1.DBSCAN算法
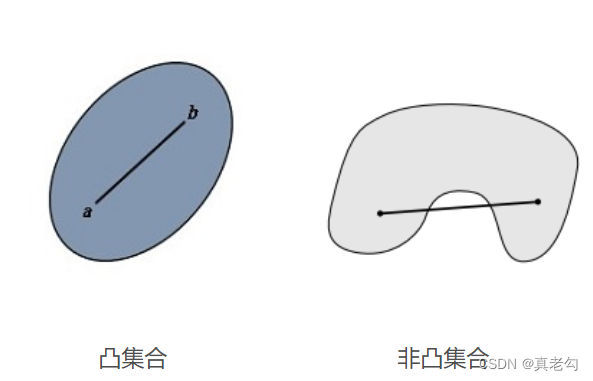
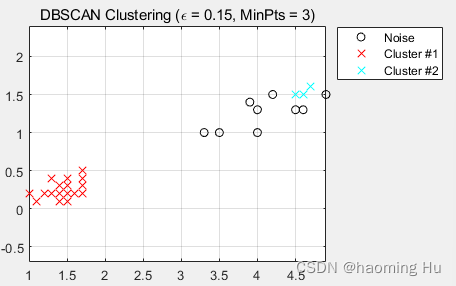
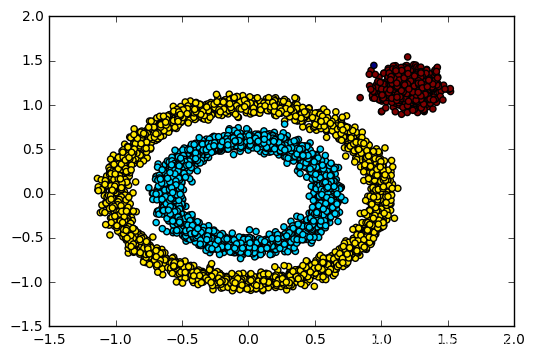
K-means聚类算法基于距离的聚类算法,其中的局限性在于,在凸集中进行聚类,但是在非凸集聚类效果不佳。如图:
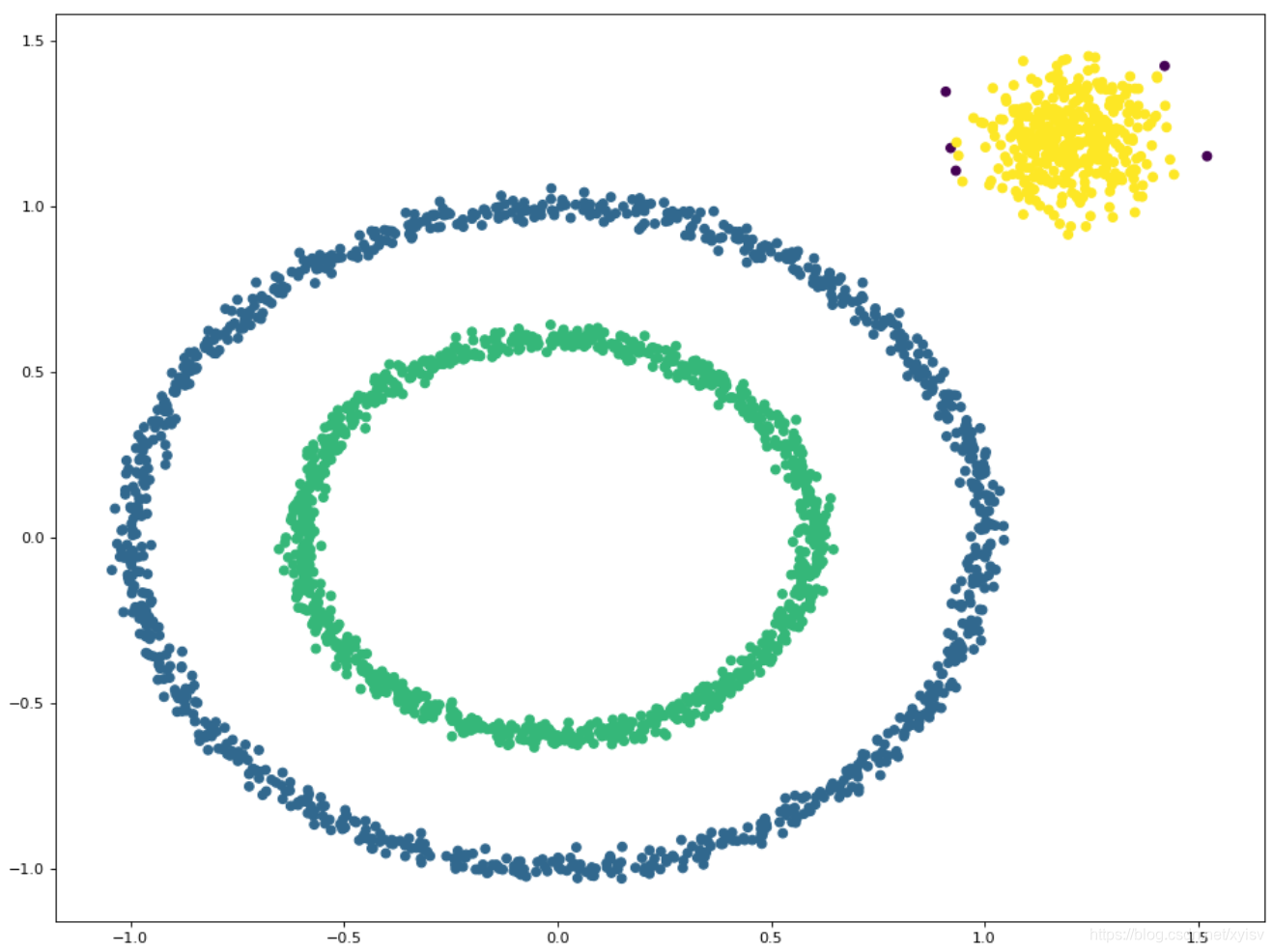
对于下图,进行聚类,传统的聚类算法效果不佳,使用DBSCAN则效果更佳。

DBSCAN是基于密度的聚类算法,将样本点分为三类:
核心点:样本点处的密度大于密度下限
边界点:样本点处的密度小于密度下限,但样本点在某一核心点的邻域内
噪声点:既不是核心点也不是样本点
原理:DBSCAN聚类算法本质上就是通过寻找一系列的紧紧挨着的高密度核心点(core points),以及这批核心点外层的边界点,将其聚类成簇。
DBSCAN的核心思想是从某个核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意两点密度相连。
算法口语解释
下面这些点是分布在样本空间的众多样本,现在我们的目标是把这些在样本空间中距离相近的聚成一类。我们发现A点附近的点密度较大,假设从A点开始红色的圆圈根据一定的规则(即以点A为圆心,按照一个半径长度画一个圆)在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。其它没有被收纳的根据一样的规则成簇。(形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。

参数选择
- 半径:半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点,比如:

以上虽然是一个可取的方式,可是有时候比较麻烦 ,大部分仍是都试一试进行观察,用k距离须要作大量实验来观察,很难一次性把这些值都选准。
MinPts:这个参数就是圈住的点的个数,也至关因而一个密度,通常这个值都是偏小一些,而后进行屡次尝试
伪代码
1.初始化当前簇号为0,初始化样本集内所有样本点的标签为noise ,初始化种子集合seeds为空集合。
2.从样本集中依序取一个标签为noise的点xi,如果没有这样的点,算法结束。
3.检查xi是否是核心点,如果不是转到第2步。
4.将xi邻域内的所有标签为noise的点标记为当前簇号,并加入集合seeds(不包括xi).
5.如果集合seeds为空,将当前簇号加1,并转到第2步,否则从集合seeds中取一个点p
6.如果点p为非核心点,则从集合seeds中删除,并转到第5步。
7.将点p的邻域内的所有标签为noise的点标记当前簇号,并加入到seeds集合,转到第5步。
密度:空间中任意一点的密度是以该点为圆心,以EPS为半径的圆区域内包含的点数目
边界点:空间中某一点的密度,如果小于某一点给定的阈值minpts,则称为边界点
噪声点:不属于核心点,也不属于边界点的点,也就是密度为1的点
算法优点
- 这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点
- 可发现任意形状的聚类,且对噪声数据不敏感。
- 不需要指定类的数目cluster
- 算法中只有两个参数,扫描半径 (eps)和最小包含点数(min_samples)
算法缺点:
- 1、计算复杂度,不进行任何优化时,算法的时间复杂度是O(N^{2}),通常可利用R-tree,k-d tree, ball
tree索引来加速计算,将算法的时间复杂度降为O(Nlog(N))。 - 2、受eps(两个样本之间的最大距离,即扫描半径)影响较大。在类中的数据分布密度不均匀时,eps较小时,密度小的cluster会被划分成多个性质相似的cluster;eps较大时,会使得距离较近且密度较大的cluster被合并成一个cluster。在高维数据时,因为维数灾难问题,eps的选取比较困难。
- 3、依赖距离公式的选取,由于维度灾害,距离的度量标准不重要
- 4、不适合数据集集中密度差异很大的,因为eps和metric选取很困难。
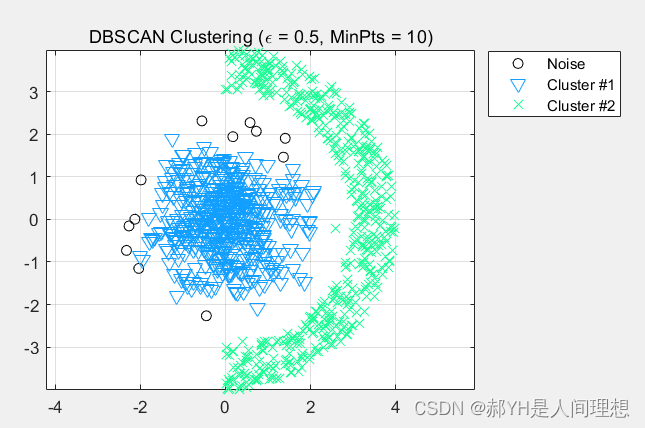
国外有一个特别有意思的网站:
Visualizing DBSCAN Clustering












![c++ char[]与int之间的类型转换](https://img-blog.csdnimg.cn/0e7a8b1a276e484f8c49405e478d3f70.png#pic_center)