先介绍一下常用的数据序列化类型

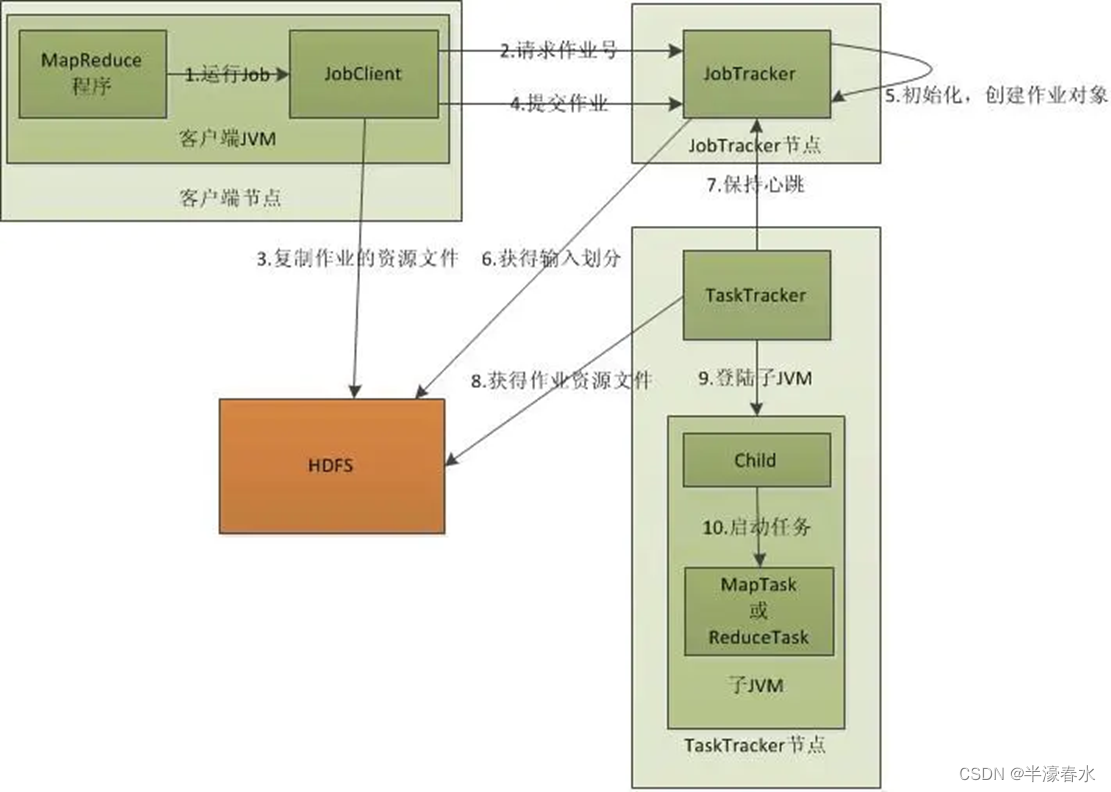
在MapReduce编程中,需要进行数据传输,比如将Mapper的结果传入Reducer中进行汇总,媒介就是context,所以需要可以序列化的数据类型。
MapReduce编程规范
Mapper阶段、Reducer阶段,Driver阶段
Mapper阶段
(1) 用户自定义定义的Mapper要继承自己的父类
(2)Mapper输入的数据是KV对的形式
(3) Mapper 的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV的形式
(5) map() 方法(MapTask) 对每个<K,V> 调用一次
Reducer 阶段
1 用户自定义的Reducer要继承自己的父类
2 Reducer的输入数据类型对应Mapper的输出数据类型 KV
3 Reducer 的业务逻辑写在reduce 中
4 ReduceTask进程每一组相同的K,V调用一次reduce方法
Driver阶段
相当于YARN集群的客户端,用于提交整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象,属于驱动类
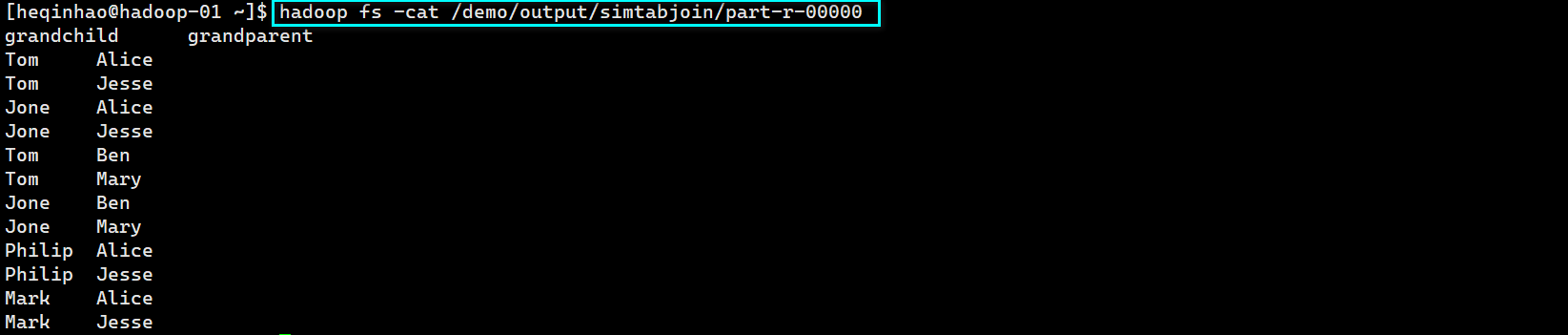
WordCount 实例

2 需求分析
按照MapReduce编程规范,分别编写Mapper.Reducer,Driver类

3 环境准备
(1) 创建建maven工程,MapReduceDemo
(2) 在pom.xml文件中添加依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入,这个文件主要是为打印日志。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(3)创建包名 :com.chenxiang.mapreduce.word.count
4 编写程序
(1) 编写Mapper类
package com.chenxiang.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/** KeyIn LongWritable 偏移量* ValueIn text 1行字符** KeyOut text 单词 * ValueOut intWritable 数量** */
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outK = new Text();private IntWritable outV = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1 获取一行,转换成String,是因为它的API更多,方便操作String line = value.toString();//2切割String[] words = line.split(" ");//3 循环写出for (String word : words) {//封装outKoutK.set(word);//写出context.write(outK, outV);}}
}
(2)编写 Reducer类
package com.chenxiang.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private IntWritable outV=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum=0;//累加for(IntWritable value:values){sum+=value.get();}//写出outV.set(sum);context.write(key,outV);}
}
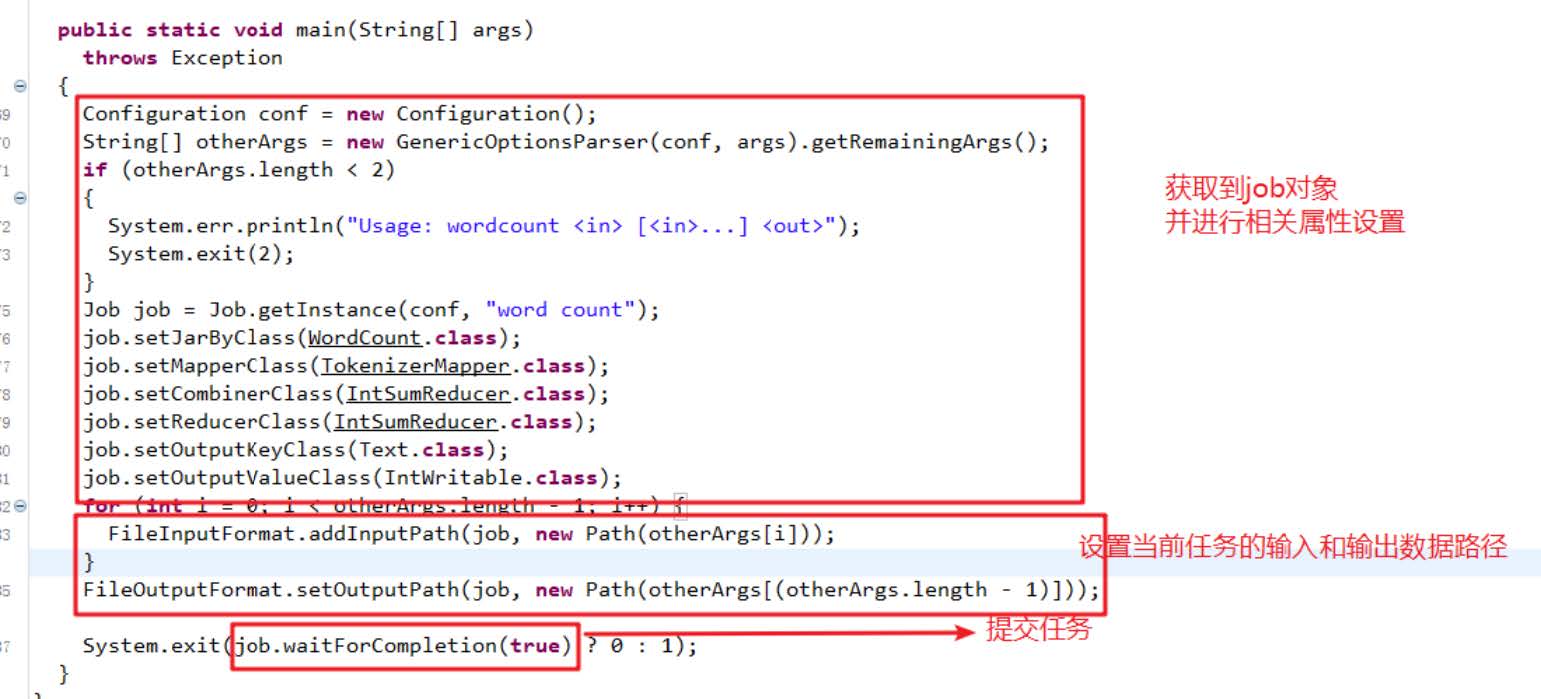
(3)编写驱动类Driver
package com.chenxiang.mapreduce.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1 获取JobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);// 2设置jar包路径job.setJarByClass(WordCountDriver.class);//3 关联mapper和reducejob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);//4 设置map输出的k,v类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//5 设置最终输出的k,v类型job.setMapOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//6 设置输出路径和输出路径FileInputFormat.setInputPaths(job,new Path("D:\\input\\inputword"));//默认按行读取FileOutputFormat.setOutputPath(job,new Path("D:\\output\\output5"));//7 提交jobboolean result = job.waitForCompletion(true);System.out.println(result?0:1);}}
这个Driver分为7步,算是一个固定的规范
这里程序是在本地运行的,因为我们导入了依赖,有相应的运行环境
提交集群测试
(1)用maven打jar包,需要添加的打包插件依赖
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
(2) 将程序打成jar包
(3)修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的/opt/module/hadoop- 3.1.3路径
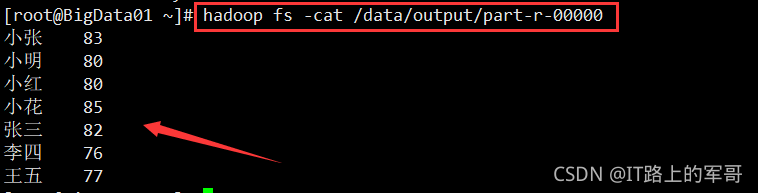
(4) 启动集群
(5)执行WordCount 程序

注意在Driver类中输入输出路径需要修改一下