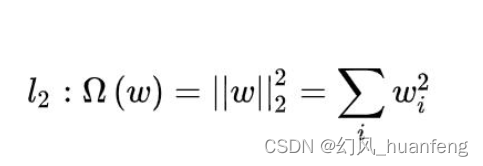“回车”、“换行”浅谈
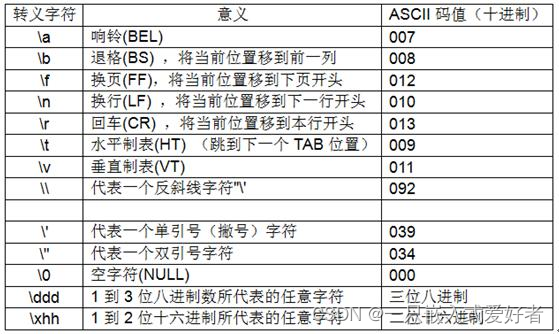
转义字符'\r'表示回车(carriage return)即回到行首,并没有包含换行的动作, '\n'表示换行(line feed)即移动到新的一行(下一行)。顺便提及,'\b'表示退格(BS, Backspace),是往前退一格。下面给出这三个转义字符值及其含义:
转义字符 ASCII码值(十进制) 含义
\b 8 退格
\n 10 换行
\r 13 回车
【转义字符(Escape Character)是很多程序语言、数据格式和通信协议的形式文法的一部分。对于一个给定的字母表,一个转义字符的目的是开始一个字符序列,使得转义字符开头的该字符序列具有不同于该字符序列单独出现(没有转义字符开头)时的语义。转义序列通常有两种功能。第一个是编码一个句法上的实体,如设备命令或者无法被字母表直接表示的特殊数据。第二种功能,也叫字符引用,用于表示无法在当前上下文中被键盘录入的字符(如字符串中的回车符),或者在当前上下文中会有不期望的含义的字符(如C语言字符串中的双引号字符",不能直接出现,必须用转义序列表示)。——取自维基百科】
下面给出验证代码
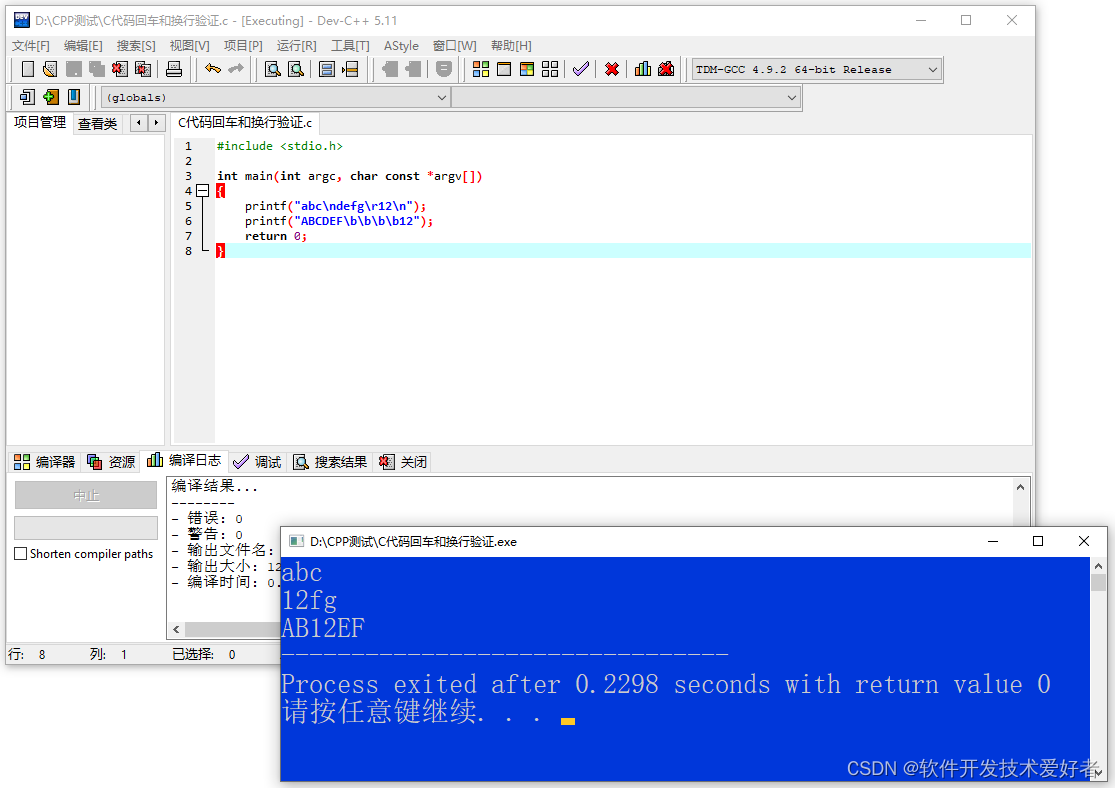
C验证源码如下:
#include <stdio.h>int main(int argc, char const *argv[])
{printf("abc\ndefg\r12\n");printf("ABCDEF\b\b\b\b12");return 0;
}
用Dev-C++编译运行之:
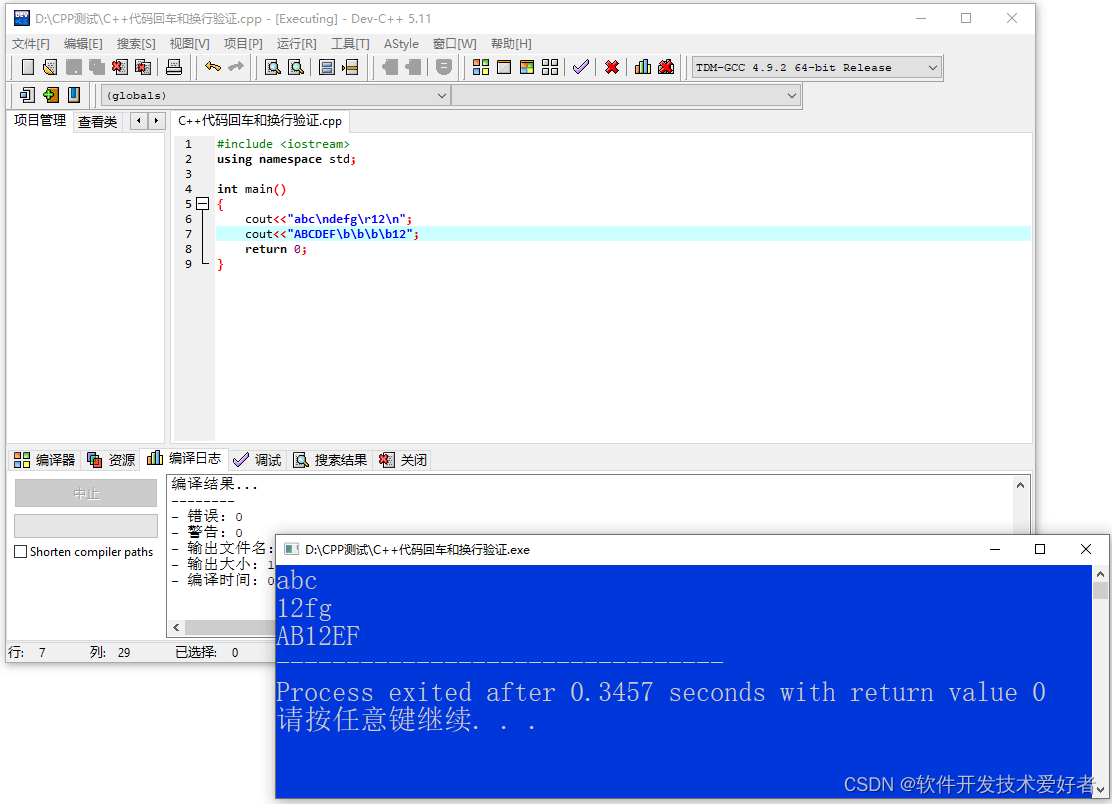
C++验证源码如下:
#include <iostream>
using namespace std;int main()
{cout<<"abc\ndefg\r12\n";cout<<"ABCDEF\b\b\b\b12";return 0;
}
用Dev-C++编译运行之:
按下Enter键输入的是什么?
Windows系统里面,是“ <回车><换行>”,即:“\r\n”;
Unix和Linux系统里,只有“<换行>”,即:“\n”;
Mac系统里,是“<回车>”,即:“\r”。
当在不同的系统间传递文件,就要涉及格式的转换。
参考
关于“回车”的有趣历史 及 “回车”与“换行”的区别 - 幽曲 - 博客园
回车符和换行符区别 - uTank - 博客园


![[PTA]习题8-2 在数组中查找指定元素](https://img-blog.csdnimg.cn/1d555e2dc5c94764aff23658e02e9568.png)
![[PTA]实验8-1-5 在数组中查找指定元素](https://img-blog.csdnimg.cn/62eaa40e868542e19bb5291c784c3392.png)