引用了博客:https://blog.csdn.net/fanwenbo/article/details/54848429
这里是我自己做的实验,如下:
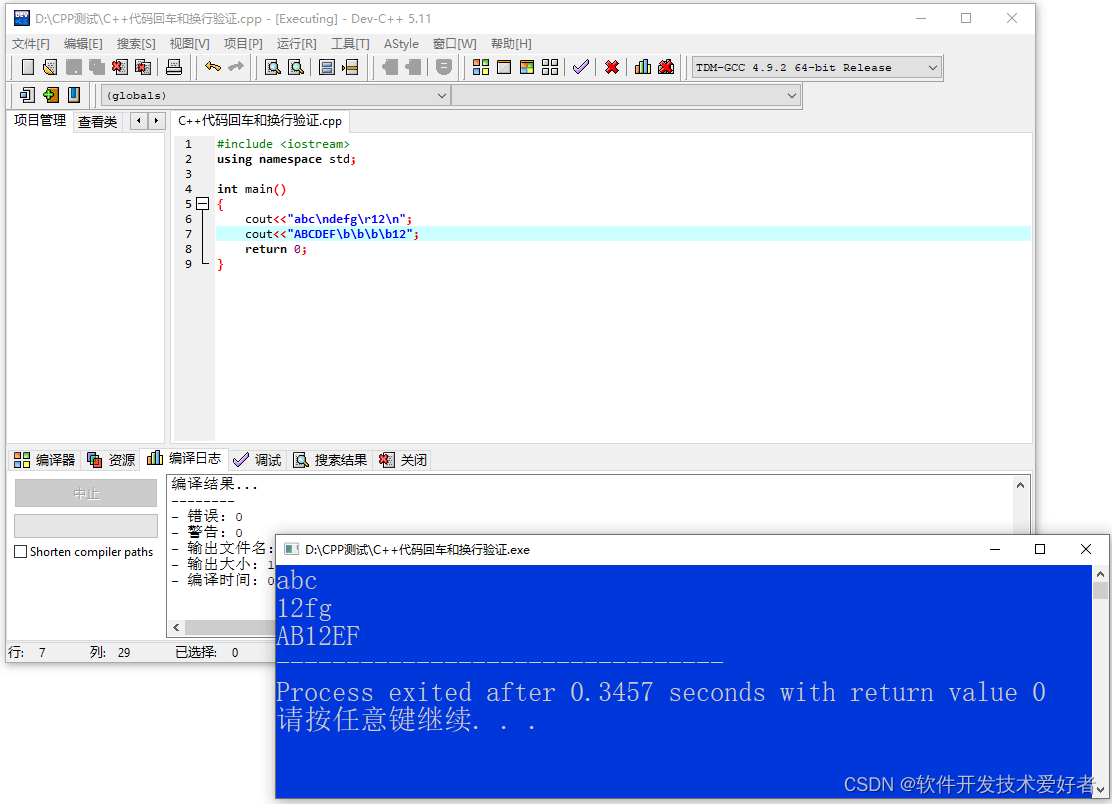
printf("A is here!");printf("I am here!");putchar('\r');printf("First input!");putchar('\n');printf("Second input!\b");printf("I am here!"); 运行结果:

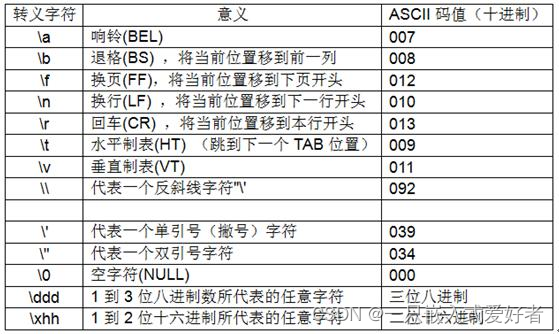
结论是‘\r’是将光标从新移动到每行的开头,这与老式的打印机一样;二是‘\n’是换行,并且光标移动到每行的开头,这与不同于老式打字机,打字机换行时告诉打字机把滚筒卷一格,不改变水平位置。退格这个与老式打字机一样。
这里我们可以在讨论一下在文件中换行到底是什么样子的。
首先我们新建一个文本文档,默认是ANSI编码的,也就是一个中文字符2字节,一个英文字符1字节,随便输入一些内容。注意第二行我没有输入回车键。

可以看到按下一一次回车键增加两个字节,所以我们不难得出:window 系统行末结束符是\r\n。
那在用C语言读取文件时会出现什么样的情况呢?下次再来研究这个问题。


![[PTA]习题8-2 在数组中查找指定元素](https://img-blog.csdnimg.cn/1d555e2dc5c94764aff23658e02e9568.png)
![[PTA]实验8-1-5 在数组中查找指定元素](https://img-blog.csdnimg.cn/62eaa40e868542e19bb5291c784c3392.png)