-
目录
编程实现按日期统计访问次数
2.编程实现按访问次数排序
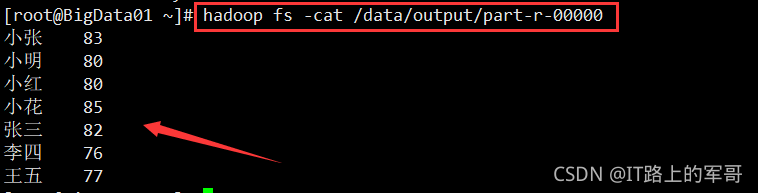
获取成绩表最高分
编译jar'包方法
-
编程实现按日期统计访问次数
(1) 定义输入/输出格式
社交网站用户的访问日期在格式上属于文本格式,访问次数为整型数值格式。其组成的键值对为<访问日期,访问次数>,因此Mapper的输出与Reducer的输出都选用Text类与IntWritable类。
(2)Mapper 类的逻辑实现
Mapper类中最主要的部分就是map函数。map函数的主要任务就是读取用户访问文件中的数据,输出所有访问日期与初始次数的键值对。因此访问日期是数据文件的第二列,所有先定义一个数组,再提取第二个元素,与初始次数1一起构成要输出的键值对,即<访问日期,1>。
(3)Reducer的逻辑实现
Reducer类中最主要的部分就是reduce函数。reduce的主要任务就是读取Mapper输出的键值对<访问日期,1>。这一部分与官网给出的WordCount中的Reducer完全相同
-
完整代码
将文件编译生成jar包上传到集群(生成jar包方法在后面)import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MyKubi {public static class MyMapperextends Mapper<Object,Text,Text,IntWritable>{private final static IntWritable one = new IntWritable(1);public void map(Object key, Text value, Context context)throws IOException, InterruptedException{String line = value.toString();String array[] = line.split(",");String keyOutput = array[1];context.write(new Text(keyOutput),one);}}public static class MyReducerextends Reducer<Text,IntWritable,Text,IntWritable>{private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values ){sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception{Configuration conf = new Configuration();Job job=Job.getInstance(conf, "Daily Access Count");job.setJarByClass(MyKubi.class);job.setMapperClass(MyMapper.class);job.setReducerClass(MyReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i< args.length - 1; ++i){FileInputFormat.addInputPath(job, new Path(args[i]));}FileOutputFormat.setOutputPath(job,new Path(args[args.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1); } }
- 将数据文件上传的虚拟机在上传到hdfs
- 在jar包的目录下执行 命令 hadoop jar (jar包名) /(数据文件目录) /(输出结果目录)、
-
2.编程实现按访问次数排序
- MapReduce只会对键值进行排序,所以我们在Mapper模块中对于输入的键值对,把Key与Value位置互换,在Mapper输出后,键值对经过shuffle的处理,已经变成了按照访问次数排序的数据顺序啦,输出格式为<访问次数,日期>。Reducer的处理和Mapper恰好相反,将键和值的位置互换,输出格式变为<日期,访问次数>。
- 完整代码
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class AccessTimesSort {// Mapper模块public static class MyMapperextends Mapper<Object, Text, IntWritable,Text>{public void map(Object key, Text value, Context context) //map函数的编写要根据读取的文件内容和业务逻辑来写throws IOException, InterruptedException {String line = value.toString();String array[] = line.split("\t");//指定,为分隔符,组成数组int keyOutput = Integer.parseInt(array[1]);//提取数组中的访问次数作为KeyString valueOutput = array[0]; //将日期作为valuecontext.write(new IntWritable(keyOutput), new Text(valueOutput));}}// Reducer模块public static class MyReducerextends Reducer<IntWritable,Text,Text,IntWritable> {//注意与上面输出对应public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {for (Text val : values) {context.write(val, key); //进行键值位置互换}}}//Driver模块,主要是配置参数public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "AccessTimesSort");job.setJarByClass(AccessTimesSort.class);job.setMapperClass(MyMapper.class);job.setReducerClass(MyReducer.class);job.setMapOutputKeyClass(IntWritable.class);job.setMapOutputValueClass(Text.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < args.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(args[i]));}FileOutputFormat.setOutputPath(job,new Path(args[args.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);} }执行方法如上
-
获取成绩表最高分
- 在 Mapper 类中,map 函数读取成绩表 A 中的数据,直接将读取的数据以空格分隔,组成键值对<科目,成绩>,即设置输出键值对类型为<Text,IntWritable>。
在 Reduce 中,由于 map 函数输出键值对类型是<Text,IntWritable>,所以 Reducer 接收的键值对是<Text,Iterable<IntWritable>>。针对相同的键(即科目),遍历比较它的值(即成绩),找出最高值(即最高成绩),最后输出键值对<科目,最高成绩>。 - 完整代码
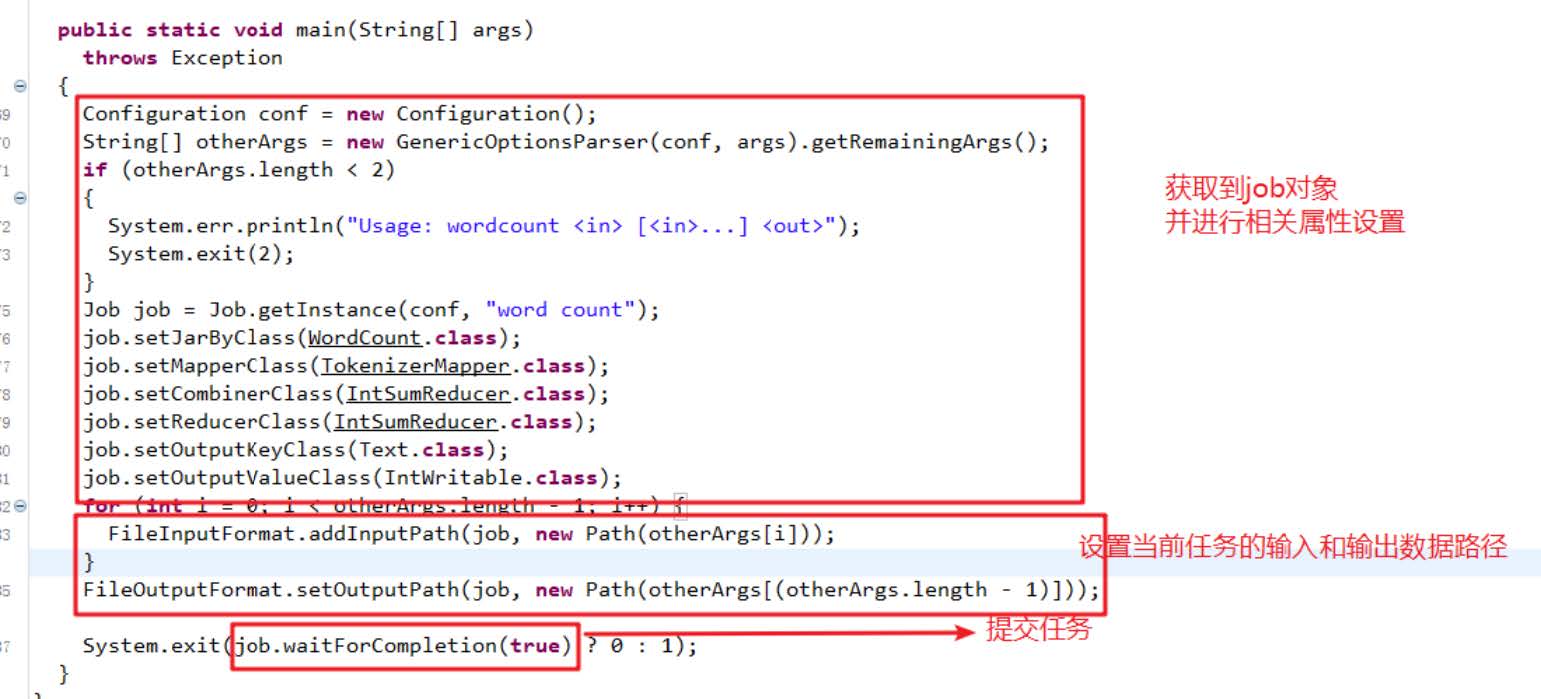
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FindMax {public static class FindMaxMapper extends Mapper<LongWritable, Text,Text,IntWritable>{Text course = new Text();IntWritable score = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String [] values = value.toString().trim().split(" ");course.set(values[0]);score.set(Integer.parseInt(values[1]));context.write(course,score);}}public static class FindMaxReducer extends Reducer<Text,IntWritable,Text,IntWritable>{@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int maxScore = -1;Text course = new Text();for(IntWritable score:values){if (score.get()>maxScore){maxScore = score.get();course = key;}}context.write(course,new IntWritable(maxScore));}}public static void main(String [] args) throws Exception{ // if (args.length != 2){ // System.out.println("FindMax <input> <output>"); // System.exit(-1); // }Configuration conf = new Configuration();Job job = Job.getInstance(conf,"findmax");job.setJarByClass(FindMax.class);job.setMapperClass(FindMaxMapper.class);job.setReducerClass(FindMaxReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.setNumReduceTasks(1);FileInputFormat.addInputPath(job,new Path(args[0]));FileSystem.get(conf).delete(new Path(args[1]),true);FileOutputFormat.setOutputPath(job,new Path(args[1]));System.out.println(job.waitForCompletion(true) ? 0 : 1);} }编译jar'包方法
- 右键点击要编译的文件选择Export

- Java——JARfile

- 选择classpath project——next

点击两次next,选择存放路径,选择文件

********在执行命令是不要忘记将数据文件上传到hdfs************