前言:在日常开发中,我们必定是与我们的数据源打交道,我们的数据源无非就那么几个 1.数据库2.爬虫数据 3.第三方系统交互,这里介绍java 中网页版的爬虫jsoup的使用
1.首先导入我们的jar包 maven坐标如下
org.jsoup
jsoup
1.13.1
一个是jsoup的核心功能包 另一个是阿里的json包
这里我默认你是会自己创建一个boot项目的,如果不会请自行百度。
首先根据网路上大多数教程
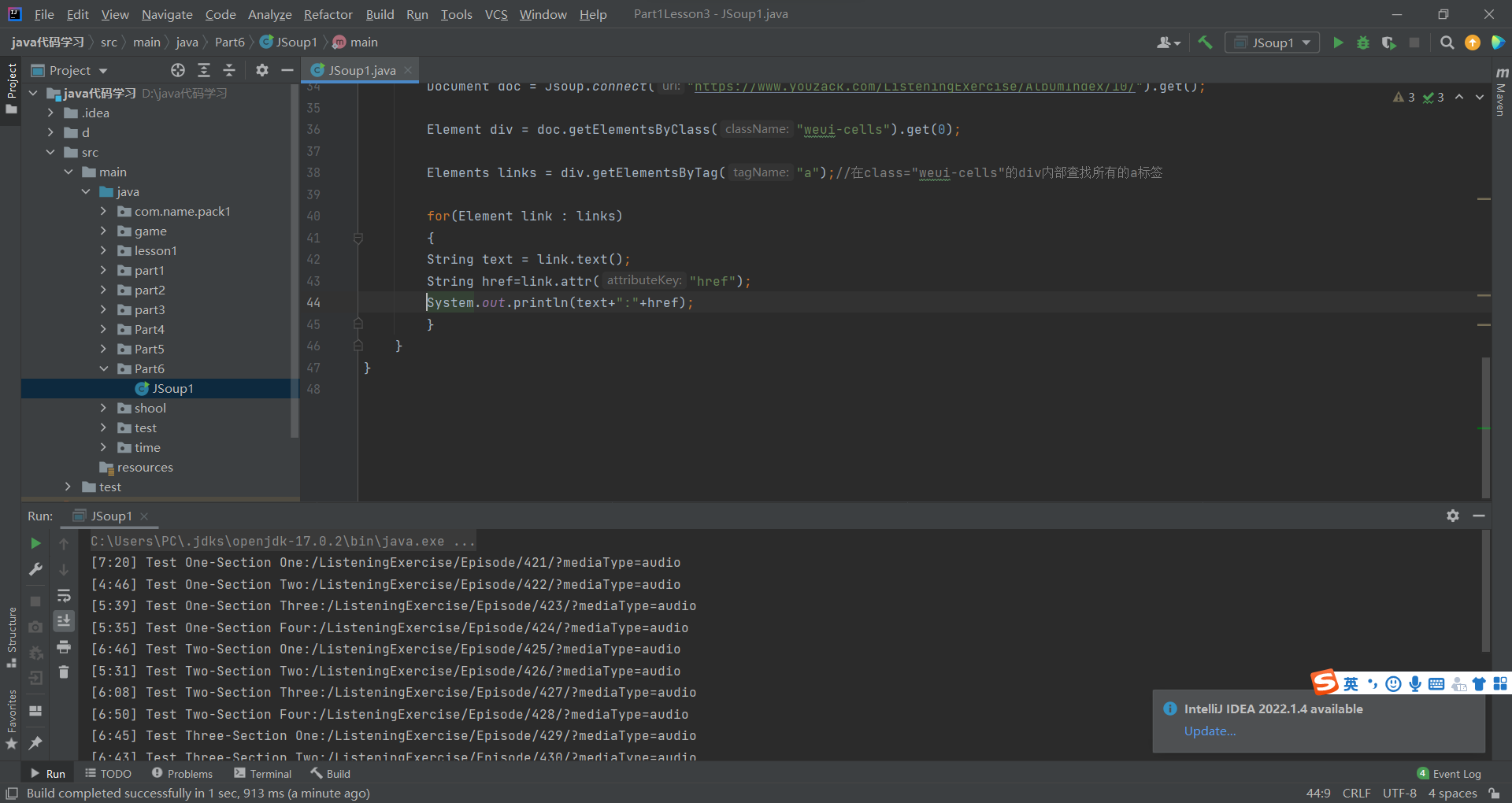
public static void main(String[] args) throws IOException {String url="http://www.jinmalvyou.com/hotel/index";//返回js页面 就是普通的页面的documentDocument parse = Jsoup.parse(new URL(url), 300000);// Connection connect = Jsoup.connect(url).timeout(6000);Element j_goodsList = parse.getElementById("J_goodsList");System.out.println(j_goodsList.html());}
这时不出意外你会看到跟我一样的报错
Caused by: java.net.ConnectException: Connection refused: no further information

这时我们更换我们的jsoup连接方法
//爬虫测试
@Test
void testJsoup() throws IOException {
String url="https://search.jd.com/Search?keyword=java";Document document = Jsoup.connect(url).timeout(6000).get();
Element j_goodsList = document.getElementById("J_goodsList");
System.out.println(j_goodsList.html());
}
运行结果为:

我们看到我们拿到了某东的java搜索页面 当年拿到了连接的document时你就可以对你拿到的数据进行转换入库啦