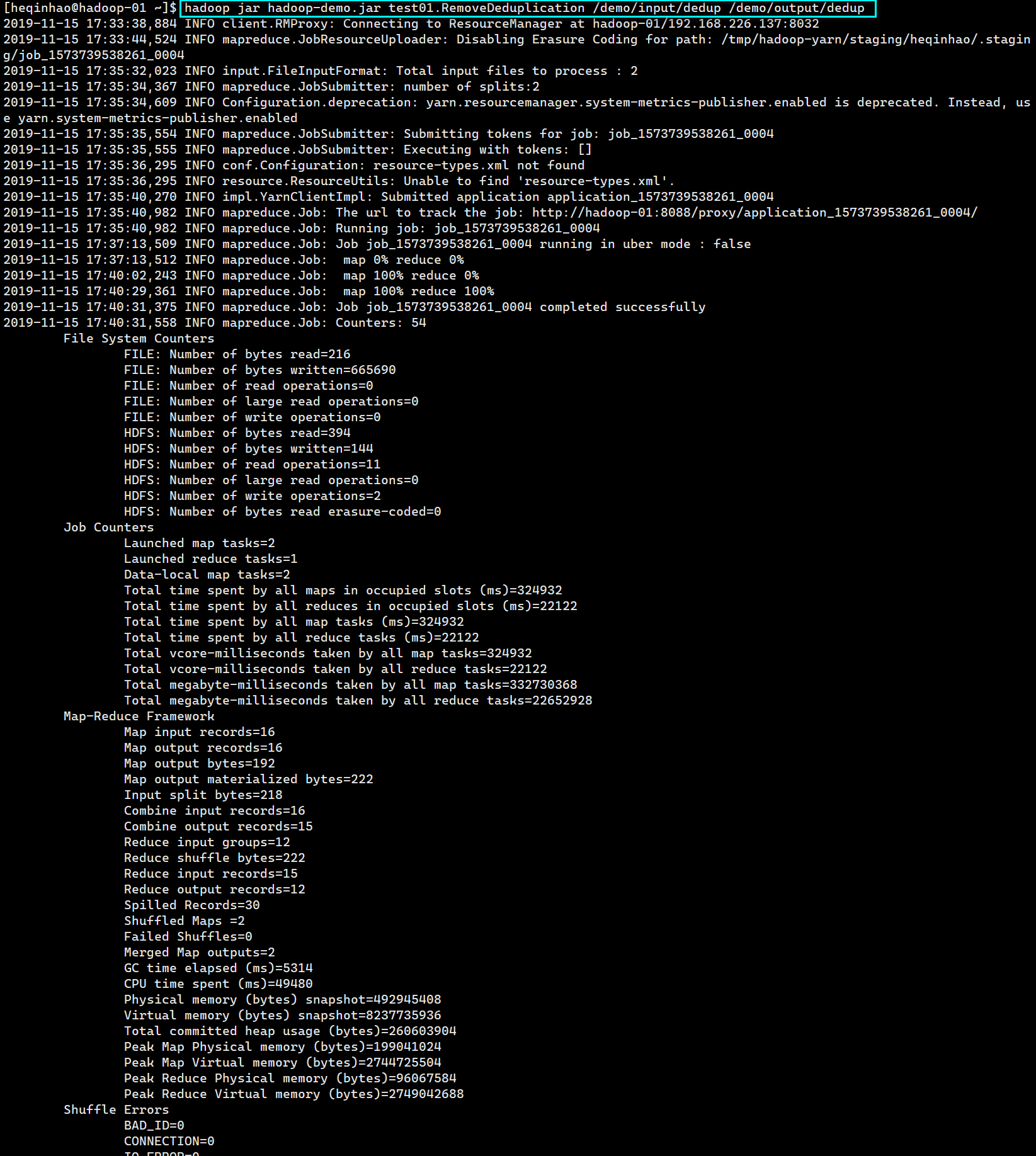
jar
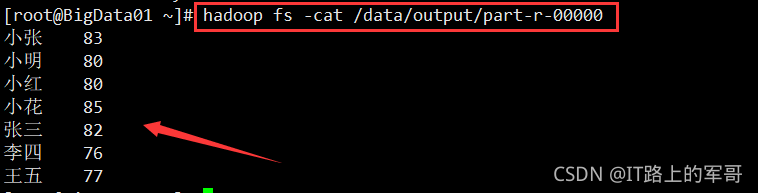
查看输出文件

cat
数据排序
编写测试文件并上传

cat

put
上传jar包,并执行程序
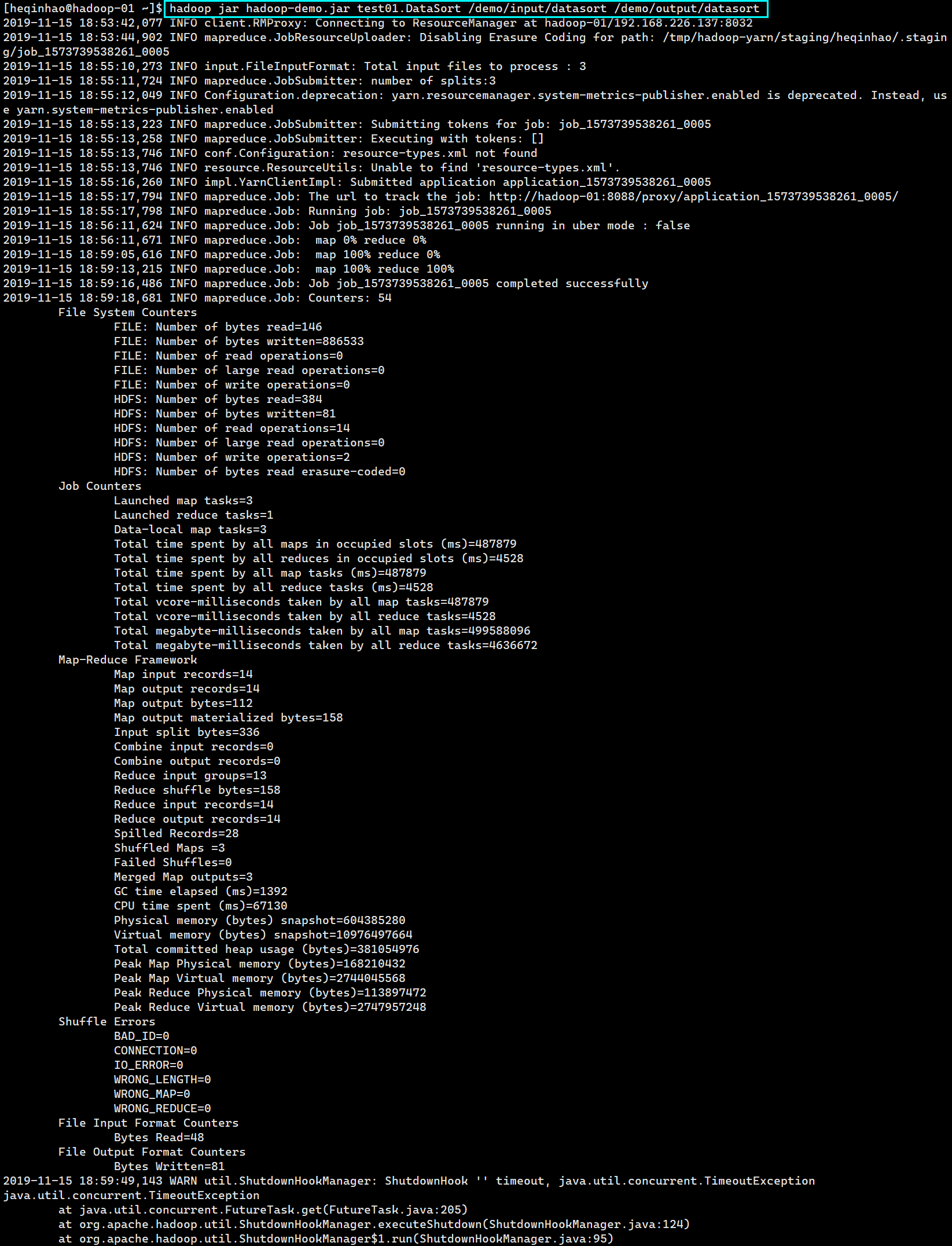
查看输出文件
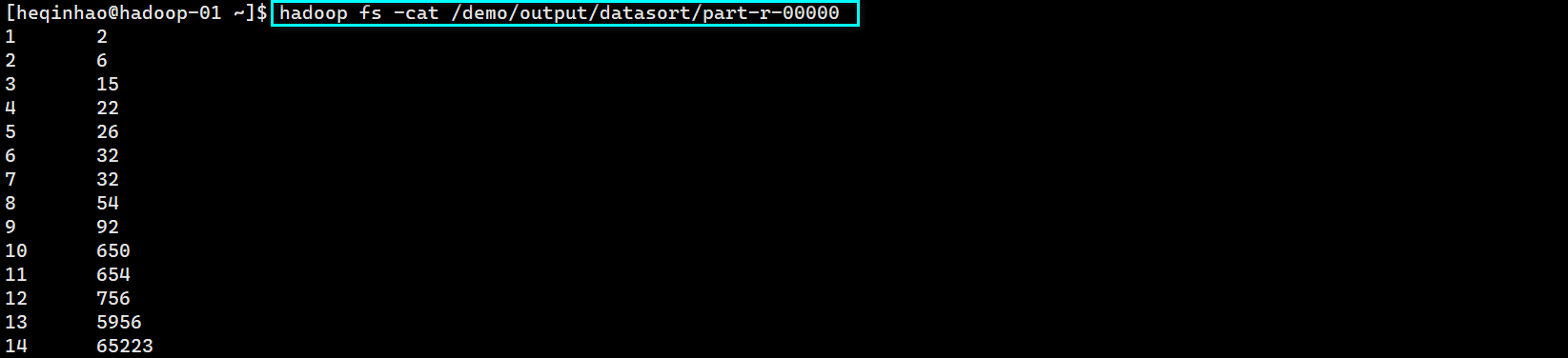
cat
单表关联
编写测试文件并上传

cat
上传jar包,并执行程序
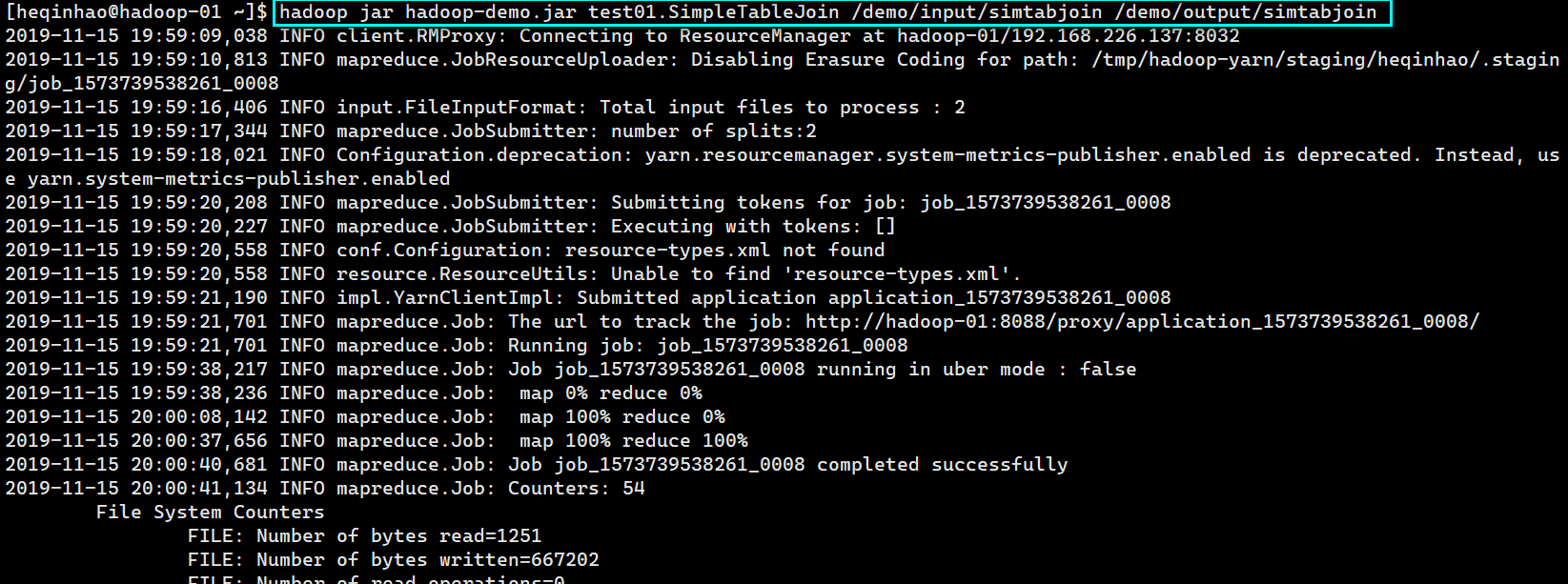
jar
查看输出文件
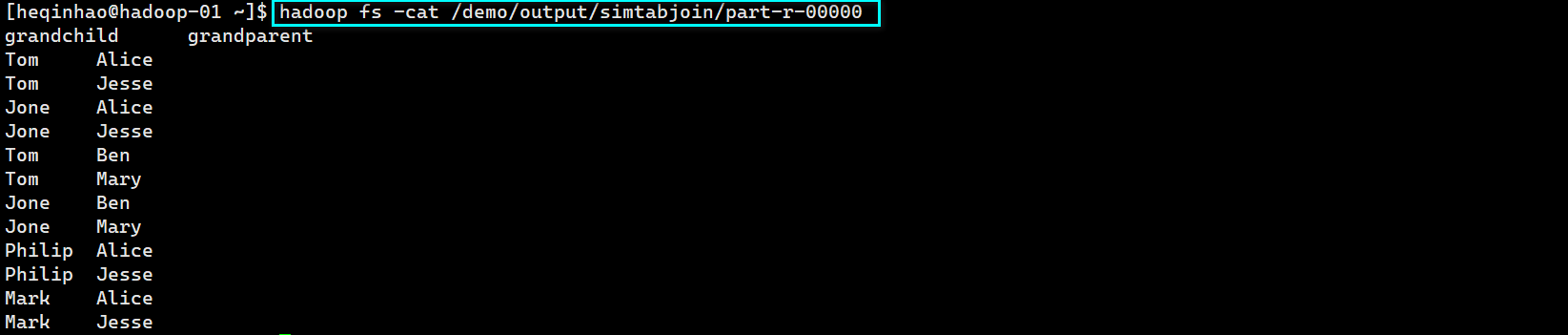
cat
参考代码
数据去重
public class RemoveDeduplication {/*** map 将输入中的 value 复制到输出数据的 key 上,并直接输出*/public static class Map extends Mapper<Object, Text, Text, Text> {// 每行数据private static Text line = new Text();@Overridepublic void map(Object key, Text value, Context context) throws IOException, InterruptedException {line = value;context.write(line, new Text(""));}}/*** reduce 将输入中的 key 复制到输出数据的 key 上,并直接输出*/public static class Reduce extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {context.write(key, new Text(""));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();// 这句话很关键// conf.set("mapred.job.tracker", "192.168.1.2:9001");String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: Data Deduplication <in> <out>");System.exit(2);}Job job = Job.getInstance(conf, "Data Deduplication");job.setJarByClass(RemoveDeduplication.class);// 设置 Map、Combine 和 Reduce 处理类job.setMapperClass(Map.class);job.setCombinerClass(Reduce.class);job.setReducerClass(Reduce.class);// 设置输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 设置输入和输出目录FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
数据排序
public class DataSort {/*** map 将输入中的 value 化成 IntWritable 类型,作为输出的 key*/public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> {private static IntWritable data = new IntWritable();@Overridepublic void map(Object key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();data.set(Integer.parseInt(line));context.write(data, new IntWritable(1));}}/*** reduce 将输入中的 key 复制到输出数据的 key 上,然后根据输入的 value-list 中元素的个数决定 key 的输出次数。* 用全局 lineNum 来代表 key 的位次*/public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {private static IntWritable lineNum = new IntWritable(1);@Overridepublic void reduce(IntWritable key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable val : values) {context.write(lineNum, key);lineNum = new IntWritable(lineNum.get() + 1);}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();// 这句话很关键// conf.set("mapred.job.tracker", "192.168.1.2:9001");String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: Data Sort <in> <out>");System.exit(2);}Job job = Job.getInstance(conf, "Data Sort");job.setJarByClass(DataSort.class);// 设置 Map 和 Reduce 处理类job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);// 设置输出类型job.setOutputKeyClass(IntWritable.class);job.setOutputValueClass(IntWritable.class);// 设置输入和输出目录FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
单表关联
public class SimpleTableJoin {public static int time = 0;/*** map 将输出分割 child 和 parent,然后正序输出一次作为右表,* 反序输出一次作为左表,需要注意的是在输出的 value 中必须加上左右表的区别标识。*/public static class Map extends Mapper<Object, Text, Text, Text> {@Overridepublic void map(Object key, Text value, Context context) throws IOException, InterruptedException {String childName;String parentName;// 左右表标识String relationType;// 输入的一行预处理文本StringTokenizer itr = new StringTokenizer(value.toString());String[] values = new String[2];if (itr.hasMoreTokens()) {values[0] = itr.nextToken();}if (itr.hasMoreTokens()) {values[1] = itr.nextToken();}if (values[0].compareTo("child") != 0) {childName = values[0];parentName = values[1];// 输出左表relationType = "1";context.write(new Text(values[1]), new Text(relationType + "+" + childName + "+" + parentName));// 输出右表relationType = "2";context.write(new Text(values[0]), new Text(relationType + "+" + childName + "+" + parentName));}}}public static class Reduce extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 输出表头if (0 == time) {context.write(new Text("grandchild"), new Text("grandparent"));time++;}int grandchildnum = 0;String[] grandchild = new String[10];int grandparentnum = 0;String[] grandparent = new String[10];for (Text value : values) {String record = value.toString();int len = record.length();int i = 2;if (0 == len) {continue;}// 取得左右表标识char relationType = record.charAt(0);// 定义孩子和父母变量StringBuilder childName = new StringBuilder();StringBuilder parentName = new StringBuilder();// 获取 value-list 中 value 的 childwhile (record.charAt(i) != '+') {childName.append(record.charAt(i));i++;}i = i + 1;// 获取 value-list 中 value 的 parentwhile (i < len) {parentName.append(record.charAt(i));i++;}// 左表,取出 child 放入 grandchildrenif ('1' == relationType) {grandchild[grandchildnum] = childName.toString();grandchildnum++;}// 右表,取出 parent 放入 grandparentif ('2' == relationType) {grandparent[grandparentnum] = parentName.toString();grandparentnum++;}}// grandchild 和 grandparent 数组求笛卡尔儿积if (0 != grandchildnum && 0 != grandparentnum) {for (int m = 0; m < grandchildnum; m++) {for (int n = 0; n < grandparentnum; n++) {// 输出结果context.write(new Text(grandchild[m]), new Text(grandparent[n]));}}}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();// 这句话很关键// conf.set("mapred.job.tracker", "192.168.1.2:9001");String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: Single Table Join <in> <out>");System.exit(2);}Job job = Job.getInstance(conf, "Single Table Join");job.setJarByClass(SimpleTableJoin.class);// 设置 Map 和 Reduce 处理类job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);// 设置输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 设置输入和输出目录FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}