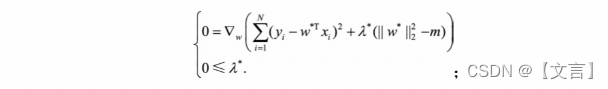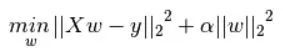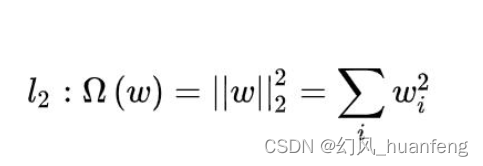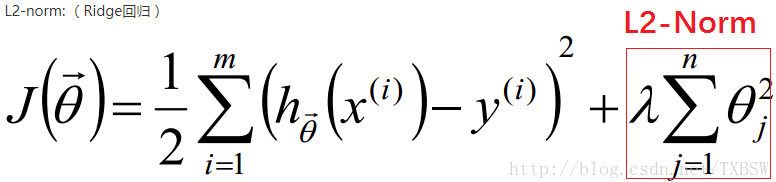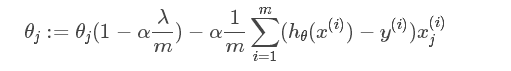L1正则化和L2正则化
- 在机器学习实践过程中,训练模型的时候往往会出现过拟合现象,为了减小或者避免在训练中出现过拟合现象,通常在原始的损失函数之后附加上正则项,通常使用的正则项有两种:L1正则化和L2正则化。
- L1正则化和L2正则化都可以看做是损失函数的惩罚项,所谓惩罚项是指对损失函数中的一些参数进行限制,让参数在某一范围内进行取值。L1正则化的模型叫做LASSO回归,L2正则化的模型叫做岭回归。
LASSO回归公式------L1正则化
min 1 2 m Σ i = 1 m ( f ( x ) − y ( i ) ) 2 + λ ∥ w ∥ 1 \min \frac{1}{2m} \Sigma_{i=1}^{m}\left(f(x)-y^{(i)}\right)^{2}+\lambda\|w\|_{1} min2m1Σi=1m(f(x)−y(i))2+λ∥w∥1
- L1正则化项是指权重向量w中各元素的绝对值之和,表示为 λ ∥ w ∥ 1 \lambda\|w\|_{1} λ∥w∥1
- L1正则化用于进行稀疏化(会令权重向量w中某一些参数等于0)处理,通常用于在多特征中进行特征选择,也可用于避免过拟合.
岭回归公式-------L2正则化
min 1 2 m Σ i = 1 m ( f ( x ) − y ( i ) ) 2 + λ ∥ w ∥ 2 2 \min \frac{1}{2 m} \Sigma_{i=1}^{m}\left(f(x)-y^{(i)}\right)^{2}+\lambda\|w\|_{2}^{2} min2m1Σi=1m(f(x)−y(i))2+λ∥w∥22
L2正则化项是指权重向量w ww中个元素的平方和,表示为 λ ∥ w ∥ 2 2 \lambda\|w\|_{2}^{2} λ∥w∥22
L2正则化用于避免模型发生过拟合现象.
LASSO回归公式理解
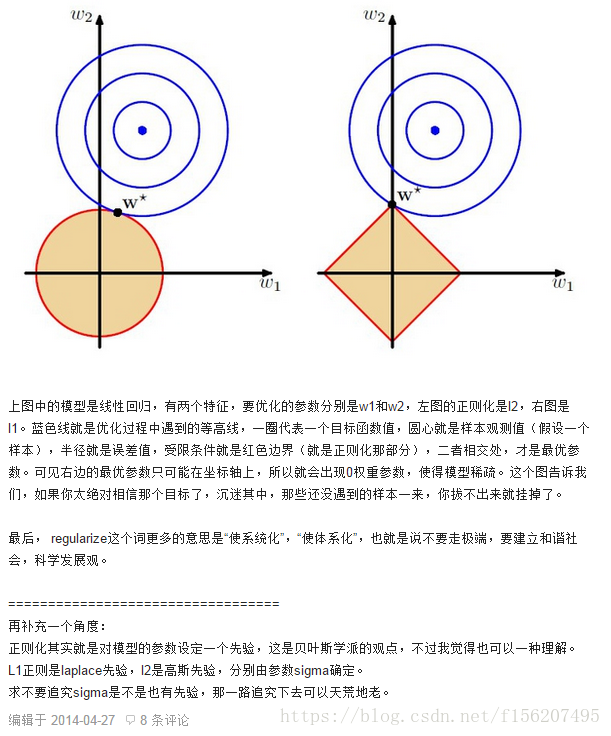
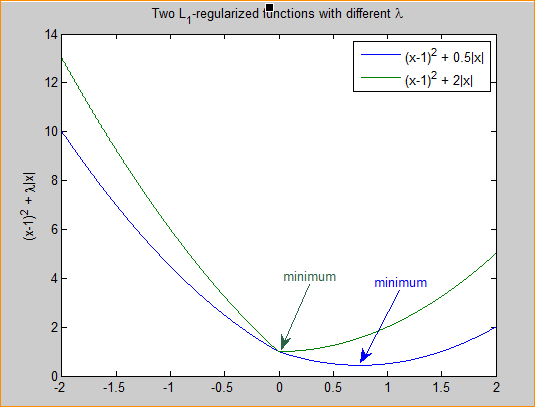
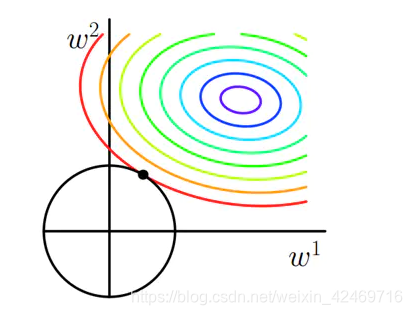
在上述的公式中, min 1 2 m Σ i = 1 m ( f ( x ) − y ( i ) ) 2 \min \frac{1}{2m} \Sigma_{i=1}^{m}\left(f(x)-y^{(i)}\right)^{2} min2m1Σi=1m(f(x)−y(i))2是原始的损失函数,也称为经验误差,在此基础上,加入了L1正则项 λ ∥ w ∥ 1 \lambda\|w\|_{1} λ∥w∥1,L1正则项是权重向量中各元素的绝对值之和,所造成的一个后果就是损失函数不是完全可微。模型训练的目的是令损失函数达到全局最小值,当在原始的损失函数之后加入L1正则项之后,相当于对权重向量做了约束,此时我们的任务变为了在L1约束条件下求得损失函数的最小值。由于高维的情况无法用图像形象的描述出来,我们这里考虑二维的情况,即只有两个权重值 w 1 w_{1} w1和 w 2 w_{2} w2此时对损失函数应用梯度下降法,求解过程中可以画出等值线,如下图所示:

图中等值线是原始损失函数的等值线,黑色方形是L1正则化项的图形。在图中,当彩色等值线与黑色图形首次相交的地方就是最优解。上图中原始损失函数与L1在一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多突出的顶点(二维情况下四个,多维情况下更多),彩色等值线与这些角接触的机率会远大于与黑色图形其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏效果,进而可以用于特征选择。
L2正则化的直观理解
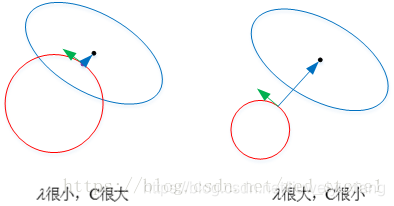
不管是L1正则化还是L2正则化,在拟合的过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型,因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,抗干扰能力强。原因是权重对输入的数据影响小,所以抗干扰能力强。
考虑损失函数在二维的情况,即只有两个权重值 w 1 w_{1} w1和 w 2 w_{2} w2,此时对损失函数应用梯度下降法,求解过程中可以画出等值线,如下图所示:

二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此 J 0 J_{0} J0与L相交时使得 w 1 w_{1} w1或 w 2 w_{2} w2等于零的机率小了许多,这就是为什么 L 2 L_{2} L2正则化不具有稀疏性的原因。