JavaScript实现浏览器特定区域截屏功能
- 需求介绍
- 尝试一:使用Jtopo.js自带的保存图片方法(不能对资源进行下载)
- 尝试二:对saveImageInfo进行改写(功能能用,但是会因为跨域问题污染canvas):
- 尝试三:对浏览器进行区域截屏并下载(可用)
需求介绍
最近使用Jtopo进行一个简单版拓扑图编辑器的开发。其中有一个需求就是将编辑器canvas部分进行截图并进行下载。
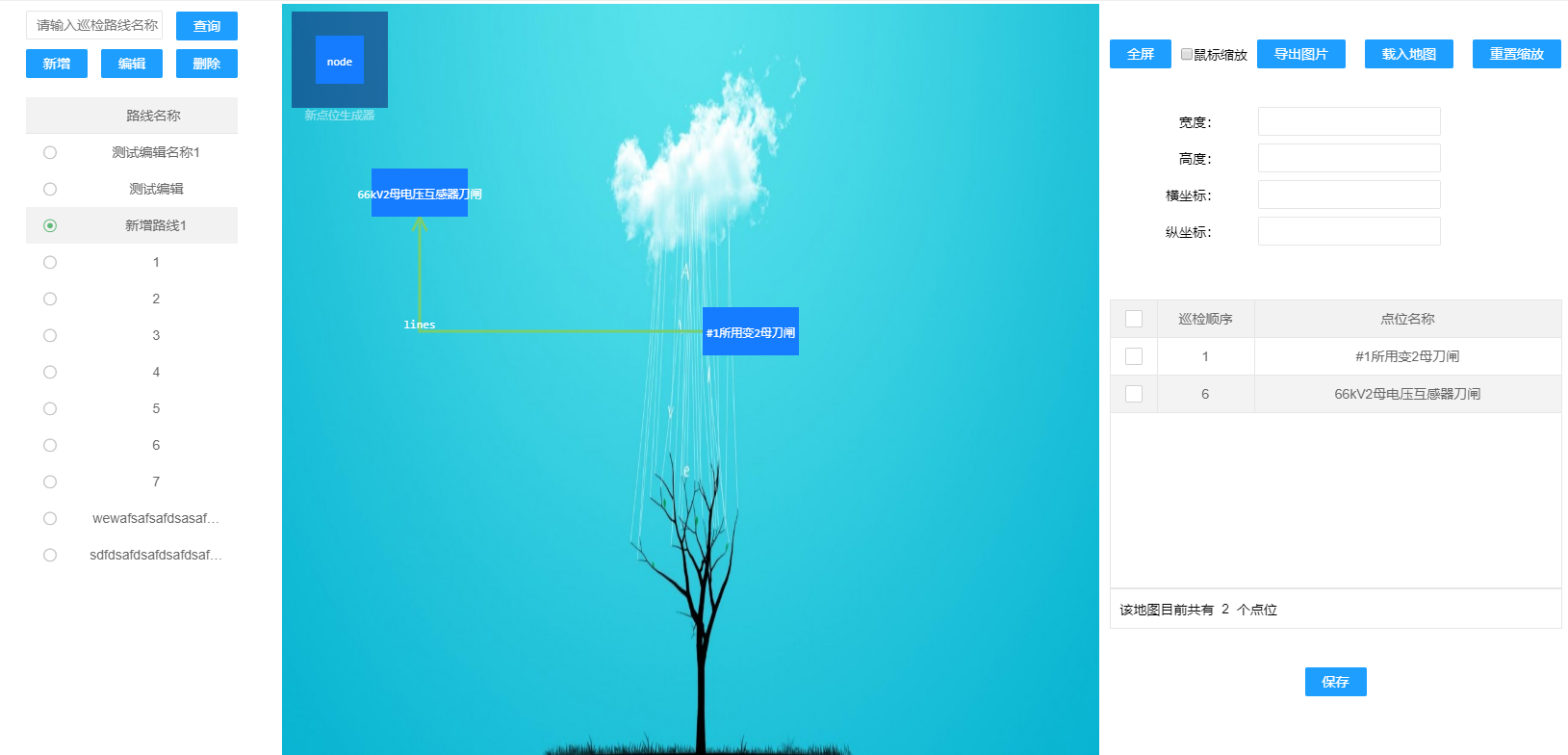
尝试一:使用Jtopo.js自带的保存图片方法(不能对资源进行下载)
使用Jtopo的stage.saveImageInfo()原生方法,发现该方法只是将canvas部分制作成base64并且在跳转到新的页面进行展示。
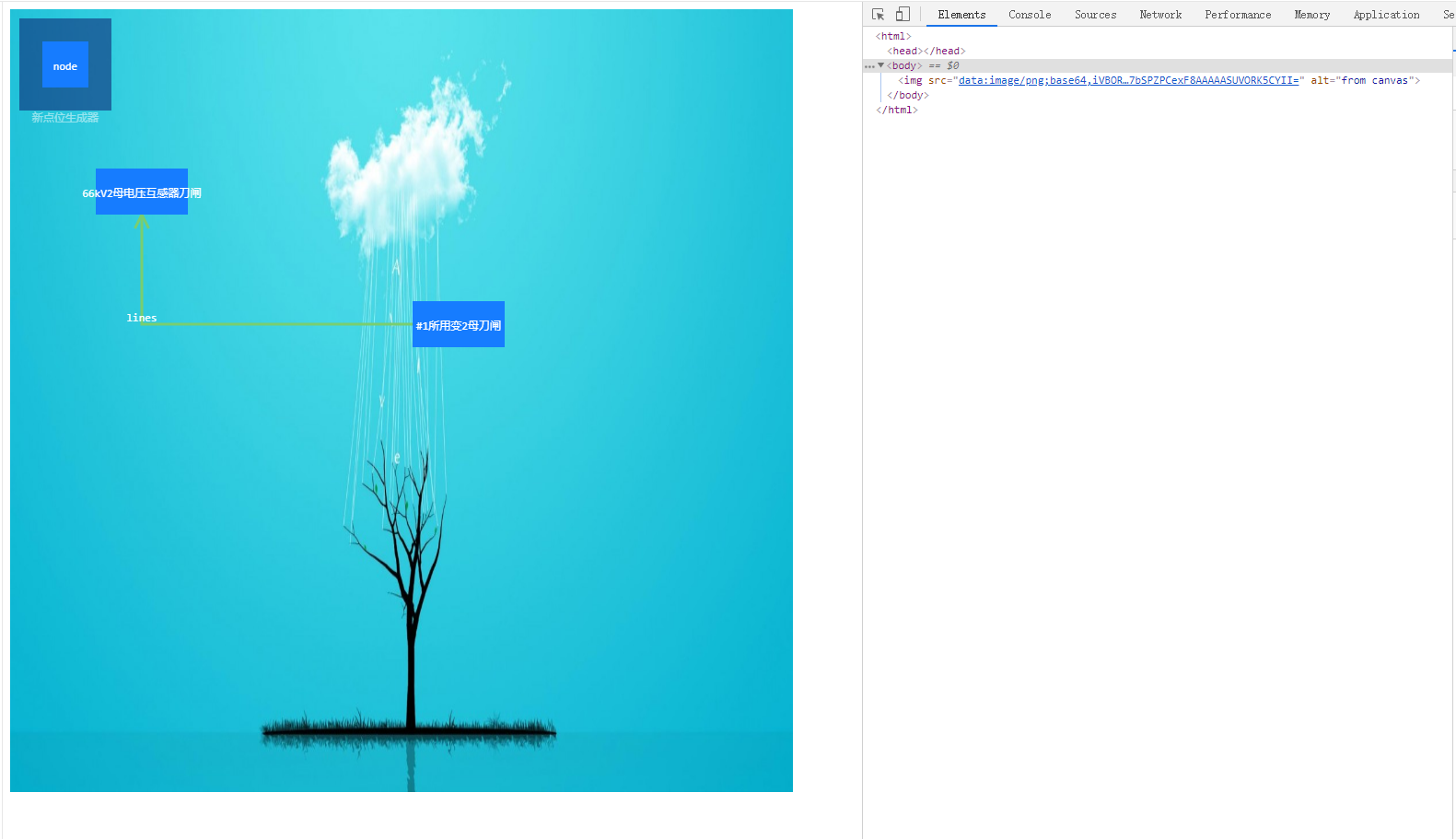

在浏览器控制台查看stage.saveImageInfo方法,可以看到该方法总共只有3条语句:
ƒ (a,b){var c=this.eagleEye.getImage(a,b), // 通过Jtopo.js自带的方法获取canvas的截图base64资源d=window.open("about:blank"); // 打开新的浏览器标签页return d.document.write("<img src='"+c+"' alt='from canvas'/>"),this // 将截取的base64资源作为图片资源放置到新的浏览器标签页img标签中
}
尝试二:对saveImageInfo进行改写(功能能用,但是会因为跨域问题污染canvas):
于是,就需要对原有的方法进行扩展或者重写(功能虽然能用,但是会有bug):
// 重写JTopo下载源码,提供下载图片功能function saveImage() {let imgData = stage.eagleEye.getImage();imgData = imgData.replace("image/png", "image/octet-stream")var save_link = document.createElementNS('http://www.w3.org/1999/xhtml', 'a');save_link.href = imgData;// 保存的文件名save_link.download = (new Date()).getTime() + '.png';scene.background = save_link.downloadvar event = document.createEvent('MouseEvents');event.initMouseEvent('click', true, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null);save_link.dispatchEvent(event);};
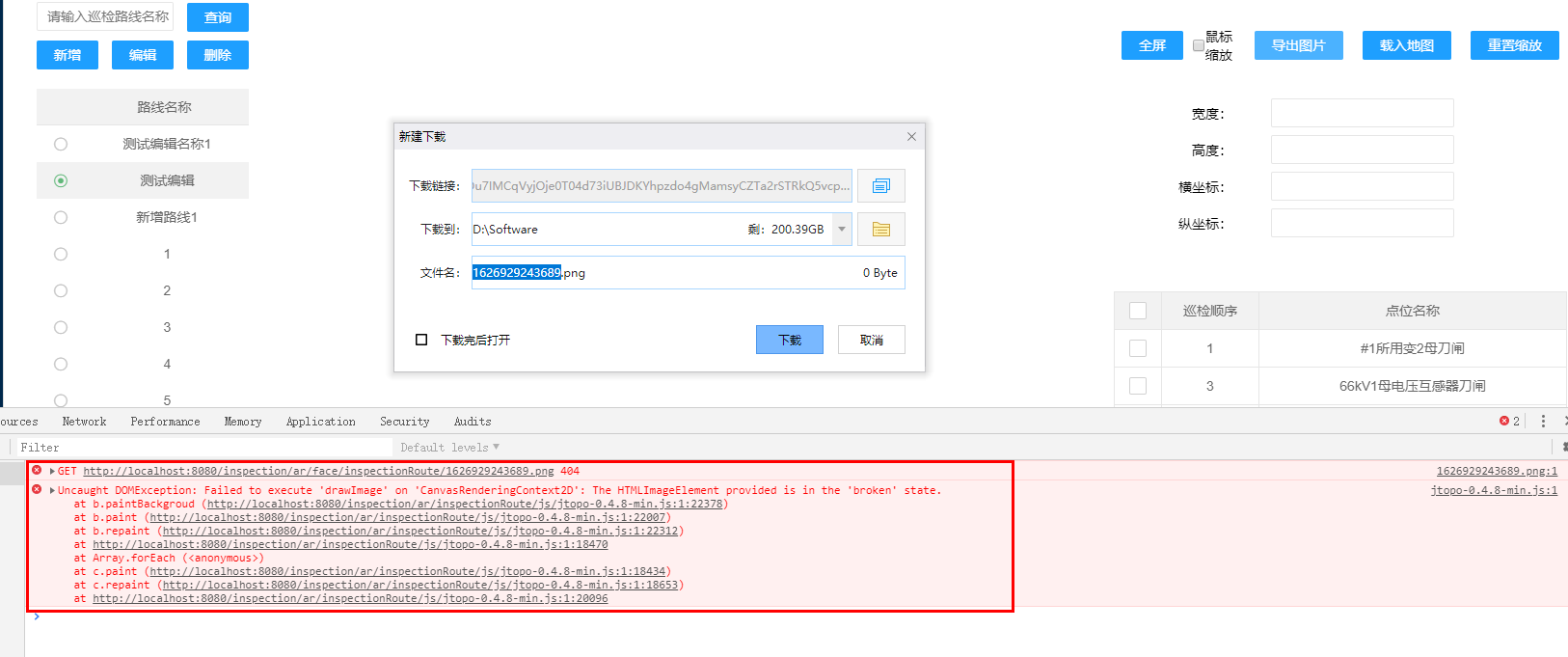
虽然改写后的方法确实能够做到将canvas的部分进行截图,但是因为跨域问题,原来绘制的canvas会被破坏。
尝试三:对浏览器进行区域截屏并下载(可用)
该尝试参考了文章https://www.cnblogs.com/xinchenhui/p/10886140.html
考虑到canvas的污染问题,于是思考不对原来的canvas进行操作,而是直接对整个浏览器进行区域截屏的方式,发现果然可用。
html部分:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>测试截取保存或打印</title><script src="https://code.jquery.com/jquery-3.1.1.min.js"></script><script type="text/javascript" src="js/html2canvas.js"></script><script type="text/javascript" src="js/jQuery.print.js"></script><script type="text/javascript" src="js/jcanvas.min.js"></script><script type="text/javascript" src="js/screenshotsPrint.js"></script><style>body, html {width: 100%;height: 100%;}.print {position: relative;z-index: 100;}h1 {color: orangered;}h2 {color: darkblue;}h2 {color: forestgreen;}#bg_canvas {position: absolute;z-index: 500;left: 0;top: 0;}</style>
</head>
<body>
<button class="print">开始截图</button>
<div><h1>测试文字测试文字测试文字测试文字测试文字测试文字测试文字测试文字</h1><h2>测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试</h2><h3>好好好</h3><br/><p>跨域图片</p><img src="http://p7.qhimg.com/t01ceede0272d4b5a8b.png" alt="来个跨区的图片">
</div>
<!-- 用于画选取框的canvas -->
<canvas id="bg_canvas" width="100%" height="100%" style="display: none;"/>
<script>$(function(){var clientWidth = document.documentElement.clientWidth || document.body.clientWidthvar clientHeight = document.documentElement.clientHeight || document.body.clientHeight// 更新canvas宽高$("#bg_canvas").attr("width", clientWidth);$("#bg_canvas").attr("height", clientHeight);$(".print").click(function(){$("#bg_canvas").show()//调用选取截屏clipScreenshots("bg_canvas");$("#bg_canvas").hide()});});
</script>
</body>
</html>
核心js部分——screenshotsPrint.js:
function clipScreenshots(){// 把body转成canvashtml2canvas(document.body, {scale: 1,// allowTaint: true,useCORS: true //跨域使用}).then(canvas => {printClip(canvas, 10, 10, 100, 100)});}/*** 打印截取区域* @param canvas 截取的canvas* @param capture_x 截取的起点x* @param capture_y 截取的起点y* @param capture_width 截取的起点宽* @param capture_height 截取的起点高*/function printClip(canvas, capture_x, capture_y, capture_width, capture_height) {// 创建一个用于截取的canvasvar clipCanvas = document.createElement('canvas')clipCanvas.width = capture_widthclipCanvas.height = capture_height// 截取clipCanvas.getContext('2d').drawImage(canvas, capture_x, capture_y, capture_width, capture_height, 0, 0, capture_width, capture_height)var clipImgBase64 = clipCanvas.toDataURL()// 生成图片var clipImg = new Image()clipImg.src = clipImgBase64downloadIamge(clipImgBase64)}/*** 下载保存图片* @param imgUrl 图片地址*/function downloadIamge(imgUrl) {// 图片保存有很多方式,这里使用了一种投机的简单方法。// 生成一个a元素var a = document.createElement('a')// 创建一个单击事件var event = new MouseEvent('click')// 生成文件名称var timestamp = new Date().getTime();var name = imgUrl.substring(22, 30) + timestamp + '.png';a.download = name// 将生成的URL设置为a.href属性a.href = imgUrl;// 触发a的单击事件 开始下载a.dispatchEvent(event);}
因为引用的js代码库过长就不直接在文章中复制,我直接把整个demo放到资源库https://download.csdn.net/download/qq_39055970/20426243中,有需要的朋友可以自行下载。






![[NLP自然语言处理]谷歌BERT模型深度解析](https://img-blog.csdn.net/20181021135853817?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM5NTIxNTU0/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)