基础结构-TRM的Encoder

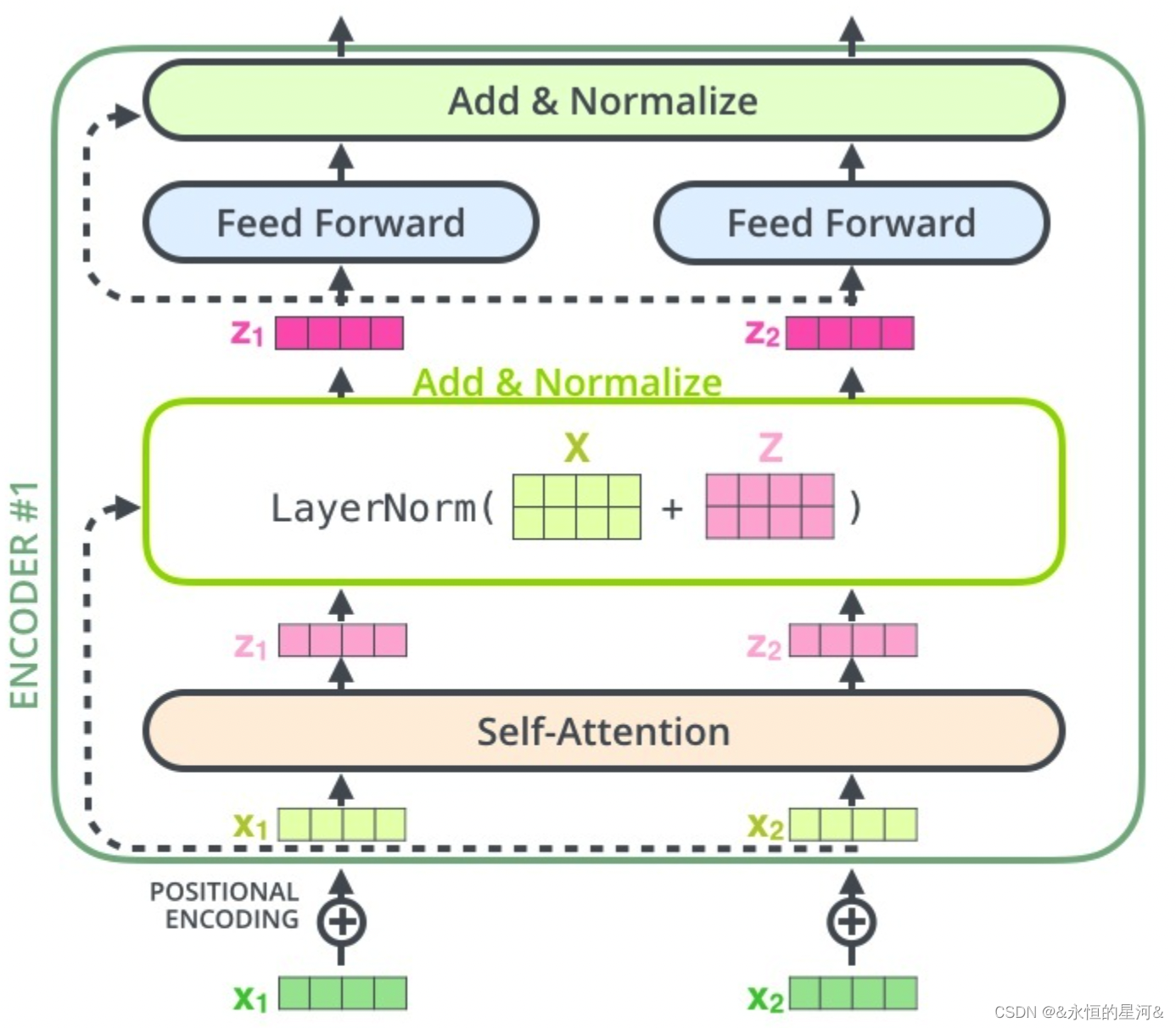
BERT使用多个Encoder堆叠在一起,其中bert base使用的是12层的encoder,bert large使用的是24层的encoder。

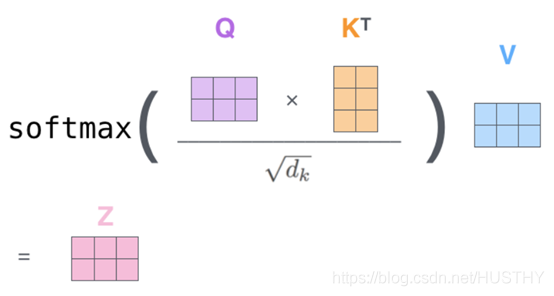
对于transformer来说,输入包括两个部分:
一部分是input enbedding,就是做词的词向量,比如说随机初始化,或者是使用word to vector。
第二个部分是Positional Encoding,是位置编码,使用的是三角函数,也就是正余弦函数去代表它
但是在bert中,我们分为了三个部分,第一个是token emb,第二个是segment emb,第三部分是position emb。这里的position emb区别于trasfomer中的position encoding。
bert输入部分详细解读
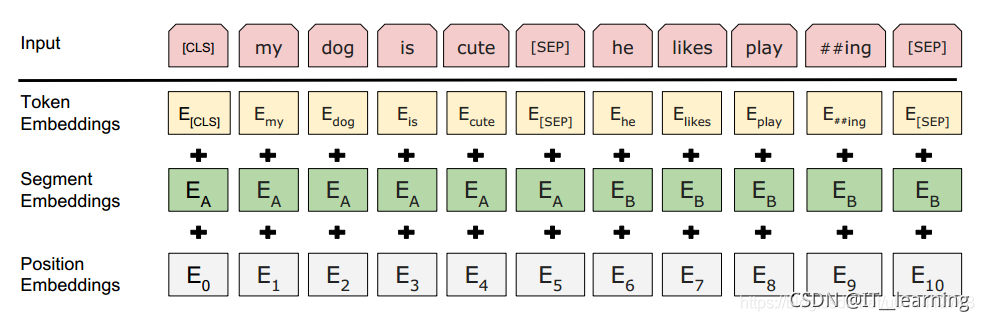
我们刚才谈到bert的输入部分由三部分组成:
Input = token emb + segment emb + position emb

如图所示:
首先我们看Input代表的这个东西:
粉色的这一行,重点关注两个部分
第一部分是正常词汇:my、dog、is、cute、he、likes、play、##ing,这些事bert分词器分词之后的东西,
第二部分是特殊词汇,[CLS]、[SEP]、[SEP]
这三个是两种特殊符号,bert的预训练中有一个是NSP任务,NSP的全称叫做 NEST Sentence Prediction,去判断两个句子之间的关系,它具体的东西我们后面会去讲,在这里大家只要知道NSP任务是处理两个句子之间的关系,因为处理的是两个句子,所以我需要的是一个符号,去告诉模型,在这个符号之前是一个句子,在这个符号之后是另一个句子。这是[sep]的作用,然后呢,我们要做的NSP任务又是一个二分类任务,即句子之间是什么关系的二分类任务,那么怎么去做这个二分类任务,作者在句子的最前面加了一个叫做[CLS]的特殊符号,在训练的时候,将[CLS]的输出向量接一个二分类器,去做一个二分类任务,这是[CLS]的一个作用。很多人对[CLS]会有一个误解,认为[CLS]这个输出向量代表了整个句子或者整两个句子的语义信息。这个说法是正确的吗?我简单说一下我自己的理解,在预训练完之后,[CLS]这个向量的输出向量并不能说代表了整个句子的语义信息,我也没有在原论文中看到过作者相关的说法,当然如果有朋友看到了,可以和我说一下。我自己的理解是[CLS]这个向量用在了NSP任务中,它是一个二分类任务,它和编码整个句子的语义信息相去甚远。所以大家都会发现一个问题,就是你在用[CLS]向量这个输出向量去无监督地做文本相似度的时候,效果会非常的差。
也就是说,CLS向量不能代表整个句子的语义信息。bert pretrain模型直接拿来用作sentence embedding效果甚至不如word embedding,cls的embedding效果最差(也就是你说的pooled output)。把所有普通token embedding做pooling勉强能用(这个也是开源项目bert-as-service的默认做法),但也不会比word embedding更好。
那么现在的问题是,究竟能不能用这个cls向量来做无监督的文本相似度。
接下来的三个部分:
第一个部分叫Token Embeddings. Token Embedings其实很简单,就是对Input中的所有词汇(包括正常词汇和特殊词汇)都去做正常的embeddings,比如说随机初始化。
第二个部分呢,就是Segment Embeddings,这个也是由于我们处理的是两个句子,所以我们需要对两个句子进行区分,那么第一个句子(包括[CLS]到[SEP])这一部分我们全部用0来表示。后面的这个句子,全部用1来表示,代表了两个句子。
第三个部分,是position embeddings,也就是bert的输入部分和tramsfomer的输入部分的一个很大的不同点。在transformer中,它用的是正余弦函数,我们使用的是随机初始化,然后让模型自己去学习出来。比如说第1个位置我给它定为0,第2个位置定为1,第3个位置定为2,…,一直到第512个位置,让它自己去学每个位置的embedding是什么样子的。至于说为什么使用embedding,我还没有看到一个特别好的解释,大家在做实验的时候发现用positon emdeddings效果也可以。