一、BERT整体概要
Bert由两部分组成:
- 预训练(Pre-training):通过两个联合训练任务得到Bert模型
- 微调(Fine-tune):在预训练得到bert模型的基础上进行各种各样的NLP
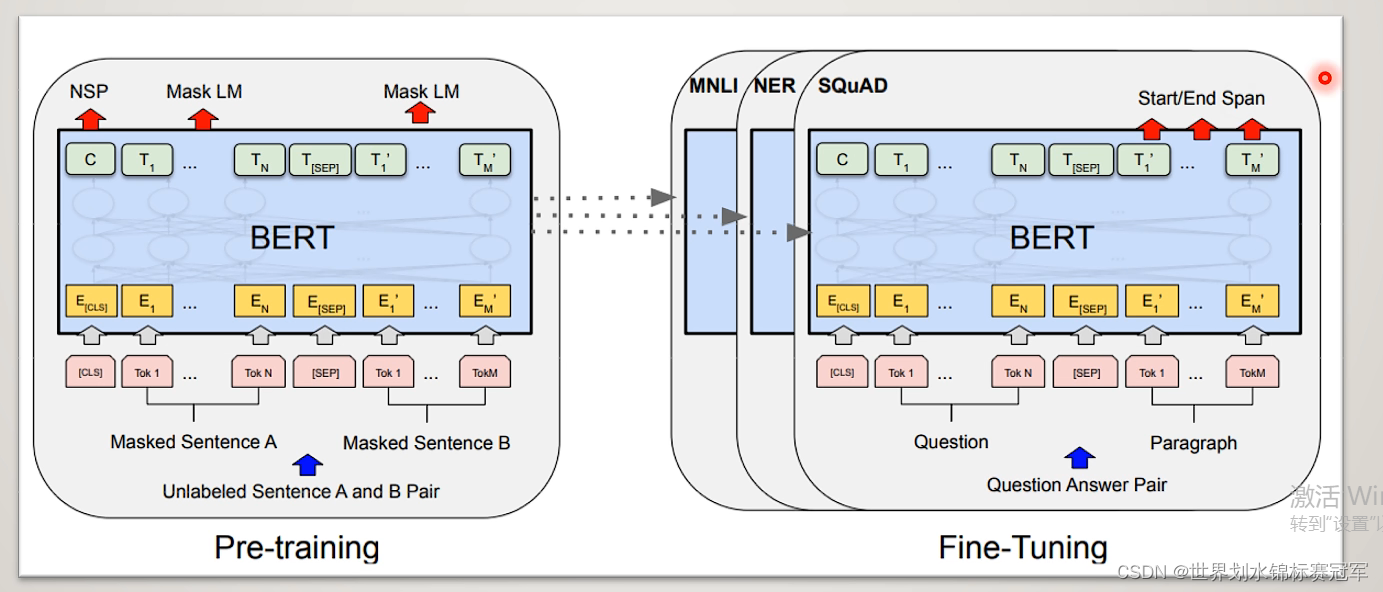
二、预训练
输入经过bert encoder层编码后,进行MLM任务和NSP任务,产生联合训练的损失函数从而迭代更新整个模型中的参数。
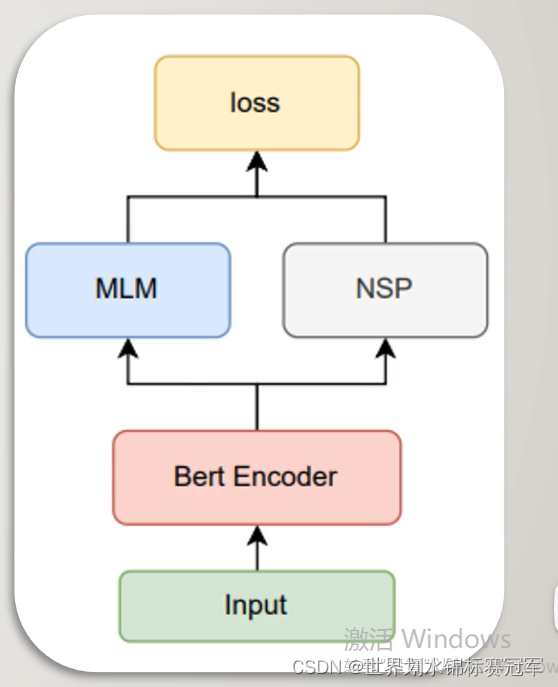
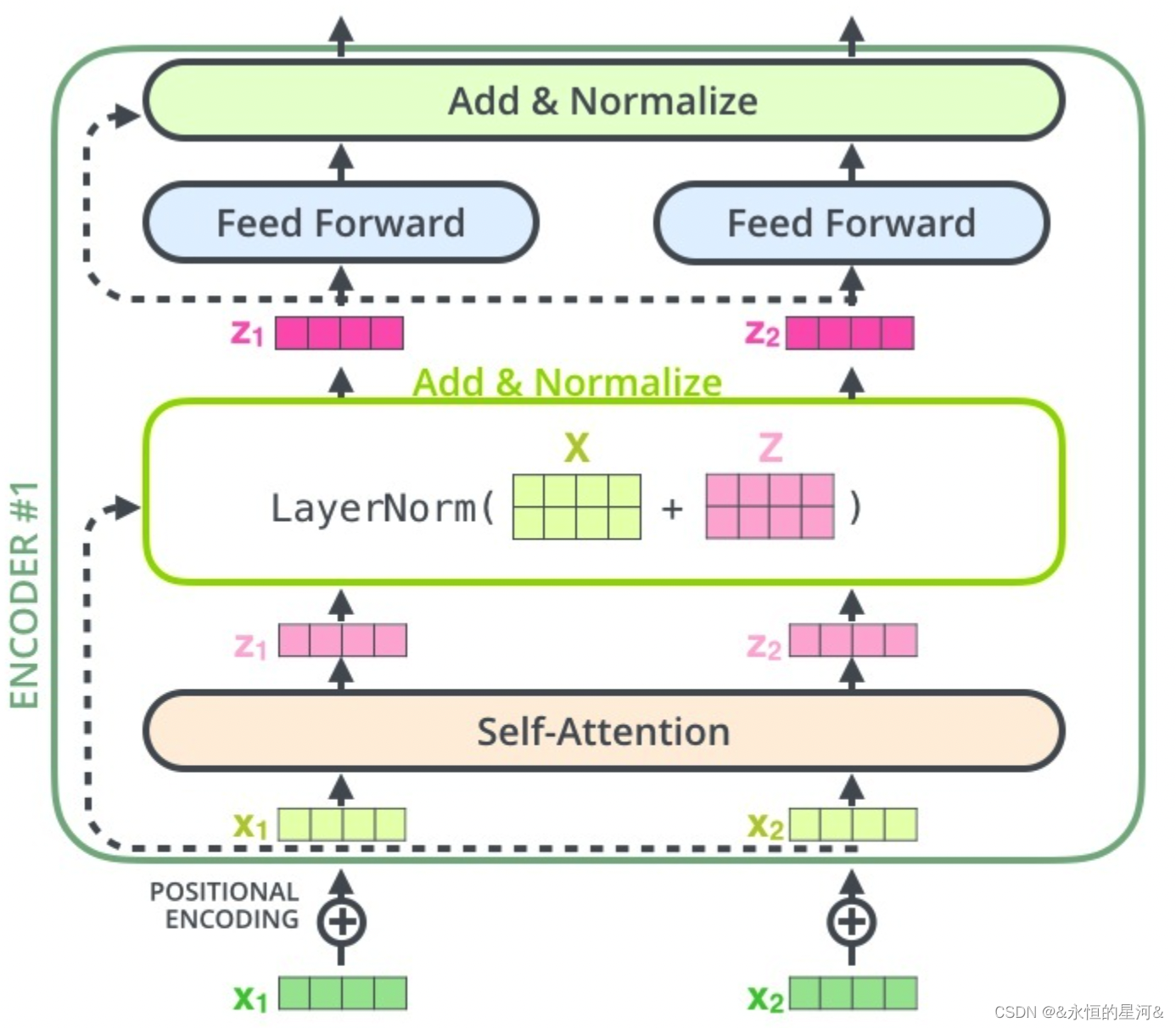
Bert Encoder:采用默认的12层transformer encoder layer对输入进行编码
MLM任务:掩蔽语言模型,遮盖句子中若干词,用周围词去预测遮盖的词
NSP任务:下个句子预测,判断句子B在文章中是否属于句子A的下一句
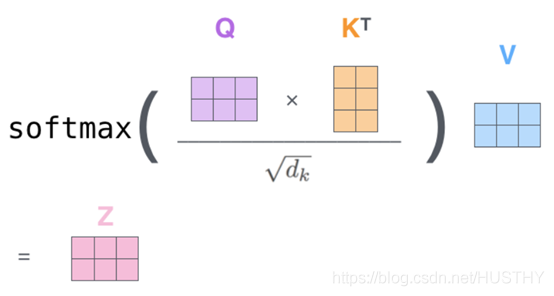
2.1 BERT Encoder
如何对输入进行编码
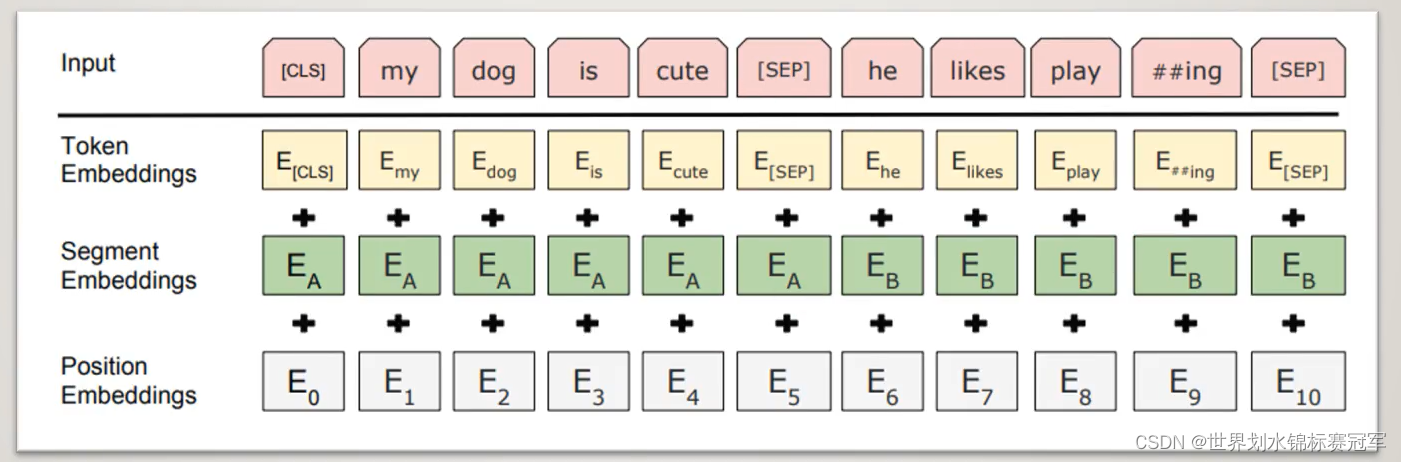
句首+ < CLS > ,句尾和两个句子之间+ < SEP >
句子级别的编码:用来区分每个句子,一个句子的编码是相同的
位置编码:其实就是数字编码123456789
经过编码器编码后输出张量的形状:[ Batch Size , Seq lens , Emb dim]
2.2 MLM任务:掩蔽语言模型
-
采样:

-
将采样后的句子送进去Bert encoder进行编码
-
输入:Bert encoder编码后的输出 + 告诉模型要预测的词元位置(张量形状[ Batch Size,词元位置数量])------一句话中可能要预测词元的数量有点多,要3个的话词元位置数量=3
-
中间:MLP结构
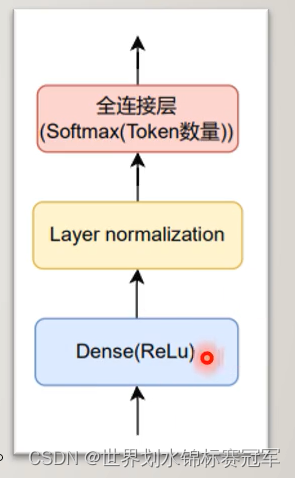
Dense:全连接层激活函数是ReLu
LN:用来规范化数据
全连接层:激活函数是Softmax(token的数量)Softmax函数是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为K KK的任意实向量,Softmax函数可以将其压缩为长度为K KK,值在[ 0 , 1 ] [0,1][0,1]范围内,并且向量中元素的总和为1的实向量。
-
输出:序列类别分布张量,形状:[ Batch Size , 词元位置数量 , 总Token数量]
2.3 NSP任务
-
采样:
采样时,50%的概率将第二句句子替换成段落中的任意一个句子 -
将采样后的句子送进去Bert encoder进行编码
-
输入:经过bert encoder编码后输出< CLS >位置的张量,形状 [ Batch Size , Emd dim]
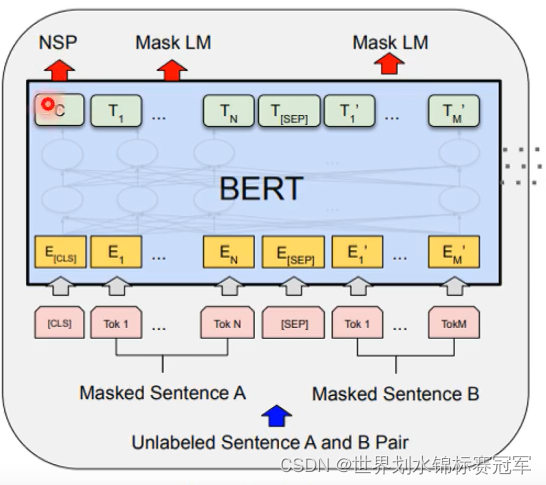
-
中间:MLP结构,输出维度为2,激活函数为Softmax
-
输出:类别分布张量。形状为[Batch Size , 2]
三、训练过程
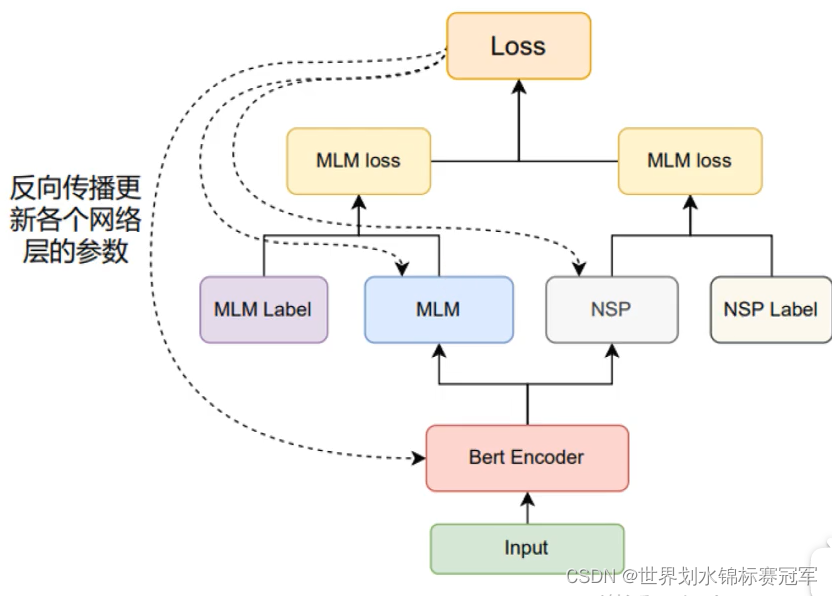
- 先通过文本数据整理出:(没有考虑padding )
①索引化的Tokens(已经随机选取了MLM与NSP任务数据)
②索引化的Segments
③MLM任务要预测的位置
④MLM任务的真实标注
⑤NSP任务的真实标注 - 将①②输入Bert Encoder得到编码后的向量以下称为⑥
- 将⑥与③输入MLM网络得到预测值与④计算交叉嫡损失函数。
- 在⑥中取出对应位置的张量输入NSP网络得到值与⑤计算交叉嫡损失函数。
- 将MLM的loss与NSP的loss相加得到总的loss,并反向传播更新所有模型参数。
考虑padding时,用< pad >进行填充。并且使用valid_lens记录实际长度
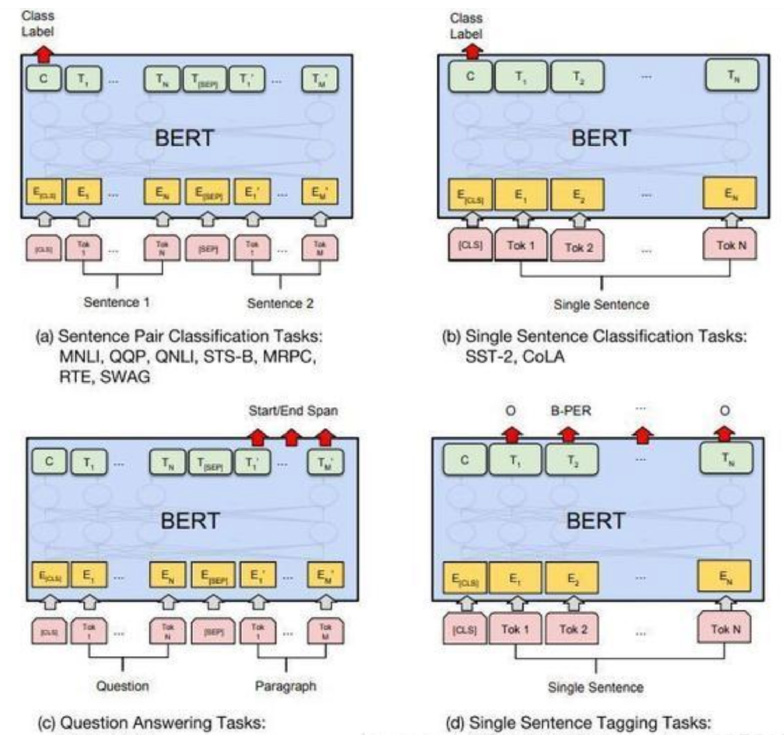
四、微调
通过预训练得到的bert encoder网络接上各种各样的下游网络进行不同的任务
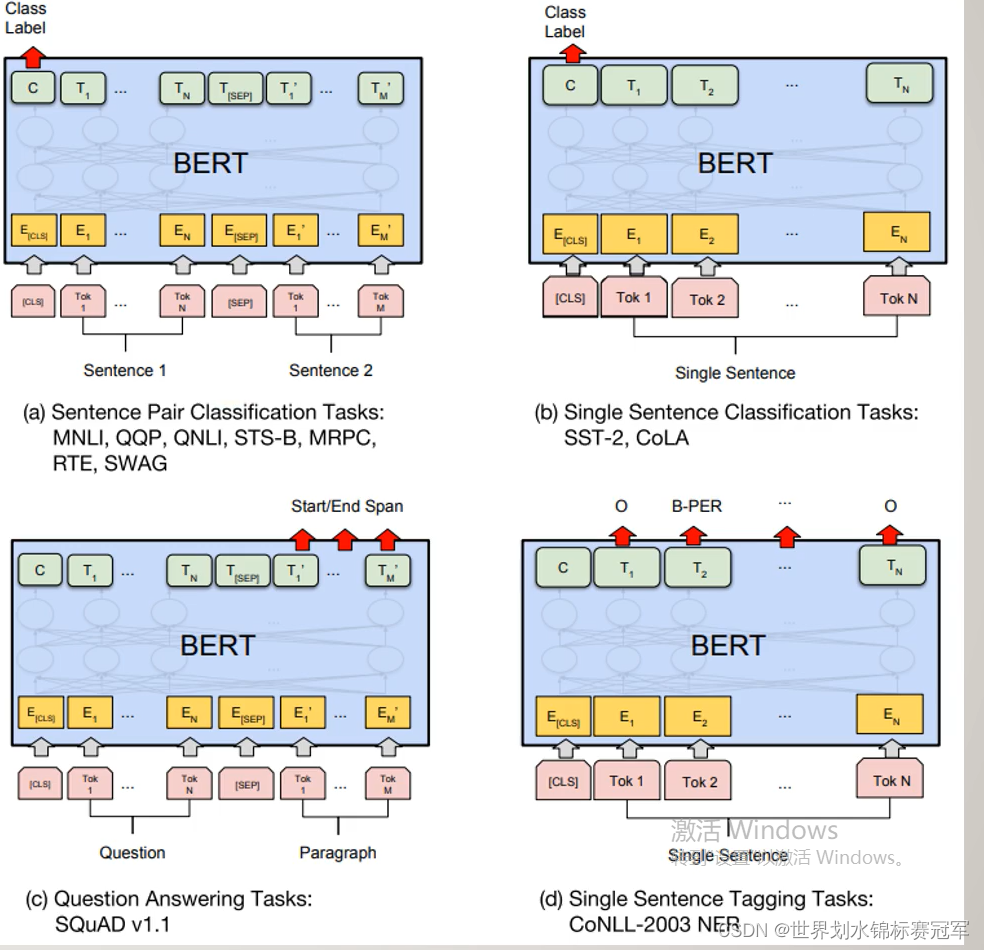
a) 句子对分类,将经过Encoder层编码后的< CLS>对应位置的向量输入进一个多分类的MLP网络中即可。
b) 单句分类,同上。
c) 根据问题得到答案,输入是一个问题与一段描述组成的句子对。将经过Encoder层编码后的每个词元对应位置的向量输入进3分类的MLP网络,而类别分别是Start(答案的首位),End(答案的末尾),Span(其他位置)。
d) 命名实体识别,将经过Encoder层编码后每个词元对应位置的向量输入进一个多分类的MLP网络中即可。
(就是12层的编码把每个词都编码后,通过编码已经提取出了一些信息,再看你怎么利用而已)
五、问题与总结
5.1bert的双向体现在什么地方
体现在mlm任务 :
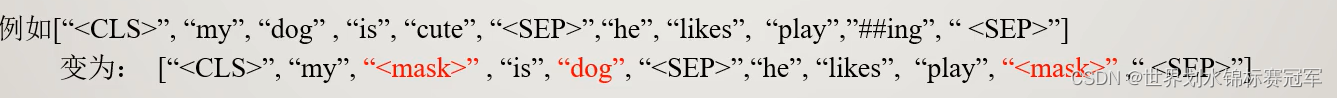
预测 “mask” 时,要看前后 “my” 与 “is” 的信息
5.2bert与transformer在位置编码上的不同
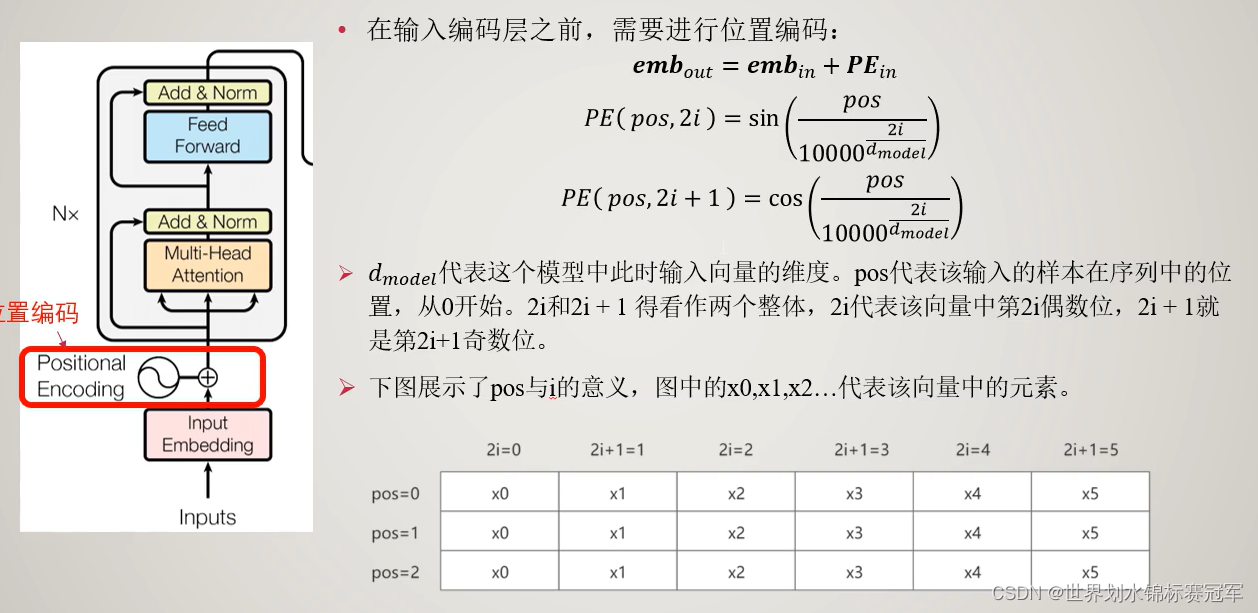
位置编码信息,在多层注意力层后就没有了-----简化:bert就直接用1234567
5.3 为什么bert中的word embedding具有一词多义的
bert最后输出的我认得 embedding