Java的Jsoup爬虫,爬携程酒店评分,保存数据库中
- 前言
- 一、Jsoup爬虫pom
- 二、逻辑代码部分
- 1.首先我们要先确定爬取的东西,这边我就以携程的酒店评分为例子。
- 2.Jsoup进行解析具体要求爬的内容
- 3.接下来我们就是将爬取的数据存入数据库中
- 总结
前言
很多人都知道爬虫,然后这里就简单的介绍一下java爬虫的使用。
好啦,话不多说进入正题!
一、Jsoup爬虫pom
java使用爬虫就要用到爬虫的pom文件
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version></dependency>
想要使用Jsoup进行爬虫就要使用到上面的pom文件。
二、逻辑代码部分
1.首先我们要先确定爬取的东西,这边我就以携程的酒店评分为例子。

首先先要用代码去获得这个页面的路径
//1.生成httpclient,相当于该打开一个浏览器CloseableHttpClient httpClient = HttpClients.createDefault();CloseableHttpResponse response = null;//2.创建get请求,相当于在浏览器地址栏输入 网址HttpGet request = new HttpGet("https://hotels.ctrip.com/hotels/list?countryId=1&city=2&checkin=2021/08/09&checkout=2021/08/10&optionId=781302&optionType=Hotel&directSearch=0&optionName=%E5%B4%87%E6%98%8E%E9%87%91%E8%8C%82%E5%87%AF%E6%82%A6%E9%85%92%E5%BA%97&display=%E5%B4%87%E6%98%8E%E9%87%91%E8%8C%82%E5%87%AF%E6%82%A6%E9%85%92%E5%BA%97%2C%20%E4%B8%8A%E6%B5%B7%2C%20%E4%B8%AD%E5%9B%BD&crn=1&adult=1&children=0&searchBoxArg=t&travelPurpose=0&ctm_ref=ix_sb_dl&domestic=1&");//设置请求头,将爬虫伪装成浏览器request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");这时候就模拟浏览器访问到了这个页面
2.Jsoup进行解析具体要求爬的内容
我们这边是要获取酒店的评分

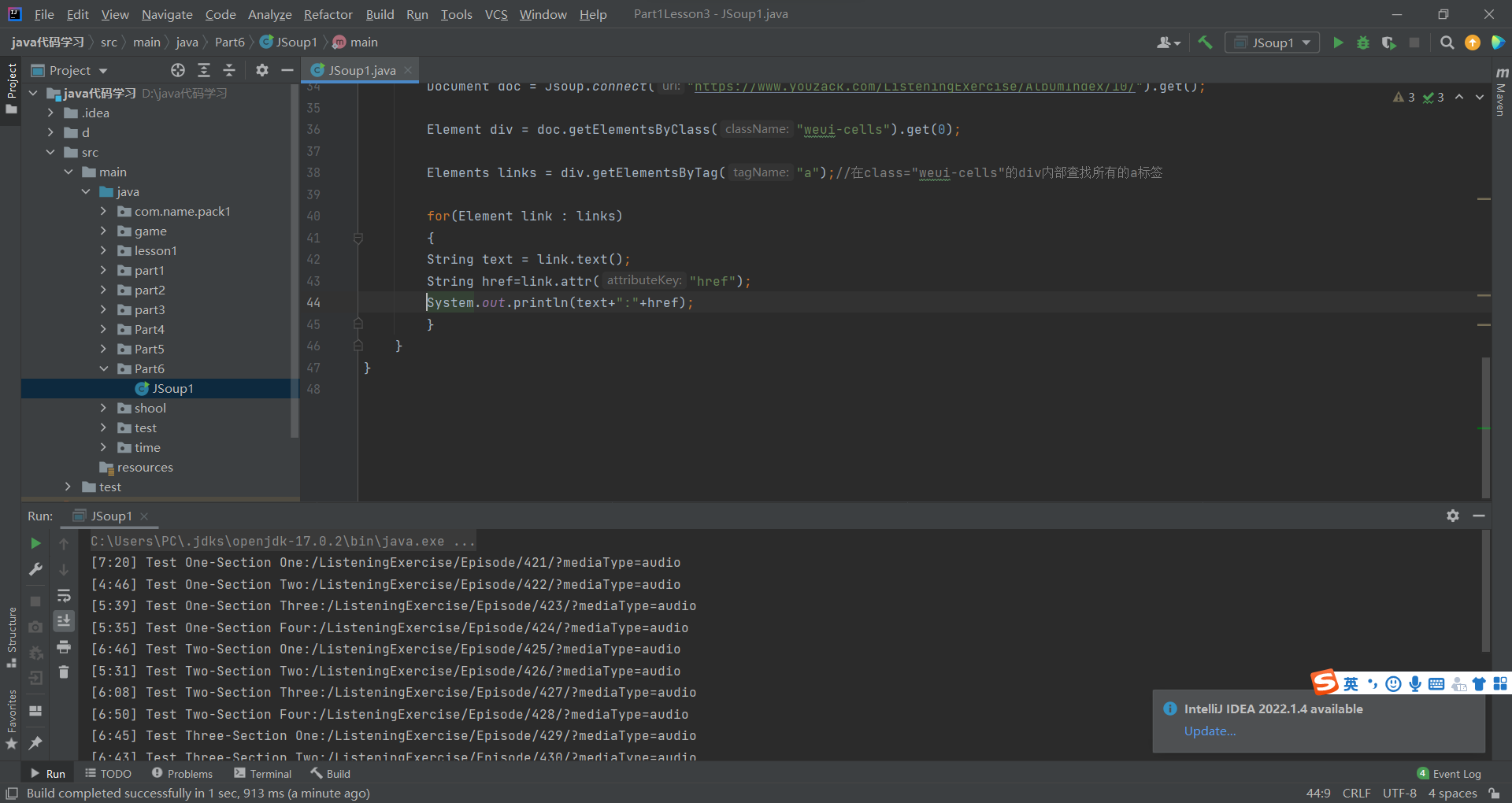
首先进入页面f12,然后用鼠标抓取评分,就会有score出来,这就是我们需要爬取的东西,接下来就是用代码的形式进行爬取。
Document document = Jsoup.parse(html);
// //像js一样,通过标签获取title//像js一样,通过id 获取元素对象Element postList = document.getElementById("ibu_hotel_container");//像js一样,通过class 获取列表下的所有scoreElements postItems = postList.getElementsByClass("score");System.err.println("----------------"+postItems);Elements titleEle = postItems.select(".score span[class='real font-bold']");System.err.println("评分:" + titleEle.text());
这样我们就成功的将酒店的评分爬取到了。
3.接下来我们就是将爬取的数据存入数据库中
为了方便观看,这里也将酒店的名称也爬取出来
Elements nameItems = postList.getElementsByClass("list-card-title");for (Element nameItem : nameItems) {Elements titleEle01 = nameItem.select(".list-card-title span[class='name font-bold']");System.err.println("酒店名称:"+titleEle01.text());}
想要将数据存入数据库,我们首先需要编写一个pojo对象
为了更加方便直观的观看数据,我这里给数据加了id以及time
public class Lottery {@TableId(type = IdType.AUTO)private Integer id;private String name;private String score;@TableField(fill = FieldFill.INSERT)private String time;}
接着就是mapper
@Mapper
public interface LotteryMapper extends BaseMapper<Lottery> {
}
然后使用通用mapper就可以直接存入数据库
Document document = Jsoup.parse(html);
// //像js一样,通过标签获取title
// System.out.println(document.getElementsByTag("title").first());//像js一样,通过id 获取文章列表元素对象Element postList = document.getElementById("ibu_hotel_container");//像js一样,通过class 获取列表下的所有博客Elements postItems = postList.getElementsByClass("score");//循环处理每篇博客System.err.println("----------------" + postItems);Elements titleEle = postItems.select(".score span[class='real font-bold']");System.err.println("评分:" + titleEle.text());Lottery lottery = new Lottery();lottery.setScore(titleEle.text());Elements nameItems = postList.getElementsByClass("list-card-title");for (Element nameItem : nameItems) {Elements titleEle01 = nameItem.select(".list-card-title span[class='name font-bold']");System.err.println("酒店名称:" + titleEle01.text());
// Lottery lottery = new Lottery();lottery.setName(titleEle01.text());list.add(lottery);System.out.println("---------------------");}lotteryMapper.insert(lottery);接下来看一下数据库中是否有数据

我们这里看一看到有成功爬取的数据。
总结
关于java爬虫的东西就到这里了,有不足之处还望指出来。