HashMap位置决定与存储
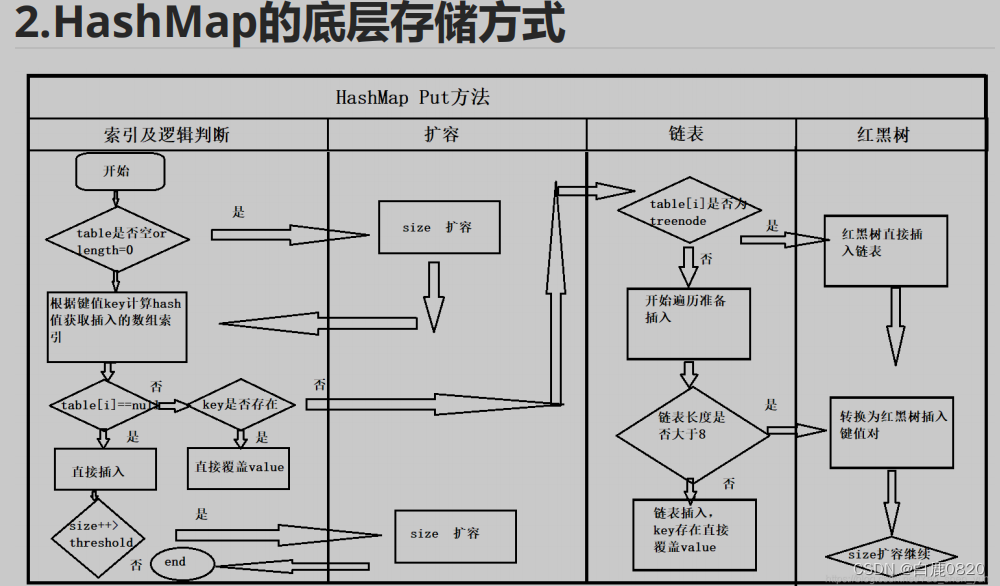
通过前面的源码分析可知,HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。源码如下:
public V put(K key, V value) {
if (key == null) return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry < K, V > e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length - 1);
}
static class Entry < K,
V > implements Map.Entry < K,
V > {
final K key;
V value;
Entry < K,
V > next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry < K, V > n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (! (o instanceof Map.Entry)) return false;
Map.Entry e = (Map.Entry) o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2))) return true;
}
return false;
}
public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^ (value == null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that‘s already
* in the HashMap.
*/
void recordAccess(HashMap < K, V > m) {}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap < K, V > m) {}
}
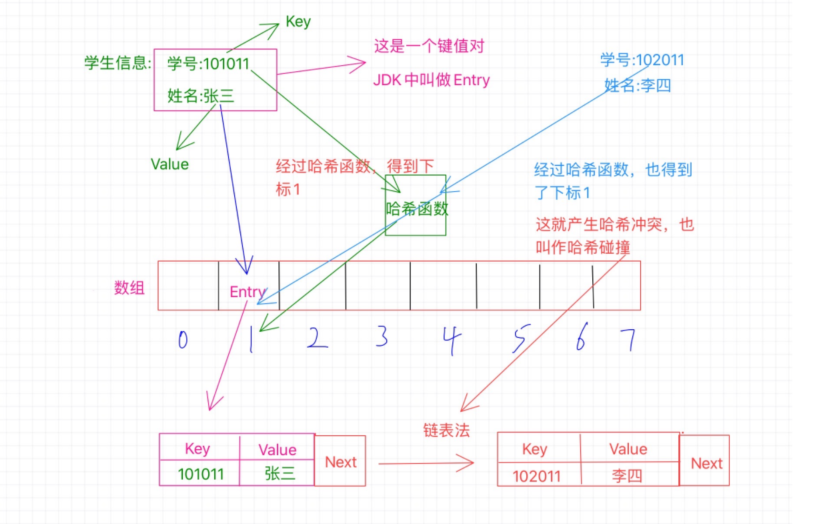
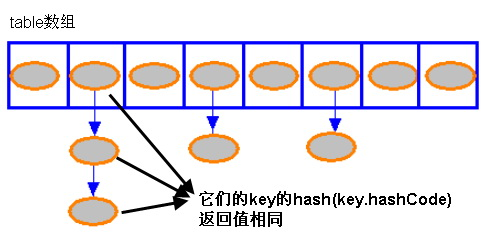
我们知道Entry含有的属性是Value,Key,还有一只指向下一个指针Next。当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置。这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可
Hash碰撞产生及解决
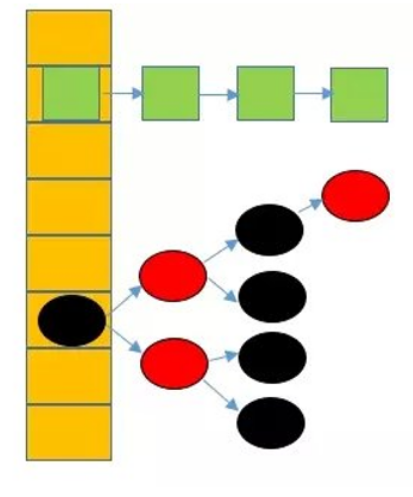
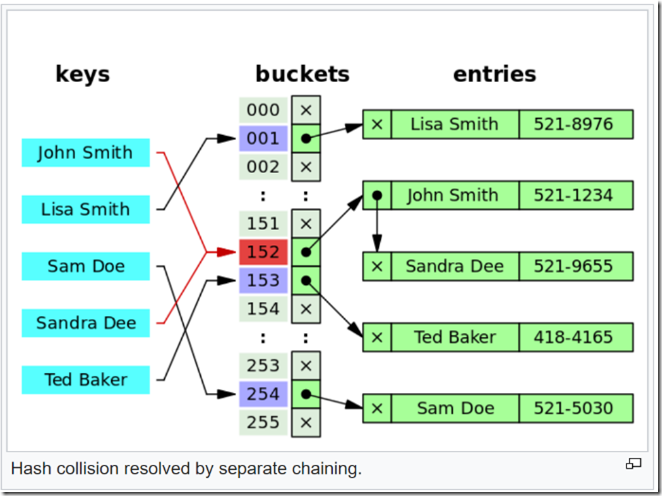
Hashmap里面的bucket出现了单链表的形式,散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。java.util.HashMap采用的链表法的方式,链表是单向链表。形成单链表的核心代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {Entry e = table[bucketIndex];table[bucketIndex] = new Entry(hash, key, value, e);if (size++ >= threshold)resize(2 * table.length);}
上面方法的代码很简单,但其中包含了一个设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。 HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
通过上面可知如果多个hashCode()的值落到同一个桶内的时候,这些值是存储到一个链表中的。最坏的情况下,所有的key都映射到同一个桶中,这样hashmap就退化成了一个链表——查找时间从O(1)到O(n)。也就是说我们是通过链表的方式来解决这个Hash碰撞问题的。
Hash碰撞性能分析
Java 7:随着HashMap的大小的增长,get()方法的开销也越来越大。由于所有的记录都在同一个桶里的超长链表内,平均查询一条记录就需要遍历一半的列表。不过Java 8的表现要好许多!它是一个log的曲线,因此它的性能要好上好几个数量级。尽管有严重的哈希碰撞,已是最坏的情况了,但这个同样的基准测试在JDK8中的时间复杂度是O(logn)。单独来看JDK 8的曲线的话会更清楚,这是一个对数线性分布:
Java8碰撞优化提升
为什么会有这么大的性能提升,尽管这里用的是大O符号(大O描述的是渐近上界)?其实这个优化在JEP-180中已经提到了。如果某个桶中的记录过大的话(当前是TREEIFY_THRESHOLD = 8),HashMap会动态的使用一个专门的treemap实现来替换掉它。这样做的结果会更好,是O(logn),而不是糟糕的O(n)。它是如何工作的?前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。但是超过这个阈值后HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。这个性能提升有什么用处?比方说恶意的程序,如果它知道我们用的是哈希算法,它可能会发送大量的请求,导致产生严重的哈希碰撞。然后不停的访问这些key就能显著的影响服务器的性能,这样就形成了一次拒绝服务攻击(DoS)。JDK 8中从O(n)到O(logn)的飞跃,可以有效地防止类似的攻击,同时也让HashMap性能的可预测性稍微增强了一些。
本文由 风越清 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: 三月 23,2020