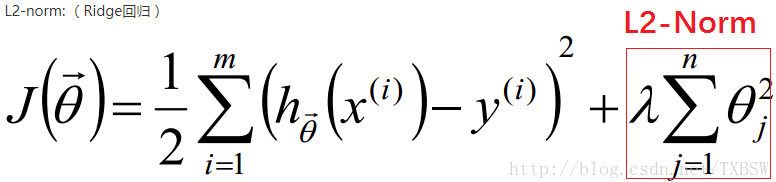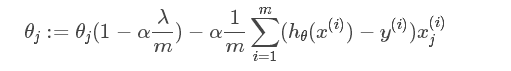正则化的目的?
欠拟合从字面意思来看就是欠缺拟合程度,这一般在复杂度很低的模型中出现。从数学上来看,一元一次函数为一条直线、一元二次函数为一个曲线,以此类推。那么参数越多,其越能拟合更复杂的特征,但是一味的增加模型的复杂度就会造成过拟合现象。一旦过拟合,模型的泛化能力以及鲁棒性将特别差。那么怎么解决过拟合现象呢?
在从数学方面分析来看,为了减小过拟合,要将一部分参数置为0,最直观的方法就是限制参数的个数,因此可以通过正则化来解决,即减小模型参数大小或参数数量,缓解过拟合。
L1和L2正则化
(一)L1正则化
L1正则化,又称Lasso Regression,是指权值向量w中各个元素的绝对值之和,是一种常用的正则化技术,用于控制模型的复杂度、特征选择和降低过拟合的风险。与L2正则化不同,L1正则化通过添加权重向量的L1范数作为正则化项来实现。 比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|。
L1正则化可以让一部分特征的系数缩小到0,所以L1适用于特征之间有关联的情况可以产生稀疏权值矩阵(很多权重为0,则一些特征被过滤掉),即产生一个稀疏模型,可以用于特征选择。因此,L1正则化可以用于优化模型,使得仅有对预测目标有重要影响的特征保留下来,而对次要特征的权重趋近于0,从而降低模型的复杂度并提高泛化能力。L1也可以防止过拟合。
那么L1为什么会产生一个稀疏权值矩阵呢?
L1范数是指权重向量中各个元素的绝对值之和,所以L1是带有绝对值符号的函数,因此是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数后添加L1正则化项时,相当于对损失函数做了一个约束。

或者是:L(w) = Loss(y, y_pred) + λ * |w|
其中,L(w)是加了L1正则化的损失函数,Loss(y, y_pred)是模型的原始损失函数(例如,均方误差或交叉熵),w是模型的权重向量,||w||1是权重向量的L1范数,λ是正则化参数,用于控制正则化的强度。
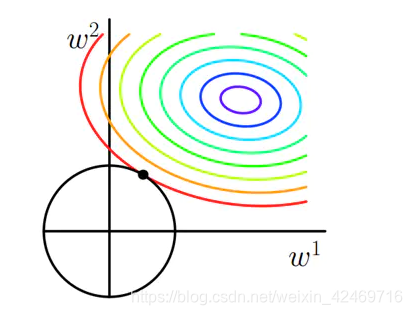
此时我们的任务变成在约束下求出取最小值的解。考虑二维的情况,即只有两个权值和 ,此时对于梯度下降法,求解函数的过程可以画出等值线,同时L1正则化的函数也可以在二维平面上画出来。如下图:

图中蓝色圆圈线是Loss中前半部分待优化项的等高线,就是说在同一条线上其取值相同,且越靠近中心其值越小。
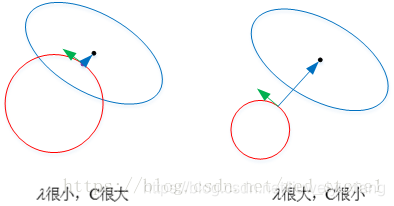
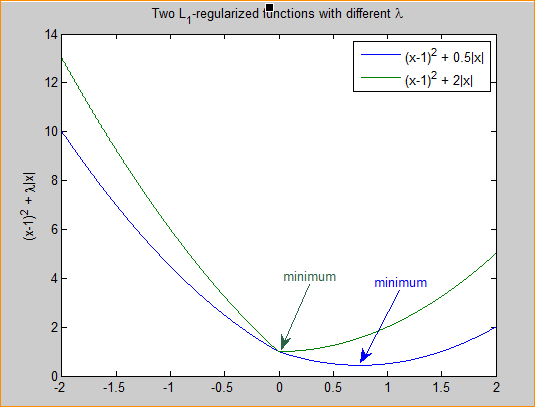
黄色菱形区域是L1正则项限制。带有正则化的loss函数的最优解要在黄色菱形区域和蓝色圆圈线之间折中,也就是说最优解出现在图中优化项等高线与正则化区域相交处。从图中可以看出,当待优化项的等高线逐渐向正则项限制区域扩散时,L1正则化的交点大多在坐标轴上,则很多特征维度上其参数w为0,因此会产生稀疏解;而正则化前面的系数,可以控制图形的大小。越小,约束项的图形越大(上图中的黄色方框);越大,约束项的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值中的可以取到很小的值。
L1正则化的一些关键特点和优点包括:
特征选择:L1正则化有助于选择对预测目标具有重要影响的特征,使得模型更具解释性和可解释性。通过将权重置为0,L1正则化可以自动执行特征选择。
稀疏性:L1正则化倾向于生成稀疏权重向量,即将某些特征的权重归零。这有助于减少特征维度,提高模型的可解释性和计算效率。
鲁棒性:L1正则化对于异常值和噪声具有一定的鲁棒性,可以减少其对模型的影响。
系数简化:L1正则化可以导致模型的系数变得更加简单,易于解释和理解。
需要注意的是,L1正则化与L2正则化在惩罚权重的方式和效果上有所不同。L1正则化倾向于生成稀疏解,而L2正则化则倾向于将权重值平均分散在各个特征上。
(二)、L2正则化
L2正则化是指权值向量中各个元素的平方和然后再求平方根,对参数进行二次约束,参数w变小,但不为零,不会形成稀疏解 。它会使优化求解稳定快速,使权重平滑。所以L2适用于特征之间没有关联的情况。

或者是:L(w) = Loss(y, y_pred) + λ * ||w||^2
其中,L(w)是加了L2正则化的损失函数,Loss(y, y_pred)是模型的原始损失函数(例如,均方误差或交叉熵),w是模型的权重向量,||w||^2是权重向量的L2范数的平方,λ是正则化参数,用于控制正则化的强度。
正则化参数λ越大,正则化项在损失函数中的比重就越大,对权重的惩罚也就越大。这有助于降低模型对训练数据的过拟合程度,并使模型倾向于选择较小的权重值,从而提高模型的泛化能力。
考虑二维的情况,即只有两个权值和 ,此时对于梯度下降法,求解函数的过程可以画出等值线,同时L2正则化的函数也可以在二维平面上画出来。如下图:

图中蓝色一圈一圈的线是Loss中前半部分待优化项的等高线,就是说在同一条线上其取值相同,且越靠近中心其值越小。图中黄色圆形区域是L2正则项限制。带有正则化的loss函数的最优解要在loss函数和正则项之间折中,也就是说最优解出现在图中优化项等高线与正则化区域相交处。从图中可以看出,当待优化项的等高线逐渐向正则项限制区域扩散时L2正则化的交点大多在非坐标轴上,二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此与相交时使得或等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化的优点包括:
可以有效地减少过拟合现象,提高模型的泛化能力。
通过控制权重的大小,可以防止模型过度依赖某些特征。
L2正则化对权重的惩罚是连续可微的,有助于使用梯度下降等优化算法进行模型训练。
需要注意的是,L2正则化只对权重进行惩罚,对于偏置(bias)项通常不应用正则化。另外,正则化参数λ的选择通常需要通过交叉验证等方法进行调优,以获得最佳的模型性能。