聚类及DBSCAN 聚类算法
一、聚类
1.概念
聚类就是按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。
2.聚类与分类的区别
聚类时,我们并不关心某一类是什么,目标只是把相似的东西聚到一起。因此聚类通常不需要使用训练数据进行学习,可以看作无监督学习。
分类时,一个分类器需要训练集进行“学习”,从而具备对未知数据进行分类的能力,属于监督学习。
3.聚类分类
(1)基于划分
原理解析:假设有一堆散点需要聚类,首先确定该堆散点需要聚成几类,然后挑选几个点作为初始中心点,再然后给数据点做迭代重置(iterative relocation),直到最后达到“类内的点都足够近,类间的点都足够远”的目标效果。
主要算法:k-means算法及其变体。
优点:很适合发现中小规模的数据库中小规模的数据库中的球状簇;对于大型数据集简单高效、时间复杂度、空间复杂度低。
缺点:计算量大;数据集大时结果容易局部最优;需要预先设定K值,对最先的K个点选取很敏感;对噪声和离群值非常敏感;只用于numerical类型数据;不能解决非凸(non-convex)数据。
(2)基于层次
层次聚类主要有两种类型:合并的层次聚类和分裂的层次聚类。
合并的层次聚类是一种自底向上的层次聚类算法,从最底层开始,每一次通过合并最相似的聚类来形成上一层次中的聚类,整个当全部数据点都合并到一个聚类的时候停止或者达到某个终止条件而结束,大部分层次聚类都是采用这种方法处理。
分裂的层次聚类是采用自顶向下的方法,从一个包含全部数据点的聚类开始,然后把根节点分裂为一些子聚类,每个子聚类再递归地继续往下分裂,直到出现只包含一个数据点的单节点聚类出现,即每个聚类中仅包含一个数据点。
主要算法:BIRCH算法、CURE算法、CHAMELEON算法。
优点:可解释性好;可以解决K-means不能解决的非球形族。
缺点:时间复杂度高。
(3)基于密度
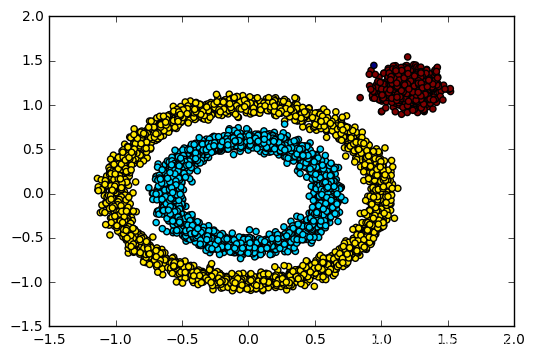
原理解析:k-means解决不了不规则形状的聚类。于是就有了Density-based methods来系统解决这个问题。该方法同时也对噪声数据的处理比较好。其原理简单说画圈儿,其中要定义两个参数,一个是圈儿的最大半径,一个是一个圈儿里最少应容纳几个点。只要邻近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类,最后在一个圈里的,就是一个类。
主要算法:DBSCAN算法、OPTICS算法、DENCLUE算法。
优点:对噪声不敏感;能发现任意形状的聚类。
缺点:聚类的结果与参数有很大的关系。
(4)基于网格
原理解析:将数据空间划分为网格单元,将数据对象集映射到网格单元中,并计算每个单元的密度。根据预设的阈值判断每个网格单元是否为高密度单元,由邻近的稠密单元组形成”类“。
主要算法:STING算法、CLIQUE算法、WAVE-CLUSTER算法。
优点:速度很快,因为其速度与数据对象的个数无关,而只依赖于数据空间中每个维上单元的个数。
缺点:参数敏感、无法处理不规则分布的数据、维数灾难等;这种算法效率的提高是以聚类结果的精确性为代价的。经常与基于密度的算法结合使用。
(5)基于模型
原理解析:为每簇假定了一个模型,寻找数据对给定模型的最佳拟合,这一类方法主要是指基于概率模型的方法和基于神经网络模型的方法,尤其以基于概率模型的方法居多。这里的概率模型主要指概率生成模型(generative Model),同一”类“的数据属于同一种概率分布,即假设数据是根据潜在的概率分布生成的。
主要算法:高斯混合模型(GMM,Gaussian Mixture Models)、SOM(Self Organized Maps)。
优点:对”类“的划分不那么”坚硬“,而是以概率形式表现,每一类的特征也可以用参数来表达。
缺点:执行效率不高,特别是分布数量很多并且数据量很少的时候。
(6)基于模糊
主要算法:模糊C均值(FCM)。
二、DBSCAN 聚类算法
1.DBSCAN密度定义
DBSCAN基于一组邻域来描述样本集的紧密程度,参数(ϵ, MinPts)用来描述邻域的样本分布紧密程度。其中,ϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为ϵ的邻域中样本个数的阈值。
假设样本集:D=(x1,x2,…,xm),则DBSCAN具体的密度描述定义如下:
1)ϵ-邻域:对于xj∈D,其ϵ-邻域包含样本集D中与xj的距离不大于ϵ的子样本集,即Nϵ(xj)={xi∈D|distance(xi,xj)≤ϵ}, 这个子样本集的个数记为|Nϵ(xj)|。
2) 核心对象:对于任一样本xj∈D,如果其ϵ-邻域对应的Nϵ(xj)至少包含MinPts个样本,即如果|Nϵ(xj)|≥MinPts,则xj是核心对象。
3)密度直达:如果xi位于xj的ϵ-邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。
4)密度可达:对于xi和xj,如果存在样本样本序列p1,p2,…,pT,满足p1=xi,pT=xj, 且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,…,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
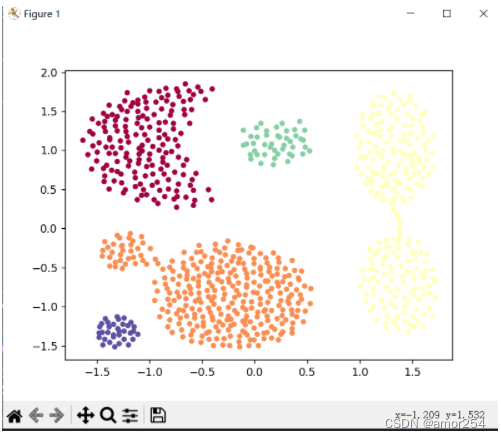
从下图可以很容易看出理解上述定义,图中MinPts=5,红色的点都是核心对象,因为其ϵ-邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列的ϵ-邻域内所有的样本相互都是密度相连的。

2.DBSCAN密度聚类思想
DBSCAN的聚类定义很简单:由密度可达关系导出的最大密度相连的样本集合,即为最终聚类的一个类别,或者说一个簇。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的ϵ-邻域里;如果有多个核心对象,则簇里的任意一个核心对象的ϵ-邻域中一定有一个其他的核心对象,否则这两个核心对象无法密度可达。这些核心对象的ϵ-邻域里所有的样本的集合组成的一个DBSCAN聚类簇。
那么怎么才能找到这样的簇样本集合呢?DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
基本上这就是DBSCAN算法的主要内容了,是不是很简单?但是我们还是有三个问题没有考虑。
第一个是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
第二个是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。这和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。如果大家对于最近邻的思想,距离度量,KD树和球树不熟悉,建议参考之前写的另一篇文章K近邻法(KNN)原理小结。
第三个问题比较特殊,某些样本可能到两个核心对象的距离都小于ϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说DBSCAN的算法不是完全稳定的算法。
3.DBSCAN聚类算法
下面对DBSCAN聚类算法的流程做一个总结。
输入:样本集D=(x1,x2,...,xm),邻域参数(ϵ,MinPts), 样本距离度量方式
1)初始化核心对象集合Ω=∅, 初始化聚类簇数k=0,初始化未访问样本集合Γ = D, 簇划分C = ∅。
2) 对于j=1,2,...m, 按下面的步骤找出所有的核心对象:a) 通过距离度量方式,找到样本xj的ϵ-邻域子样本集Nϵ(xj);b) 如果子样本集样本个数满足|Nϵ(xj)|≥MinPts, 将样本xj加入核心对象样本集合:Ω=Ω∪{xj}。
3)如果核心对象集合Ω=∅,则算法结束,否则转入步骤4。
4)在核心对象集合Ω中,随机选择一个核心对象o,初始化当前簇核心对象队列Ωcur={o}, 初始化类别序号k=k+1,初始化当前簇样本集合Ck={o}, 更新未访问样本集合Γ=Γ−{o}。
5)如果当前簇核心对象队列Ωcur=∅,则当前聚类簇Ck生成完毕, 更新簇划分C={C1,C2,...,Ck}, 更新核心对象集合Ω=Ω−Ck, 转入步骤3。否则更新核心对象集合Ω=Ω−Ck。
6)在当前簇核心对象队列Ωcur中取出一个核心对象o′,通过邻域距离阈值ϵ找出所有的ϵ-邻域子样本集Nϵ(o′),令Δ=Nϵ(o′)∩Γ, 更新当前簇样本集合Ck=Ck∪Δ, 更新未访问样本集合Γ=Γ−Δ, 更新Ωcur=Ωcur∪(Δ∩Ω)−o′,转入步骤5。
输出结果为: 簇划分C={C1,C2,...,Ck}
4.DBSCAN总结
与传统的K-Means算法相比,DBSCAN最大的不同就是不需要输入类别数k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
下面对DBSCAN算法的优缺点做一个总结。
DBSCAN的主要优点有:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
参考文献:
聚类及聚类算法的分类:https://blog.csdn.net/count_on_me/article/details/82193745
聚类方法:DBSCAN算法研究(1)–DBSCAN原理、流程、参数设置、优缺点以及算法:https://blog.csdn.net/zhouxianen1987/article/details/68945844?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.pc_relevant_paycolumn_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.pc_relevant_paycolumn_v2&utm_relevant_index=5
DBSCAN 聚类算法:https://blog.csdn.net/chengyq116/article/details/87250193
DBSCAN 密度聚类算法:https://www.cnblogs.com/pinard/p/6208966.html






![c++ char[]与int之间的类型转换](https://img-blog.csdnimg.cn/0e7a8b1a276e484f8c49405e478d3f70.png#pic_center)