产生背景
地理空间数据涉及各种海量且复杂的数据,找到合适的索引对空间数据的处理至关重要。
传统的B树索引针对字符、数字等一维属性数据的主关键字而设计,不适用于具有多维性的地理空间数据。
在GIS和CAD系统对空间索引需求的推动下,为满足二维及多维空间数据快速检索与分析, Guttman于1984年提出了R树索引结构。
定义
R树是一种多级平衡树,它是B树在多维空间上的扩展。其运用了空间分割的理念,存放的并不是原始数据,而是数据的最小边界矩形(MBR ),是用来做空间数据存储的树状数据结构。
原理
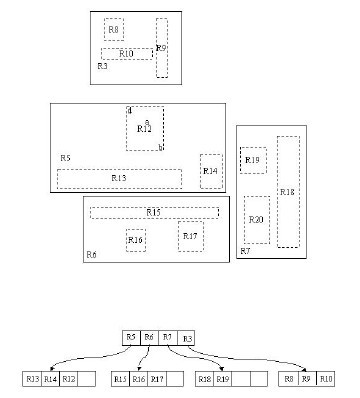
为实现R树结构,用最小边界矩形恰好框住各数据围成的一个区域(在图中用实线矩形表示),得到若干个最小边界矩形,如R8,R9,R10,R11等。
其中R8,R9,R10三个矩形距离最近,用一个更大的矩形R3(在图中用虚线矩形表示)框住三个矩形。
通过不断的迭代,用更大的矩形框住所有矩形。
将所有大大小小的矩形存入R树中。

性质
每个结点所能拥有的子结点数目有上下限。除根结点之外的所有结点包含有m至M个记录索引(条目)。通常,m=M/2。
对于非叶结点上的记录,R树的非叶子结点存放的数据结构为:(I, child-pointer)。child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。
对于叶结点上的记录,叶结点所保存的数据形式为:(I, tuple-identifier)。其中,tuple-identifier表示的是存放于数据库中的一条记录。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。
R树的衍生
R+树:主要区别在于R+树中兄弟结点对应的空间区域无重叠。
优点:减少了无效查询数,大大提高了空间索引的效率
缺点:由于操作要保证空间区域无重叠而降低了插入、删除空间对象操作的效率
R*树:1990年提出的最佳动态R树的变种。
优点:对结点的插入、分裂算法进行了改进,采用“强制重新插入”方法使树的结构得到优化
缺点:仍然不能有效降低空间的重叠程度,在数据量大、维数增加时尤为明显。
存在问题
R树主要考虑了外接矩形的面积,而影响检索性能的参数有很多。
目录矩形所覆盖的面积应该最小化。
不同路径间矩形的重叠应该最小化。
减少需要被遍历的路径数目
存储时的空间利用率应当优化。
欢迎大家加我微信交流讨论(请备注csdn上添加)