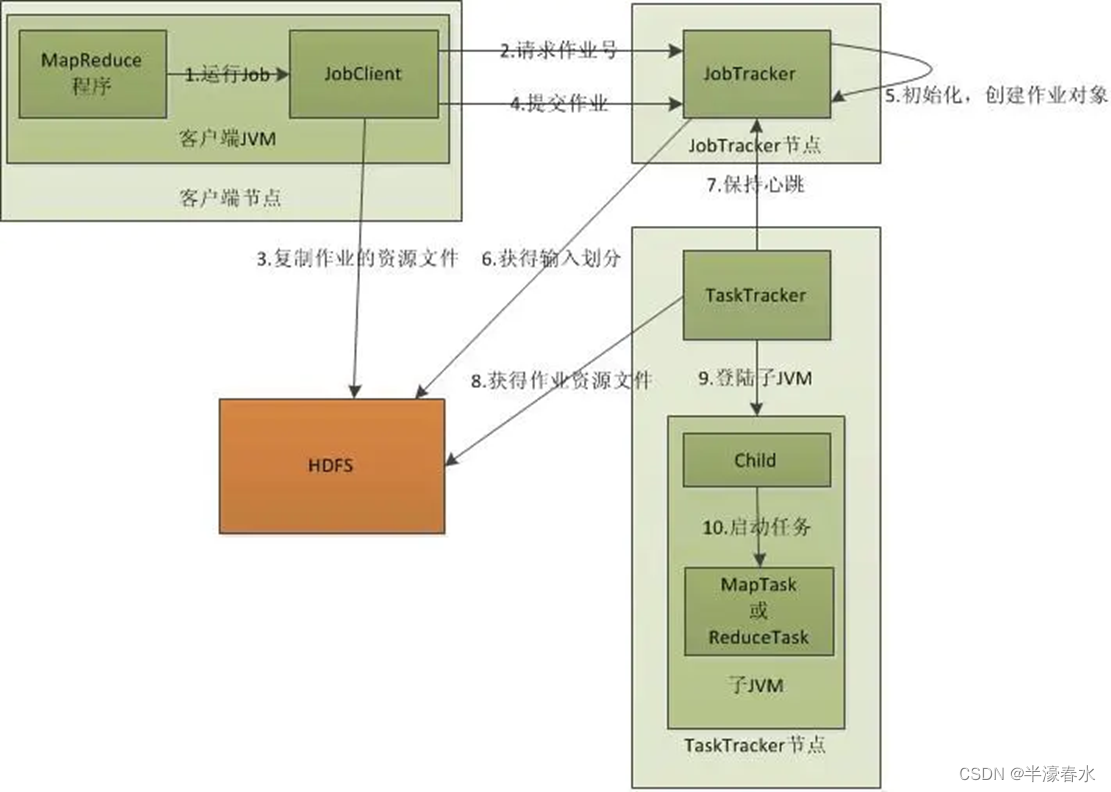
一、实验目的
- 通过实验掌握基本的MapReduce编程方法;
- 掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
二、 实验平台
操作系统:ubuntu18
Hadoop版本:3.2.2
HBase版本:2.2.2
JDK版本:1.8
Java IDE:eclipse
三、实验内容和要求
- 编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
实验过程:
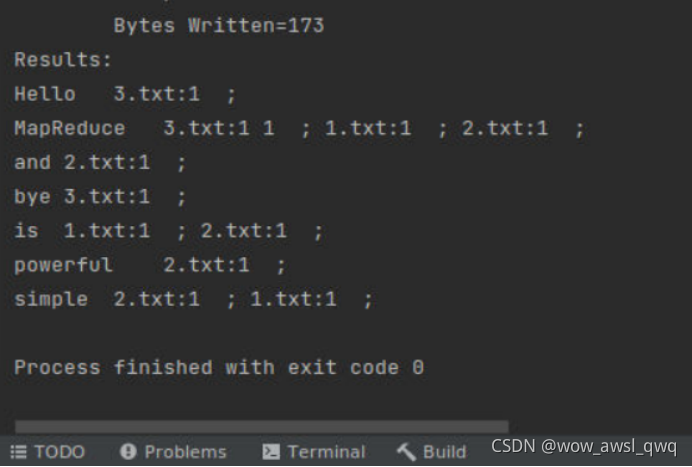
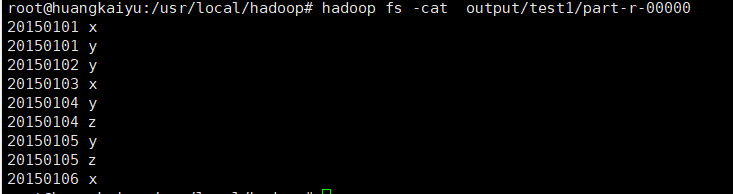
分别创建a和b文本文件传入到hdfs的input/test1目录中(文件夹也需自己创建),然后用下面代码运行jar包并且查看结果,题目2,3同理
hadoop jar ./javaapp/Mapruduce1.jar #运行jar包
hadoop fs -cat output/test1/part-r-00000 #查看结果
实验截图
实验代码
package shiyan4;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
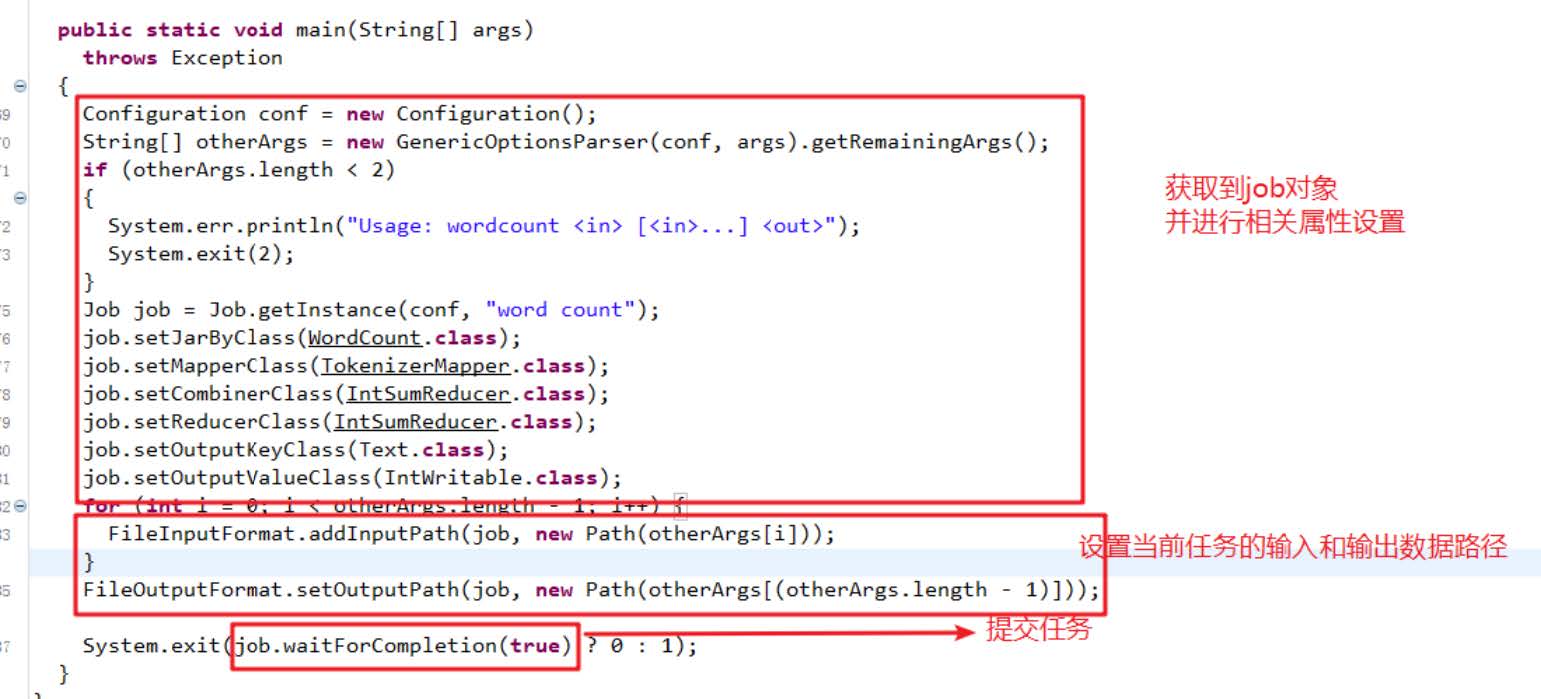
//import org.apache.hadoop.mapred.FileOutputFormat;//import org.apache.hadoop.mapreduce.Mapper.Context;public class Merge {public static class Map extends Mapper<Object,Text,Text,Text>{private static Text text=new Text();public void map(Object key,Text value,Context context) throws IOException, InterruptedException{text=value;context.write(text,new Text(""));}}public static class Reduce extends Reducer<Text,Text,Text,Text>{public void reduce(Text key,Iterable <Text>values,Context context) throws IOException, InterruptedException{context.write(key, new Text(""));}}public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{Configuration conf=new Configuration();conf.set("fs.defaultFS","hdfs://47.113.222.36:9000");String[] otherArgs=new String[]{"input/test1/","output/test1/"};if(otherArgs.length!=2){System.err.println("Usage:Merge and duplicate removal<in><out>");System.exit(2);}Job job=Job.getInstance(conf,"Merge and duplicate removal");job.setJarByClass(Merge.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job,new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));System.exit(job.waitForCompletion(true)?0:1);}
}输入文件A的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件A和B合并得到的输出文件C的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
- 编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
hadoop jar ./javaapp/Mapruduce2.jar #运行jar包
hadoop fs -cat output/test2/part-r-00000 #查看结果
实验截图

package shiyan42;import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class MergeSort {public static class Map extends Mapper<Object,Text,IntWritable,IntWritable>{private static IntWritable data=new IntWritable();public void map(Object key,Text value,Context context) throws IOException, InterruptedException{String line=value.toString();data.set(Integer.parseInt(line));context.write(data, new IntWritable(1));}}public static class Reduce extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{private static IntWritable linenum=new IntWritable(1);public void reduce(IntWritable key,Iterable <IntWritable>values,Context context) throws IOException, InterruptedException{for(IntWritable num:values){context.write(linenum, key);linenum=new IntWritable(linenum.get()+1);}}}/*** @param args* @throws IOException * @throws InterruptedException * @throws ClassNotFoundException */public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{Configuration conf=new Configuration();conf.set("fs.defaultFS","hdfs://47.113.222.36:9000");String[] str=new String[]{"input/test2/","output/test2/"};String[] otherArgs=new GenericOptionsParser(conf,str).getRemainingArgs();if(otherArgs.length!=2){System.err.println("Usage:mergesort<in><out>");System.exit(2);}Job job=Job.getInstance(conf,"mergesort");job.setJarByClass(MergeSort.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(IntWritable.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job,new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));System.exit(job.waitForCompletion(true)?0:1);}}输入文件1的样例如下:
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
- 对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
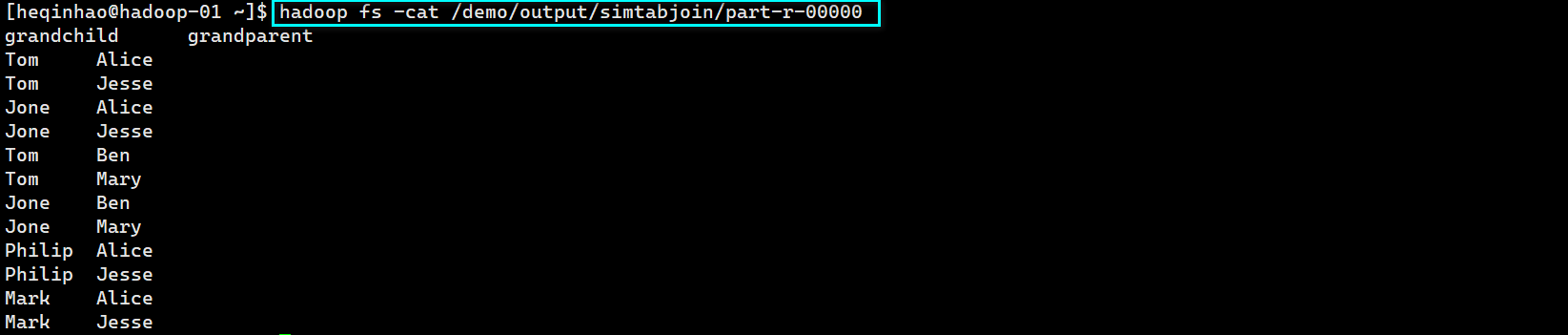
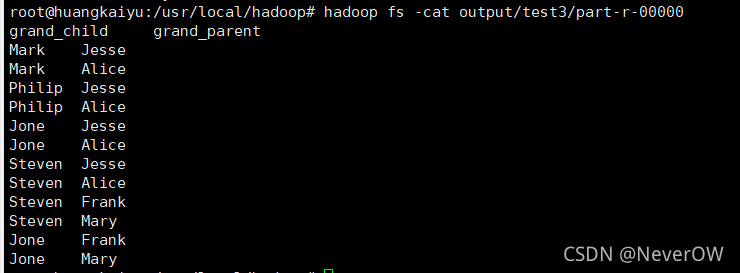
hadoop jar ./javaapp/Mapruduce3.jar #运行jar包
hadoop fs -cat output/test3/part-r-00000 #查看结果
实验截图
package shiyan43;import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class STjoin {public static int time = 0;public static class Map extends Mapper<Object, Text, Text, Text> {public void map(Object key, Text value, Context context)throws IOException, InterruptedException {String child_name = new String();String parent_name = new String();String relation_type = new String();String line = value.toString();int i = 0;while (line.charAt(i) != ' ') {i++;}String[] values = { line.substring(0, i), line.substring(i + 1) };if (values[0].compareTo("child") != 0) {child_name = values[0];parent_name = values[1];relation_type = "1";context.write(new Text(values[1]), new Text(relation_type + "+" + child_name + "+" + parent_name));relation_type = "2";context.write(new Text(values[0]), new Text(relation_type + "+"+ child_name + "+" + parent_name));}}}public static class Reduce extends Reducer<Text, Text, Text,Text> {public void reduce(Text key, Iterable values, Context context)throws IOException, InterruptedException {if (time == 0) {context.write(new Text("grand_child"), new Text("grand_parent"));time++;}int grand_child_num = 0;String grand_child[] = new String[10];int grand_parent_num = 0;String grand_parent[] = new String[10];Iterator ite = values.iterator();while (ite.hasNext()) {String record = ite.next().toString();int len = record.length();int i = 2;if (len == 0)continue;char relation_type = record.charAt(0);String child_name = new String();String parent_name = new String();while (record.charAt(i) != '+') {child_name = child_name + record.charAt(i);i++;}i = i + 1;while (i < len) {parent_name = parent_name + record.charAt(i);i++;}if (relation_type == '1') {grand_child[grand_child_num] = child_name;grand_child_num++;} else {grand_parent[grand_parent_num] = parent_name;grand_parent_num++;}}if (grand_parent_num != 0 && grand_child_num != 0) {for (int m = 0; m < grand_child_num; m++) {for (int n = 0; n < grand_parent_num; n++) {context.write(new Text(grand_child[m]), new Text(grand_parent[n]));}}}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://47.113.222.36:9000");String[] otherArgs = new String[] {"input/test3/","output/test3/"};if (otherArgs.length != 2) {System.err.println("Usage: Single Table Join ");System.exit(2);}Job job = Job.getInstance(conf, "Single table join ");job.setJarByClass(STjoin.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse