一、Jsoup概述
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
主要功能:
1. 从一个URL,文件或字符串中解析HTML;
2. 使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;
二、jsoup爬取图片
以 https://www.hellorf.com/image/search 网站为例,根据关键词爬取相关的图片。
项目依赖
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version></dependency>

当我们直接在网页中搜索的时候,是可以看见浏览器地址栏上的信息的,我们将 “”https://www.hellorf.com/image/search?q=煎饼果子“”复制到Java代码中去发现要搜索的关键字被压缩编码了。

原因是请求头的编码为gzip
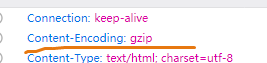
这时要使用一些字节数据将输入的汉字正确处理为编码后的值,这里写了一个gzip的工具类。
public class GzipUtils {public static void main(String[] args) throws IOException {String str = "煎饼果子";byte[] bytes = str.getBytes();byte[] gzipBytes = gzip(bytes);byte[] unGzipBytes = unGzip(gzipBytes);String value = byteToHexString(unGzipBytes);String finalString = getFinalString(str);System.out.println(value);System.out.println(finalString);}public static byte[] gzip(byte[] content) throws IOException {ByteArrayOutputStream baos = new ByteArrayOutputStream();GZIPOutputStream gos = new GZIPOutputStream(baos);ByteArrayInputStream bais = new ByteArrayInputStream(content);byte[] buffer = new byte[1024];int n;while ((n = bais.read(buffer)) != -1) {gos.write(buffer, 0, n);}gos.flush();gos.close();return baos.toByteArray();}public static byte[] unGzip(byte[] content) throws IOException {ByteArrayOutputStream baos = new ByteArrayOutputStream();GZIPInputStream gis = new GZIPInputStream(new ByteArrayInputStream(content));byte[] buffer = new byte[1024];int n;while ((n = gis.read(buffer)) != -1) {baos.write(buffer, 0, n);}return baos.toByteArray();}public static String byteToHexString(byte[] bytes) {StringBuffer sb = new StringBuffer(bytes.length);String sTemp;for (int i = 0; i < bytes.length; i++) {sTemp = Integer.toHexString(0xFF & bytes[i]);if (sTemp.length() < 2)sb.append(0);sb.append(sTemp.toUpperCase());}return sb.toString();}public static String getFinalString(String str) throws IOException {//1.转字节数组byte[] bytes = str.getBytes();//2.压缩字节数组byte[] gzip = gzip(bytes);//3.将压缩的字节数组再解压byte[] unGzip = unGzip(gzip);//4.将解压的字节数组转为字符串String value = byteToHexString(unGzip);StringBuilder stringBuilder = new StringBuilder();stringBuilder.append("%");int count = 0; // %E5%A4%A7%E9%97%B8%E8%9F%B9for (int i = 0;i < value.length();i++){count++;if (count == 3){count = 1;stringBuilder.append("%");}char charStr = value.charAt(i);stringBuilder.append(charStr);}return stringBuilder.toString();}}
运行main方法后查看控制台

这样就和编码后的数据一致了。

爬虫代码编写
public class HtmlParseUtils {public static void main(String[] args) throws IOException {String str = "煎饼果子";String finalString = GzipUtils.getFinalString(str);List<String> list = parseImg(finalString);for (String s : list) {System.out.println(s);}}public static List<String> parseImg(String keywords) throws IOException {ArrayList<String> images = new ArrayList<>();String url = "https://www.hellorf.com/image/search?q=" + keywords;Document document = Jsoup.parse(new URL(url),9999);//Elements img = document.getElementsByTag("img");List<Element> elements = document.getElementsByTag("img").subList(0, 5);for (Element element : elements) {String src = element.attr("data-src");if (src == null || "".equals(src)){src = element.attr("src");}images.add(src);}return images;}
}控制台查看结果: