什么是爬虫
1、爬虫:程序代替人的人工操作,自动获取网页内容,并且从其中提取出来有价值信息。
2、原始:调用Http的类向服务器发出请求,获得HTML,然后用正则表达式等去分析。缺点:难度高。
3、Jsoup:简单易用的Http请求操作以及查找元素的操作。
Maven包名:jsoup
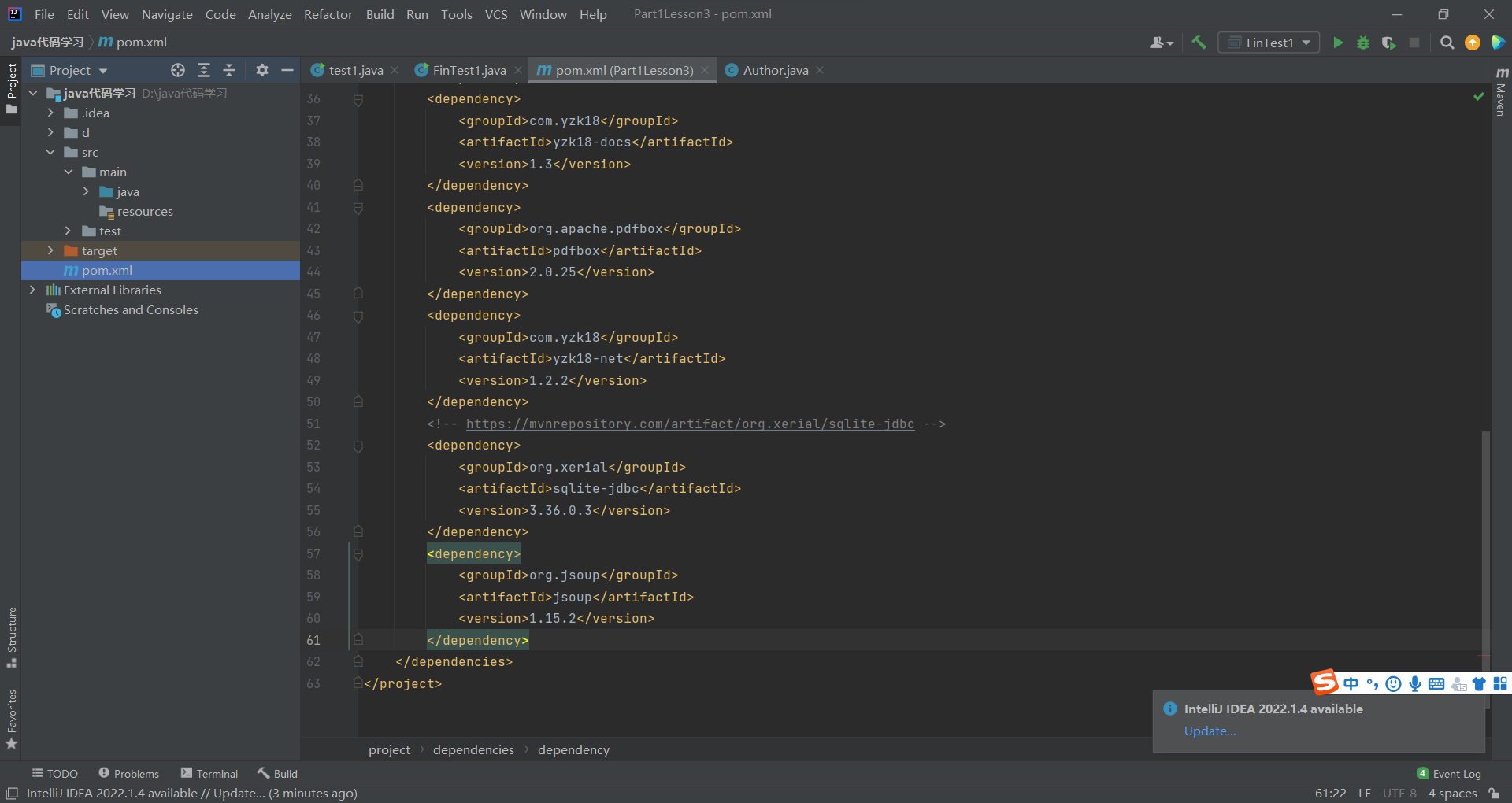
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.2</version>
</dependency>
导入包
Jsoup基本使用
Document doc = Jsoup.connect(“https://www.youzack.com/”).get();//发出请求
Element tucao = doc.getElementById(“tucao”);//使用唯一id查找元素
String href = tucao.attr(“href”);//获取元素属性
String text = tucao.text();//获取元素内部文本
System.out.println(href+":"+text);
选择jsoup.nodes别选错
用框架就很简单实现
package Part6;import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;import java.io.IOException;public class JSoup1 {public static void main(String[] args) throws IOException {Document doc = Jsoup.connect("https://www.youzack.com/").get();//发出请求Element link = doc.getElementById("tucao");//使用唯一id查找元素String href = link.attr("href");//获取元素属性String text = link.text();//获取元素内部文本System.out.println(href+":"+text);System.out.println(text);}
}
Jsoup其他定位元素的方法
根据标签查找元素: getElementsByTag(String tag)
根据class查找元素: getElementsByClass(String className)
根据属性查找元素: getElementsByAttribute(String key)
兄弟遍历方法: siblingElements(), firstElementSibling(), lastElementSibling(); nextElementSibling(), previousElementSibling()
层级之间遍历: parent(), children(), child(int index)
应用案例:获取网页中所有的超链接;获取youzack听力中某个专辑下所有的音频名字;
应用案例1
获取网页中所有的超链接
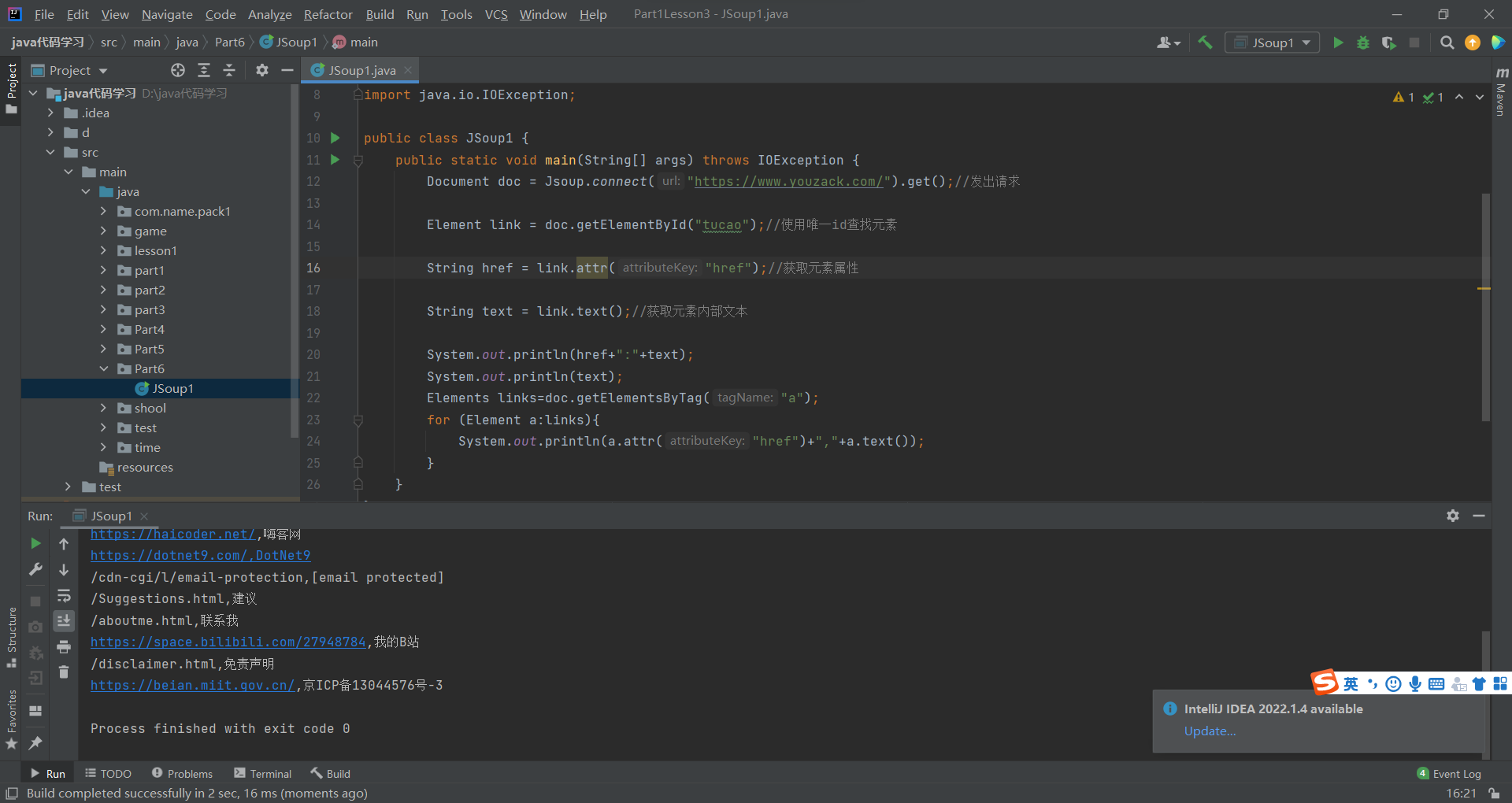
Elements links = doc.getElementsByTag("a");
for(Element link: links)
{
String href = link.attr("href");
String text = link.text();
System.out.println(href+":"+text);
}
package Part6;import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;import java.io.IOException;public class JSoup1 {public static void main(String[] args) throws IOException {Document doc = Jsoup.connect("https://www.youzack.com/").get();//发出请求Element link = doc.getElementById("tucao");//使用唯一id查找元素String href = link.attr("href");//获取元素属性String text = link.text();//获取元素内部文本System.out.println(href+":"+text);System.out.println(text);Elements links=doc.getElementsByTag("a");for (Element a:links){System.out.println(a.attr("href")+","+a.text());}}
}
抓图片的路径
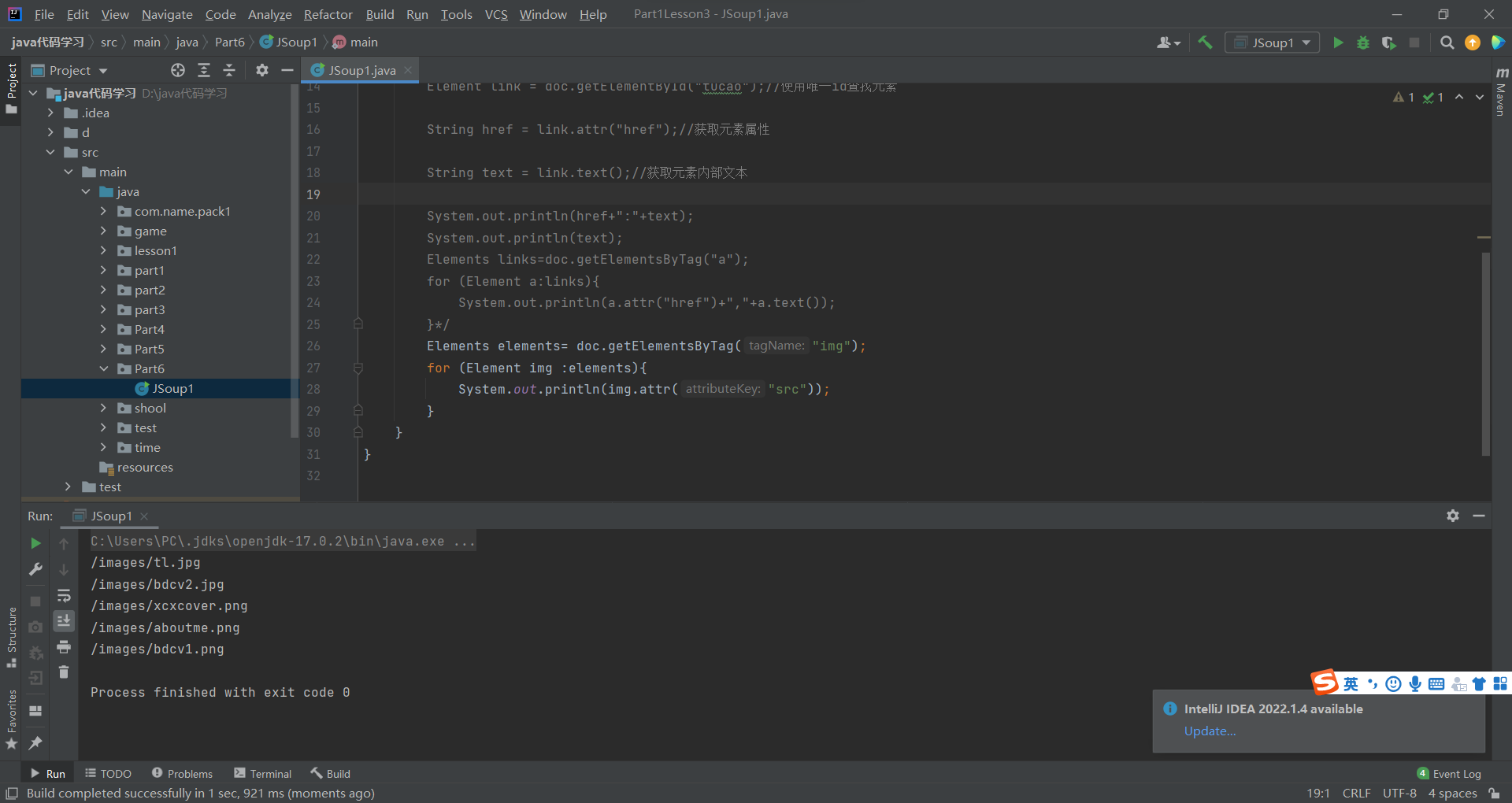
Elements elements= doc.getElementsByTag("img");for (Element img :elements){System.out.println(img.attr("src"));}多个class下的文本爬取
Elements covers=doc.getElementsByClass("cover");for (Element text :covers){System.out.println(covers.text());}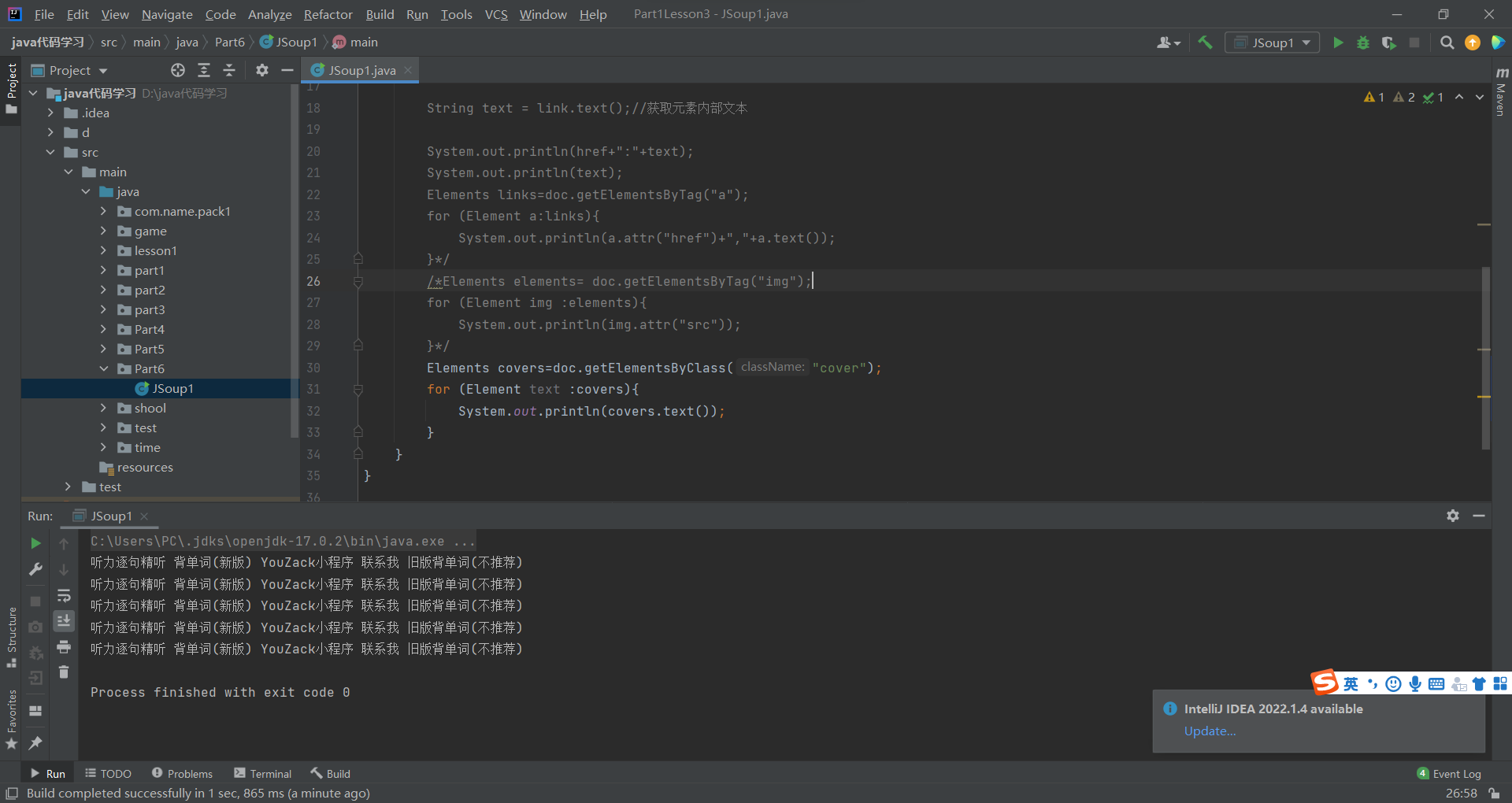
应用案例2
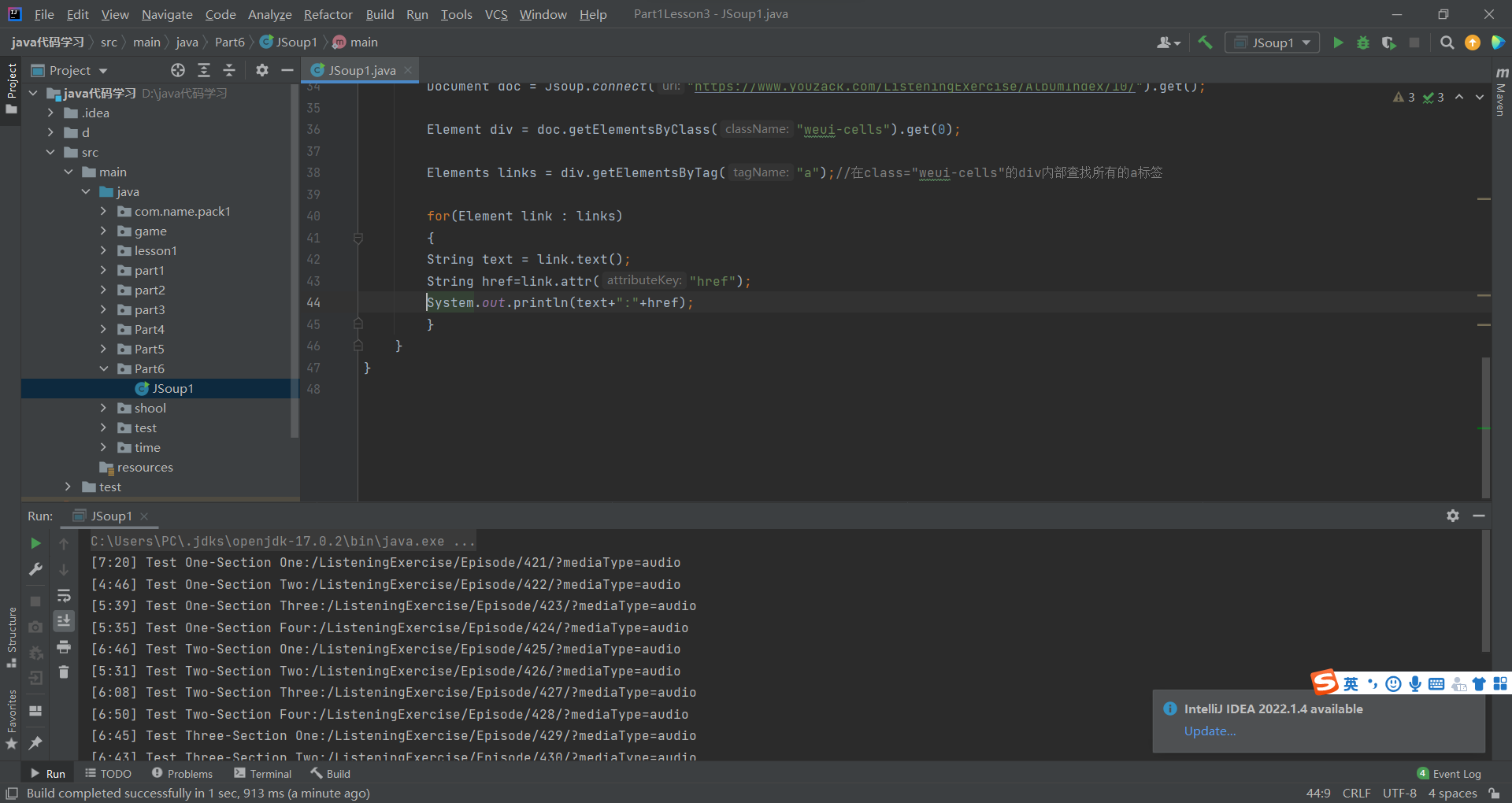
获取youzack听力中某个专辑下所有的音频名字
Document doc = Jsoup.connect("https://www.youzack.com/ListeningExercise/AlbumIndex/10/").get();
var weui_cells = doc.getElementsByClass("weui-cells").get(0);
Elements links = weui_cells.getElementsByTag("a");
for(Element link : links)
{
String text = link.text();
System.out.println(text);
}
package Part6;import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;import java.io.IOException;public class JSoup1 {public static void main(String[] args) throws IOException {
// Document doc = Jsoup.connect("https://www.youzack.com/").get();//发出请求/*Element link = doc.getElementById("tucao");//使用唯一id查找元素String href = link.attr("href");//获取元素属性String text = link.text();//获取元素内部文本System.out.println(href+":"+text);System.out.println(text);Elements links=doc.getElementsByTag("a");for (Element a:links){System.out.println(a.attr("href")+","+a.text());}*//*Elements elements= doc.getElementsByTag("img");for (Element img :elements){System.out.println(img.attr("src"));}*//*Elements covers=doc.getElementsByClass("cover");for (Element text :covers){System.out.println(covers.text());}*/Document doc = Jsoup.connect("https://www.youzack.com/ListeningExercise/AlbumIndex/10/").get();Element div = doc.getElementsByClass("weui-cells").get(0);Elements links = div.getElementsByTag("a");//在class="weui-cells"的div内部查找所有的a标签for(Element link : links){String text = link.text();String href=link.attr("href");System.out.println(text+":"+href);}}
}









![[读书笔录]解析卷机神经网络(魏秀参)——第二章](https://img-blog.csdn.net/20180115175311216?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcG9pc29uMTAxOQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
![[读书笔录]解析卷机神经网络(魏秀参)——第三章](https://img-blog.csdn.net/20180920114413474?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3BvaXNvbjEwMTk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
![[读书笔录]解析卷积神经网络(魏秀参)——第一章](https://img-blog.csdn.net/20180223110231569?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcG9pc29uMTAxOQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)