一、简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。(来源百度)
二、准备
首先你需要找到一个你需要爬取数据的网站,找到你需要的数据所在HTML中的定位
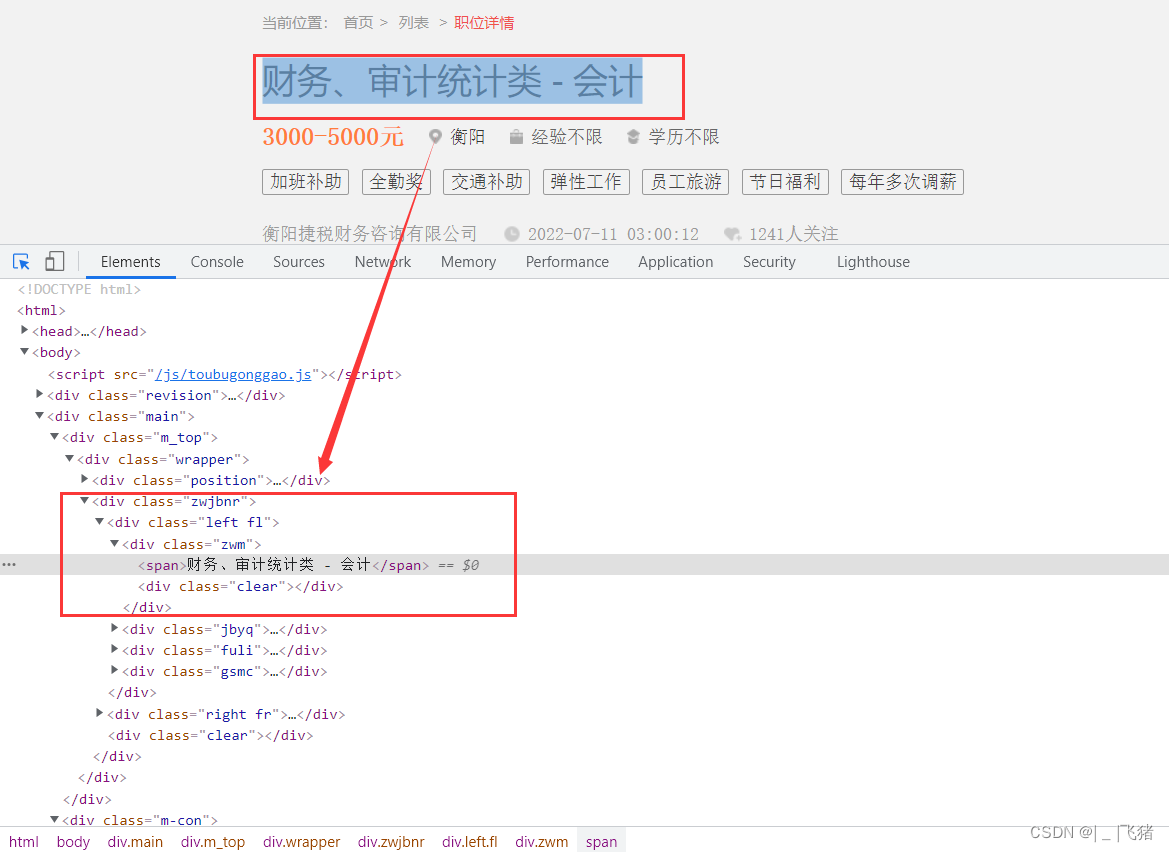
可以根据下面这个指令查看你定位是否正确
document.querySelector(".zwm").innerText
下面事具体实现:
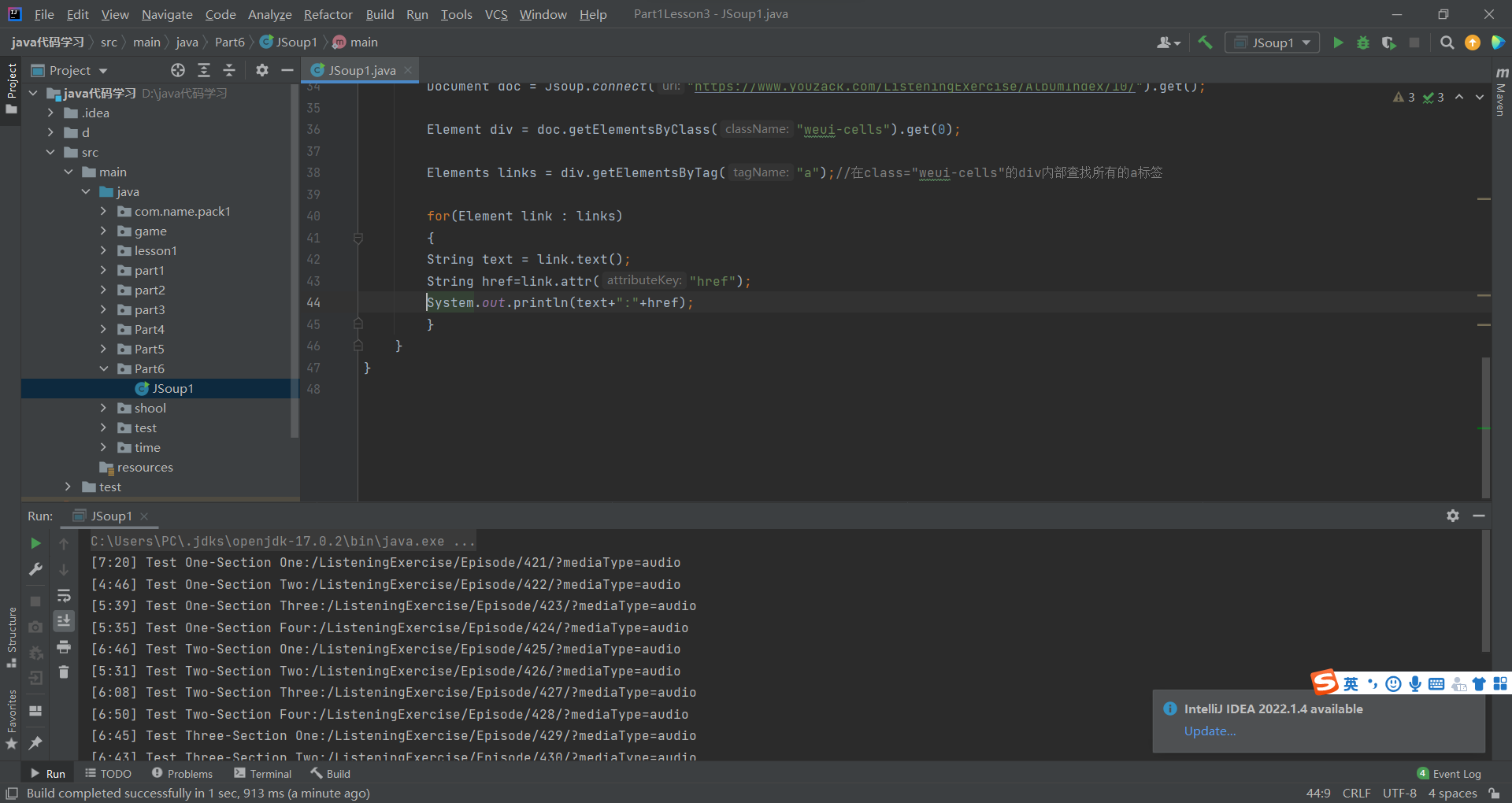
public static void collectSingle() throws IOException{//获取5页公司数据for (int i = 1; i <=5; i++) {//获取页面文本的地址 地址省略了String addr = "http://www.*****.com/job/p"+i+".shtml";URL url = new URL(addr);Document doc = Jsoup.parse(url,5000);//解析内容,提取数据Elements as = doc.select("a.comName");as.forEach(a->{String href = a.attr("href");href = "http://www.*****.com"+href;//插入数据库的sql语句String sql = "insert into com values (?,?,?,?,?,?,?,?,?)";try{//提取地址中的idString sid = href.replaceAll("\\D+(\\d+)\\.shtml","$1");int id = Integer.parseInt(sid);SpiderHelper.collectSingle(href,sql,id,".zwm>span",".zwm>em",".gsmc:nth-child(2)",".jbyq",//要求".fuli",//福利".gsmc>a>span",//公司名称".gsmc>span",//发布时间".zwmsCon",//简介".gzddCon>span");} catch (IOException e) {e.printStackTrace();}catch (RuntimeException e){//跳过DBhelper产生的运行是异常===》相同的公司数据}});}}查看数据库,运行成功!











![[读书笔录]解析卷机神经网络(魏秀参)——第二章](https://img-blog.csdn.net/20180115175311216?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcG9pc29uMTAxOQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)