基础架构-Transformer的Encoder:
由下到上,依次三个部分为输入、注意力机制和前馈神经网络
 基础的Bert,六个encoder,六个decoder。
基础的Bert,六个encoder,六个decoder。
- 输入部分
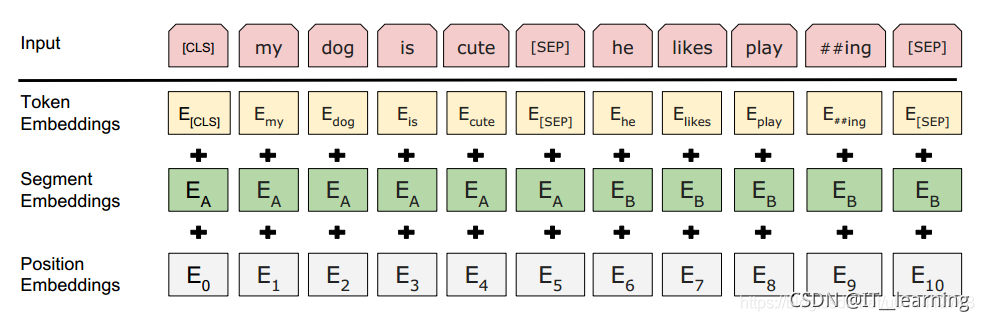
input = token embedding + segment embedding + position embedding
bert预训练的NSP(Next Sentence Prediction),其为一个二分类任务,用于处理句子之间的关系,[CLS]向量不能代表整个句子的语义信息。

Bert框架的预训练:
两个任务:
- 掩码语言模型MLM(Mask language model)
无监督文本预训练,举例两个无监督目标函数:AR和AE。
AR(auto regressive),自回归模型;只考虑单侧信息,GPT为其典型例子。
p(ABCD)=p(A)p(B|A)p(C|AB)p(D|ABC)
AE(auto encoding),自编码模型;从损坏的输入数据中预测重建原始数据。可以兼顾上下文信息,BERT就是采用的AE。
mask后:[ABmaskD]
p(ABCD|ABmaskD)=p(mask=C|ABD)
从训练信息中提取各个单词在句子中的关联概率,然后对未知做出推测。 - mask模型的缺点:P(ABCD|ABmaskmask)=P(C|AB)P(D|AB),推理中默认CD互相独立了
- 判断两个句子间的关系NSP(Next Sentence Prediction)
NSP样本建立。首先,从训练语料库中取出两个连续的段落作为正样本;其次,从不同的文档中随机创建一对段落作为负样本(不同主题抽取)。 - 缺点:主题预测和连贯性预测合并为一个单项任务
微调Bert
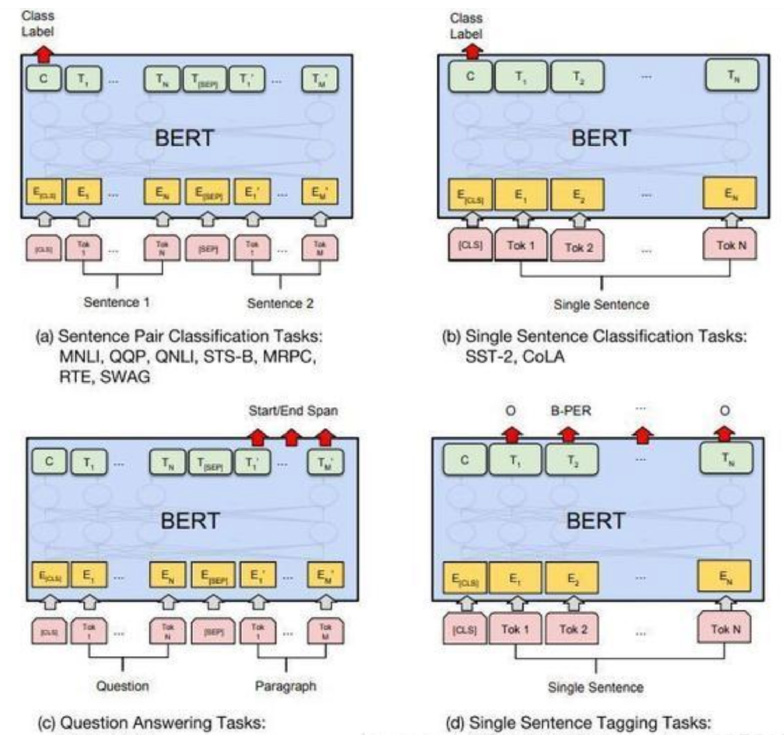
句子对的分类任务
单句分类任务:对CLS输出做fine-tune,做二分类和多分类
问答任务
序列标注任务:将所有token输出,加softmax看属于实体中的哪一个
常用做法,借用大公司预训练好的Bert实验,基于任务数据进行模型微调,常用的如谷歌中文的Bert。训练步骤例子:
1、在大量通用语料上训练一个LM(Pretrain):中文谷歌BERT
2、在相同领域上继续训练LM(Domain transfer):在大量新闻文本上继续训练这个BERT
3、在任务相关的小数据上继续训练LM:在新闻分类文本上(剔除第二步与训练目标不相干的大部分数据,剩余有效数据)
4、在任务相关数据上做具体任务(Fine-tune)
在相同领域数据中进行further pre-training
动态mask:更换mask的覆盖位置,每次epoch去训练的时候mask,而不是使用同一个。
n-gram mask:例如ERNIE和SpanBert都是类似于做了实体词的mask
参数设置:Batch size:16,32-影响不大,根据机器性能调整;Learning rate(Adam):5e-5,3e-5,2e-5,尽可能小一点避免灾难性遗忘;Number of epoch:3,4;Weighted decay修改后的adam,使用warmup,搭配线性衰减
数据增强/自蒸馏/外部知识的融入(知识图谱、实体词的信息),前提需要较高的机器性能。
名词解释part
词表:
计算机无法直接识别语言,比如英语,汉语等。因此,NLP实验中要先把自然语言转化成计算机能够识别的符号——数字(向量)。大体流程:自然语言>>编号>>向量
当我们拿到一段文本,首先要统计出词表,并把词表保存成vocab.txt,方便后续使用。一般来说在给文本编号和词向量抽取时可能会用到词表。
 Epoch:使用训练集的全部数据对模型进行一次完整的训练,这个训练被称为“一代训练”。在神经网络中仅仅将完整的数据集传递一次是不够的,我们需要将完整的数据集在同样的神经网络中传递多次。但我们使用的是有限的数据集,并且我们使用一个迭代过程,即梯度下降,来优化学习过程。随着epoch数量增加,神经网络中的权重的更新次数也在增加,曲线会从欠拟合变得过拟合。
Epoch:使用训练集的全部数据对模型进行一次完整的训练,这个训练被称为“一代训练”。在神经网络中仅仅将完整的数据集传递一次是不够的,我们需要将完整的数据集在同样的神经网络中传递多次。但我们使用的是有限的数据集,并且我们使用一个迭代过程,即梯度下降,来优化学习过程。随着epoch数量增加,神经网络中的权重的更新次数也在增加,曲线会从欠拟合变得过拟合。
 Batch:使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据”
Batch:使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据”
Iteration:使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练”
一个完整的数据集通过了神经网络一次并且返回了一次,为一个epoch;然而,当Epock的样本过大,就需要将其分成小块,也就是多个Batch;最后,训练一个Batch就i是一次Iteration。
cost function/loss function(代价函数):代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。训练模型的过程就是优化代价函数的过程,代价函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟和时添加的正则化项也是加在代价函数后面的。
梯度下降:在优化参数θ的过程中,最常用的方法是梯度下降,这里的梯度下降就是代价函数J(θ)对θ1, θ2, …, θn的偏导数。由于需要求偏导,我们可以得到另一个关于代价函数的性质:选择代价函数时,最好挑选对参数θ可微的函数(全微分存在,偏导一定存在)
参考文献:
NLP从入门到放弃.BERT从零详细解读,看不懂来打我.B站.2021.3
0与1的邂逅.深度学习 | 三个概念:Epoch, Batch, Iteration.简书.2019.11