DBSCAN聚类算法(商场数据分析)
- 引入库
- 邻域半径,最少点数目参数
- 数据
- 最佳参数分析
- 选择最佳参数,查看结果
引入库
from sklearn.cluster import DBSCAN
邻域半径,最少点数目参数
from itertools import producteps_values = np.arange(8,12.75,0.25) # eps values to be investigated
min_samples = np.arange(3,10) # min_samples values to be investigatedDBSCAN_params = list(product(eps_values, min_samples))

数据
X_numerics = mall_data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']] # subset with numeric variables only
最佳参数分析
from sklearn.metrics import silhouette_scoreno_of_clusters = []
sil_score = []for p in DBSCAN_params:DBS_clustering = DBSCAN(eps=p[0], min_samples=p[1]).fit(X_numerics)no_of_clusters.append(len(np.unique(DBS_clustering.labels_)))sil_score.append(silhouette_score(X_numerics, DBS_clustering.labels_))#print(DBS_clustering.labels_)
tmp = pd.DataFrame.from_records(DBSCAN_params, columns =['Eps', 'Min_samples'])
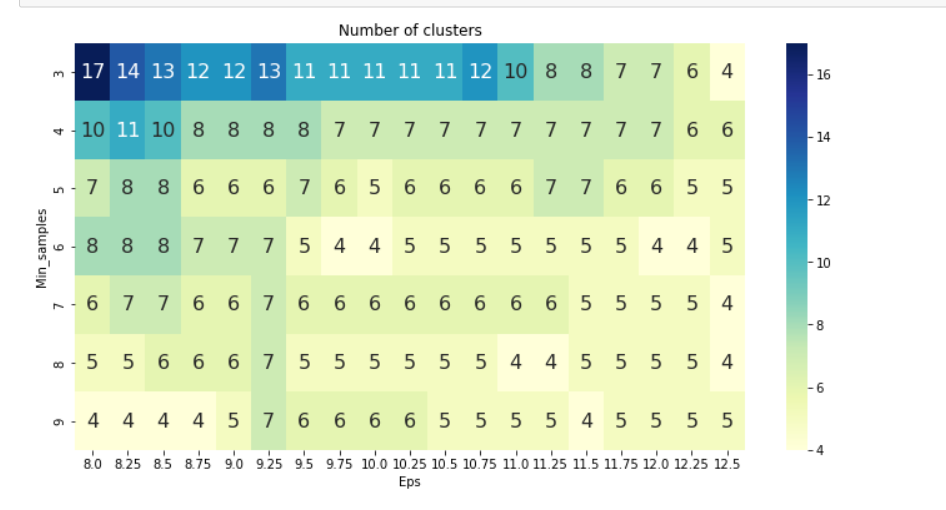
tmp['No_of_clusters'] = no_of_clusterspivot_1 = pd.pivot_table(tmp, values='No_of_clusters', index='Min_samples', columns='Eps')fig, ax = plt.subplots(figsize=(12,6))
sns.heatmap(pivot_1, annot=True,annot_kws={"size": 16}, cmap="YlGnBu", ax=ax)
ax.set_title('Number of clusters')
plt.show()
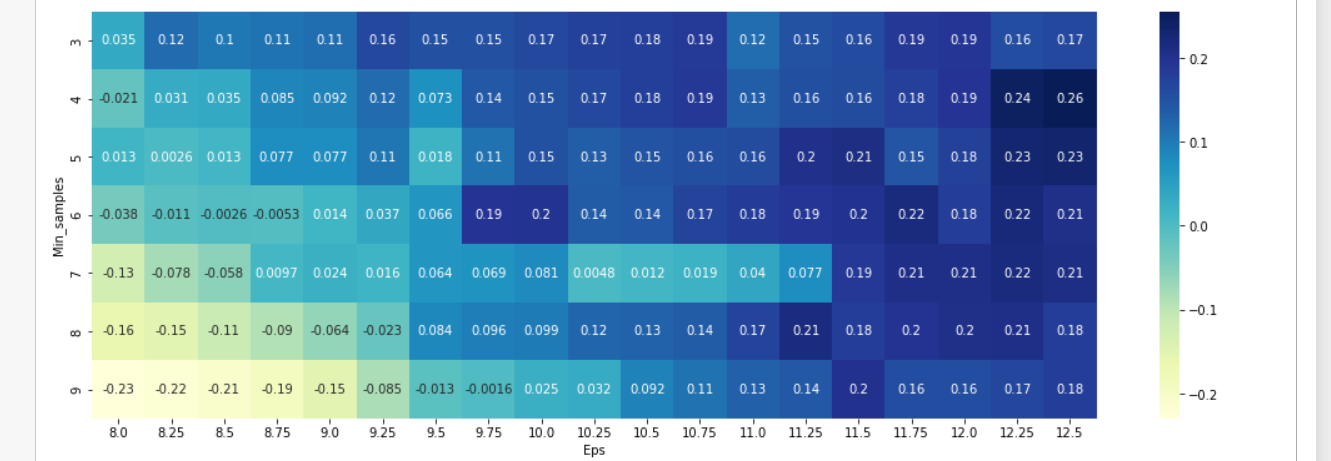
tmp = pd.DataFrame.from_records(DBSCAN_params, columns =['Eps', 'Min_samples'])
tmp['Sil_score'] = sil_scorepivot_1 = pd.pivot_table(tmp, values='Sil_score', index='Min_samples', columns='Eps')fig, ax = plt.subplots(figsize=(18,6))
sns.heatmap(pivot_1, annot=True, annot_kws={"size": 10}, cmap="YlGnBu", ax=ax)
plt.show()
选择最佳参数,查看结果
DBS_clustering = DBSCAN(eps=12.5, min_samples=4).fit(X_numerics)DBSCAN_clustered = X_numerics.copy()
DBSCAN_clustered.loc[:,'Cluster'] = DBS_clustering.labels_ # append labels to points
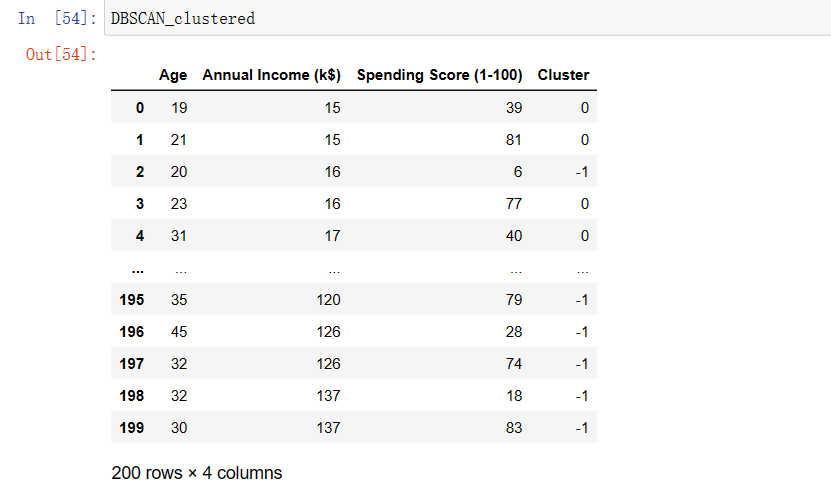
DBSCAN_clust_sizes = DBSCAN_clustered.groupby('Cluster').size().to_frame() # 统计某一类的种类个数,返回dataframe
DBSCAN_clust_sizes.columns = ["DBSCAN_size"]
DBSCAN_clust_sizes

画图分析
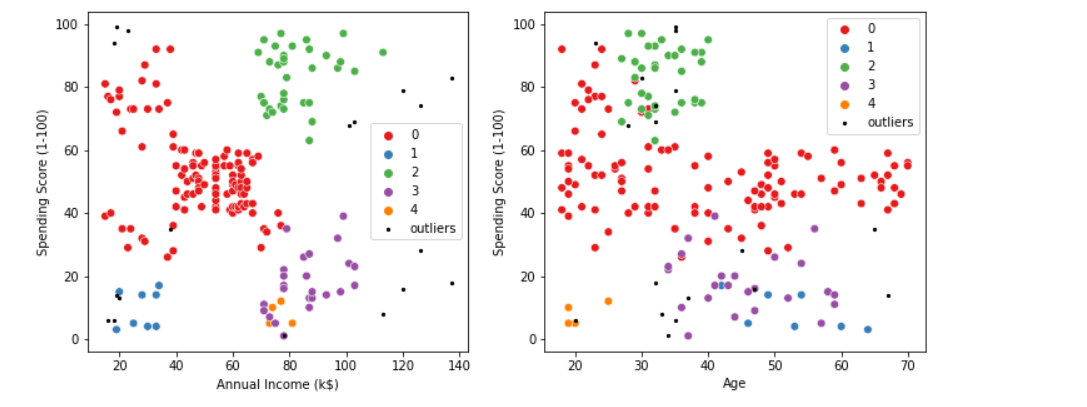
outliers = DBSCAN_clustered[DBSCAN_clustered['Cluster']==-1]fig2, (axes) = plt.subplots(1,2,figsize=(12,5))sns.scatterplot('Annual Income (k$)', 'Spending Score (1-100)',data=DBSCAN_clustered[DBSCAN_clustered['Cluster']!=-1],hue='Cluster', ax=axes[0], palette='Set1', legend='full', s=45)sns.scatterplot('Age', 'Spending Score (1-100)',data=DBSCAN_clustered[DBSCAN_clustered['Cluster']!=-1],hue='Cluster', palette='Set1', ax=axes[1], legend='full', s=45)axes[0].scatter(outliers['Annual Income (k$)'], outliers['Spending Score (1-100)'], s=5, label='outliers', c="k")
axes[1].scatter(outliers['Age'], outliers['Spending Score (1-100)'], s=5, label='outliers', c="k")
axes[0].legend()
axes[1].legend()plt.setp(axes[0].get_legend().get_texts(), fontsize='10')
plt.setp(axes[1].get_legend().get_texts(), fontsize='10')plt.show()