回车和换行的区别
- 回车和换行的概念
- 不同的系统间传递文件会涉及格式的转换
- Unix -> Windows
- Unix <- Windows
回车和换行的概念
首先介绍一下“回车”(carriage return,’\r’)和“换行”(line feed,’\n’)这两个概念的来历和区别。在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做“回车”,告诉打字机把打印头定位在左边界;另一个叫做“换行”,告诉打字机把纸向下移一行。这就是“换行”和“回车”的来历,从它们的英语名字上也可以看出一二。
| 符号 | ASCII码 | 意义 |
|---|---|---|
| \n | 10 | 换行NL |
| \r | 13 | 回车CR |
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧:
- Unix 系统里,每行结尾只有“<换行>”,即“\n”;
- Windows系统里面,每行结尾是“<回车><换行>”,即“\r\n”;
- Mac系统里,每行结尾是“<回车>”,即“\r”。
一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。一些常见的转义字符如下图:
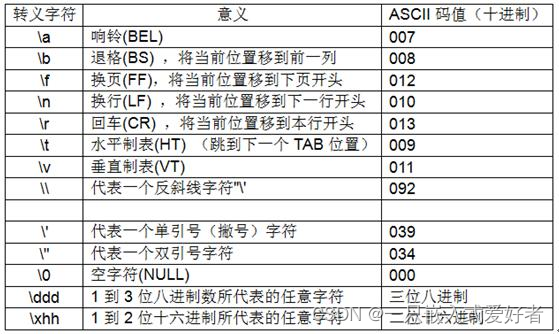
需要注意的是:在Windows系统中回车键被当做\r\n 的组合来使用,当我们从键盘输入回车键时,Windows系统会把回车键当做\r\n 来处理,Unix系统只会当做\n 来处理,不管在什么系统中,都可以用\n来作为一行输入结束的标记,只是在编程时我们需要注意,在Windows系统中我们会读到\r 这个字符,我们必须把\r和正常输入的字符区别开来。
Windows与Unix文件格式是不同的,问题一般就是出在\r\n问题上。回车(CR)和换行(LF)符都是用来表示“下一行”的。而标准没有规定要使用哪一个。于是产生了三种不同的用法:
- windows采用回车+换行(CR+LG)表示下一行(亦即所谓的PC格式)
- UNIX采用换行符(LF)表示下一行
- MAC机采用回车符(CR)表示下一行
不同的系统间传递文件会涉及格式的转换
当在不同的系统间传递文件,就要涉及格式的转换。两种文件格式之间的转化:
Unix -> Windows
1、Unix -> Windows:‘\n’ -> ‘\r\n’
while ( (ch = fgetc(in)) != EOF )
{if ( ch == '\n' )putchar('\r');putchar(ch);
}
只要在Unix文件中出现的’\n’的之前加入一个’\r’字符就可以了
Unix <- Windows
2、Unix <- Windows:‘\n’ <- ‘\r\n’
从Windows到Unix的情况复杂点,不能只是把从文件中读出的’\r’去掉就可以了。因为Windows文件中的文本行的末尾有时会内嵌一个回车符号,这种情况在击打式打印机中出现。所以在转换前要判断’\r’是否和’\n’同时出现。如果同时出现,则去掉’\r’,如果没有同时出现,保留’\n’。
cr_flag = 0; /* No CR encountered yet */while ( (ch = fgetc(in)) != EOF )
{if ( cr_flag && ch != '\n' ) {/* This CR did not preceed LF */putchar('\r');}if ( !(cr_flag = (ch == '\r')) )putchar(ch);
}

![[PTA]习题8-2 在数组中查找指定元素](https://img-blog.csdnimg.cn/1d555e2dc5c94764aff23658e02e9568.png)
![[PTA]实验8-1-5 在数组中查找指定元素](https://img-blog.csdnimg.cn/62eaa40e868542e19bb5291c784c3392.png)