前提:安装好Hadoop
参考文章:
MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客
实验要求
基于MapReduce执行“词频统计”任务。 将提供的A,B,C文件上传到HDFS上,之后编写MapReduce代码并将其部署到hadoop,实现文件A,B,C中的词频统计。对实验过程进行详细阐述。
实验步骤
1. 启动Hadoop
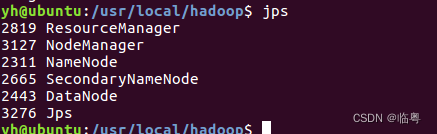
2. 上传本地文件至hdfs中
- 在hdfs中创建存放本地文件的文件夹
$./bin/hdfs dfs -mkdir -p -mkdir /user/hadoop/input$./bin/hdfs dfs -mkdir -p -mkdir /user/hadoop/input- 将文件上传至hdfs中
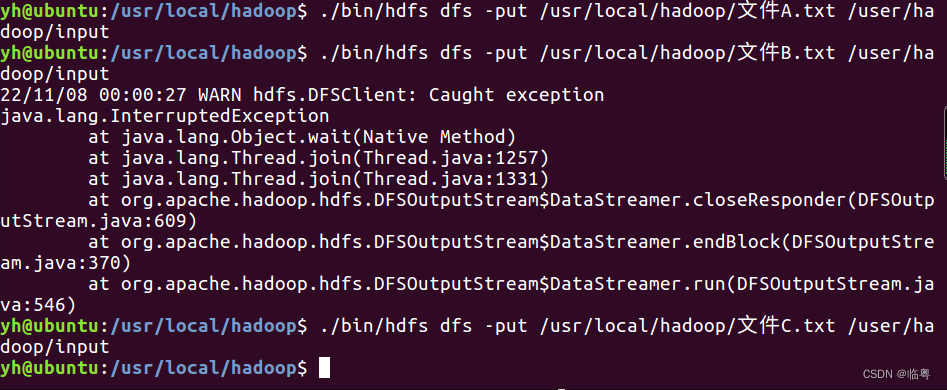
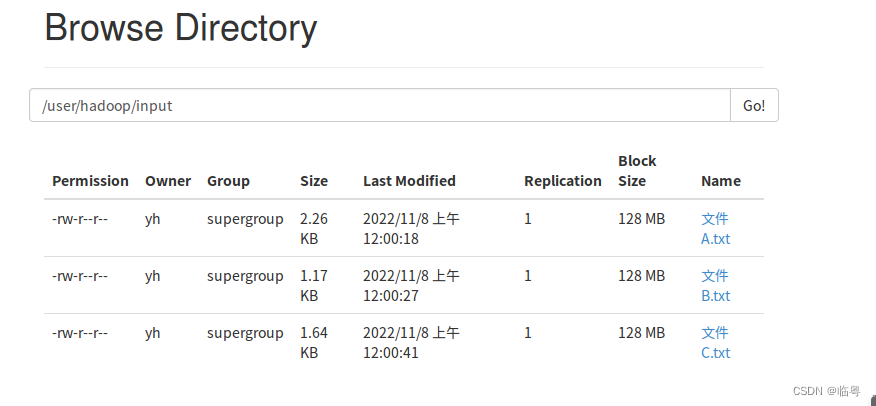
(上传结果)
3. 在eclipse中创建java代码
- 创建java project,并导入Hadoop相关包
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包;(4)“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包。
- 编写MapReduce代码




//java类相关包
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;//这个包是专门管理配置文件的,包含了hadoop中所有关于文件管理的类,所有的都是继承它
import org.apache.hadoop.fs.Path;//可以读取url路径
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;//调用MapReduce的job
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
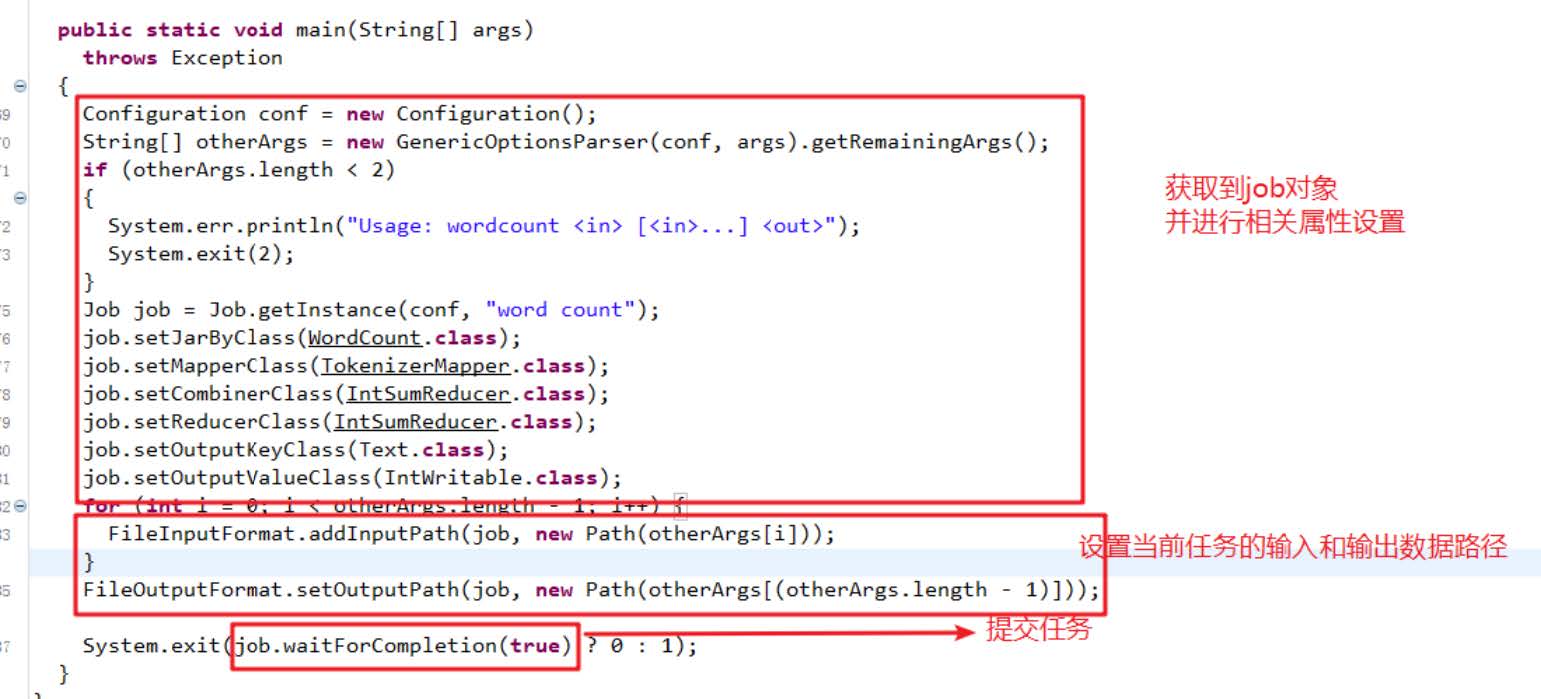
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {//map 处理逻辑public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private static final IntWritable one = new IntWritable(1);//声明输出类型变量private Text word = new Text();//声明输出类型变量//重写Mapper框架逻辑,加入本身项目的处理逻辑//定义输出的文本类型,输出格式,上下文环境变量public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString()); //定义分词器,切分文本,默认划分while(itr.hasMoreTokens()) {this.word.set(itr.nextToken());//从分词器中取出context.write(this.word, one);//输出格式为:<word,one>}}}//reduce 处理逻辑//输入形式 <key,value-list>public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();//声明输出类型变量//重写Mapper框架逻辑,加入本身项目的处理逻辑public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;//sum统计单个单词的词频结果IntWritable val;for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {//遍历循环val = (IntWritable)i$.next();}this.result.set(sum);//将得到的词频数量写入result中context.write(key, this.result);//输出格式为:<key,result>}}//编写主函数public static void main(String[] args) throws Exception {Configuration conf = new Configuration();//初始化配置String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");//设置环境参数job.setJarByClass(WordCount.class);//设置整个程序的类名job.setMapperClass(WordCount.TokenizerMapper.class);//添加MyMapper类job.setCombinerClass(WordCount.IntSumReducer.class);job.setReducerClass(WordCount.IntSumReducer.class);//添加IntSumReducer类job.setOutputKeyClass(Text.class);//设置输出类型job.setOutputValueClass(IntWritable.class); //设置输出类型//将文件夹中所有文件作为输入文件for(int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//设置输出文件FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true)?0:1);//完成词频统计任务}}
4. java代码打包成jar包并部署到Hadoop上

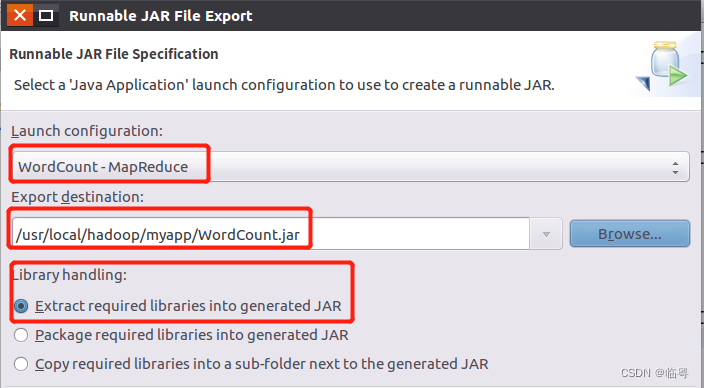
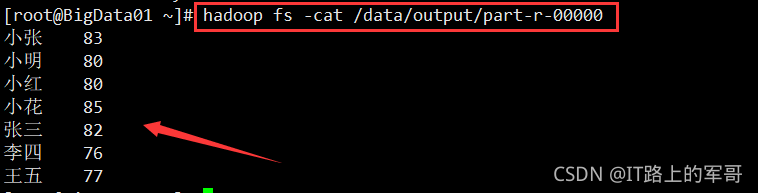
5. 对文件实现词频统计
在终端运行java 代码实现词频统计



小贴士
在终端运行java 代码实现词频统计时一定要确保输出的路径也就是output,不存在,要不然会报错的。
实验中遇到的问题及解决方法
The class file Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT> contains a signature'(Lorg/apache/hadoop/mapreduce/Mapper<TKEYIN;TVALUEIN;TKEYOUT;TVALUEOUT;>.Context;)V' ill-formed at position 74

解决方法:因为在创建java project时没有选择当前的Linux系统中已经安装好的JDK而出现的问题

修改前

修改后
实验参考厦门大学老师的hdfs编程教程
如果有什么错漏的地方,请各位大佬指教[抱拳]