1. 引言
从现在的大趋势来看,使用某种模型预训练一个语言模型看起来是一种比较靠谱的方法。从之前 AI2 的 ELMo,到 OpenAI 的 fine-tune transformer,再到 Google 的 BERT、GPT,全都是对预训练的语言模型的应用。
本文将主要介绍 BERT 和 GPT 这两种常见语言模型及其应用场景,较少涉及具体原理的讲解(自身水平不足)。
2. BERT
2.1 简介
BERT 在2018年出现,被认为是 NLP 的 ImageNet 时刻,可以最好地表示单词和句子,增强对自然语言的理解,进而最好地捕捉基本语义和关系,有效增强了很多下游 NLP 任务的性能。BERT 可以理解为一个非常大的已经训练好的语言模型,涵盖了尽可能多的知识,能够作为很多任务的前置处理模块,类似预处理模块。
BERT 开发的两个步骤:第 1 步,你可以下载预训练好的模型(这个模型是在无标注的数据上训练的,可免费下载)。然后在第 2 步只需要关心模型微调即可。
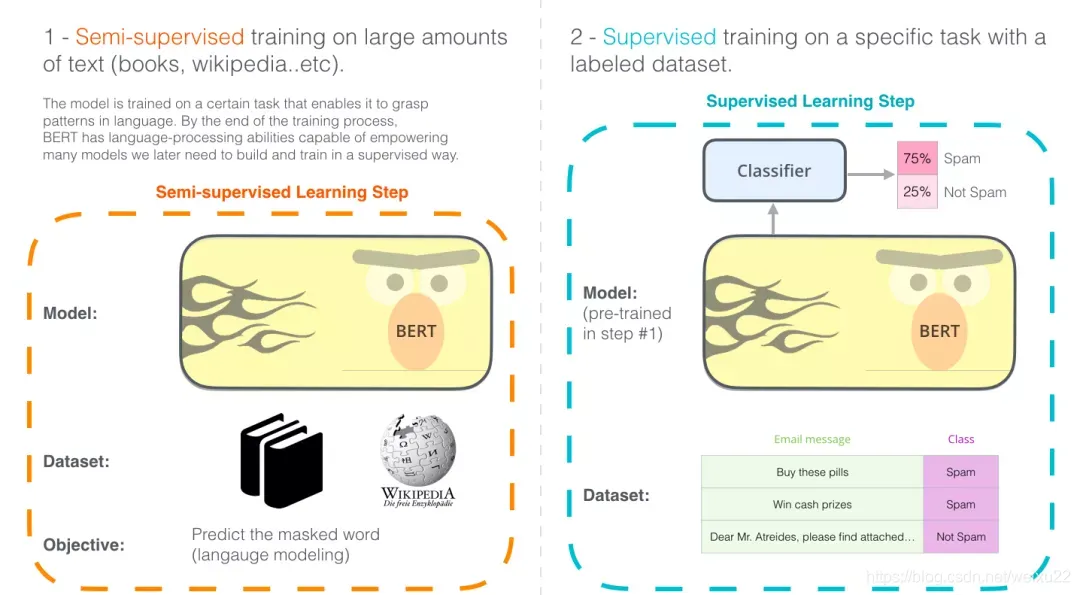
BERT 模型都有大量的 Encoder 层,BASE 版本由 12 层 Encoder,Large 版本有 20 层 Encoder。同时,这些 模型也有更大的前馈神经网络(分别有 768 个和 1024 个隐藏层单元)和更多的 attention heads(分别有 12 个和 16 个),超过了原始 Transformer 论文中的默认配置参数。
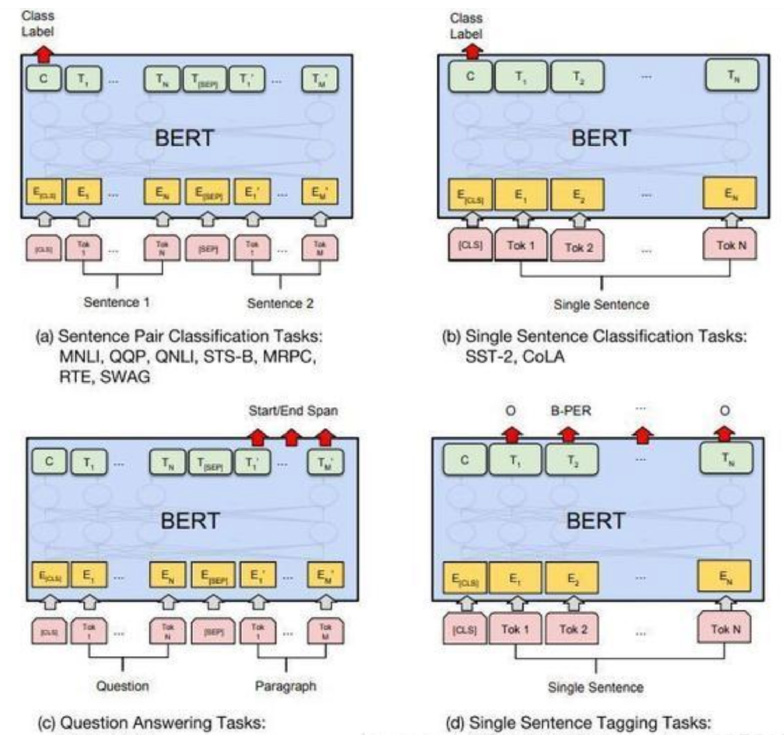
2.2 举例说明(句子分类)
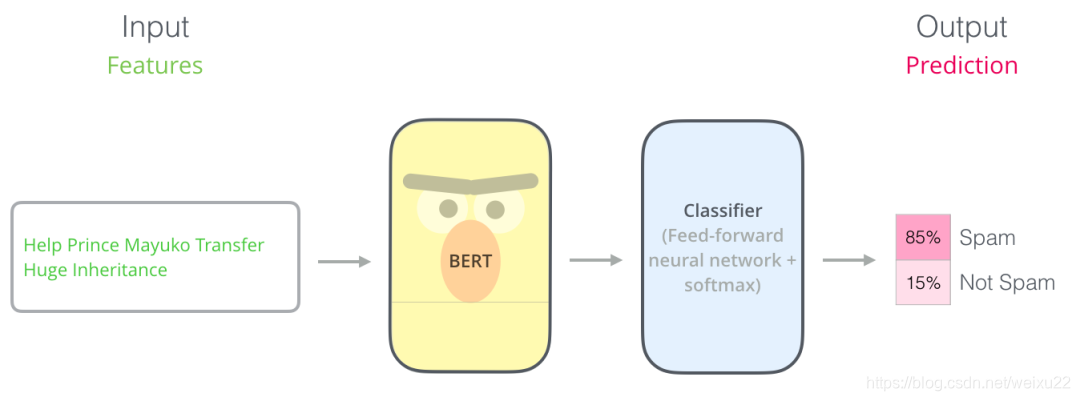
为了训练这样一个模型,你主要需要训练分类器(上图中的 Classifier),在训练过程中几乎不用改动BERT模型(可固定这部分的参数不变,仅更新分类器模块的参数)。这个训练过程称为微调,是迁移学习的概念。
2.2.1 模型输入
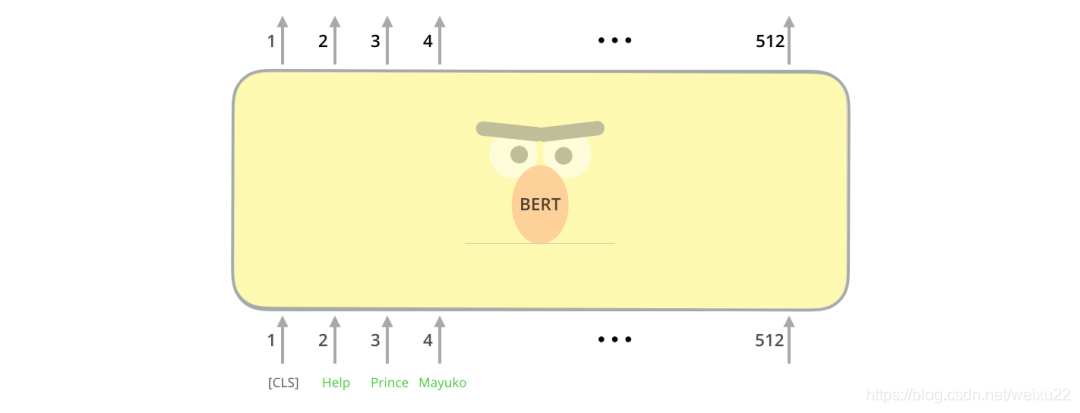
第一个输入的 token 是特殊的 [CLS],它 的含义是分类(class的缩写)。
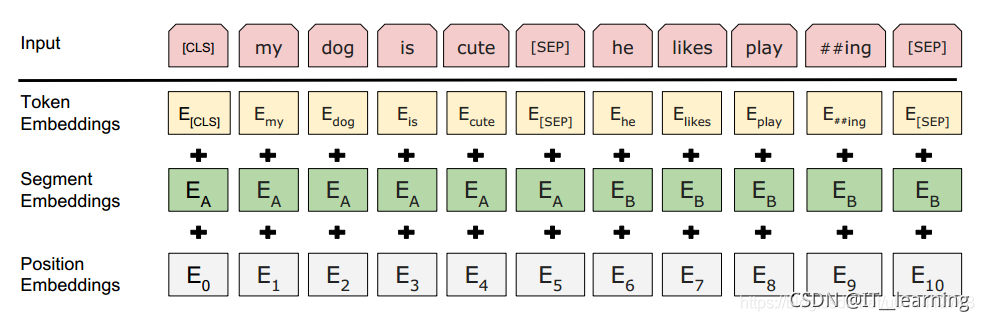
就像 Transformer 中普通的 Encoder 一样,BERT 将一串单词作为输入,这些单词在 Encoder 的栈中不断向上流动。每一层都会经过 Self Attention 层,并通过一个前馈神经网络,然后将结果传给下一个 Encoder。
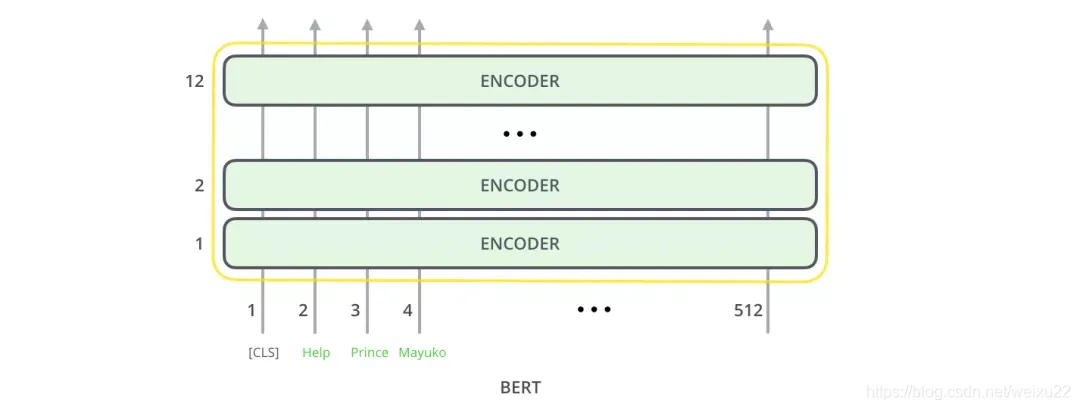
在模型架构方面,到目前为止,和 Transformer 是相同的(除了模型大小,因为这是我们可以改变的参数)。我们会在下面看到,BERT 和 Transformer 在模型的输出上有一些不同。
2.2.2 模型输出
每个位置输出一个大小为 hidden_size(在 BERT Base 中是 768)的向量。对于上面提到的句子分类的例子,我们只关注第一个位置的输出(输入是 [CLS] 的那个位置)。
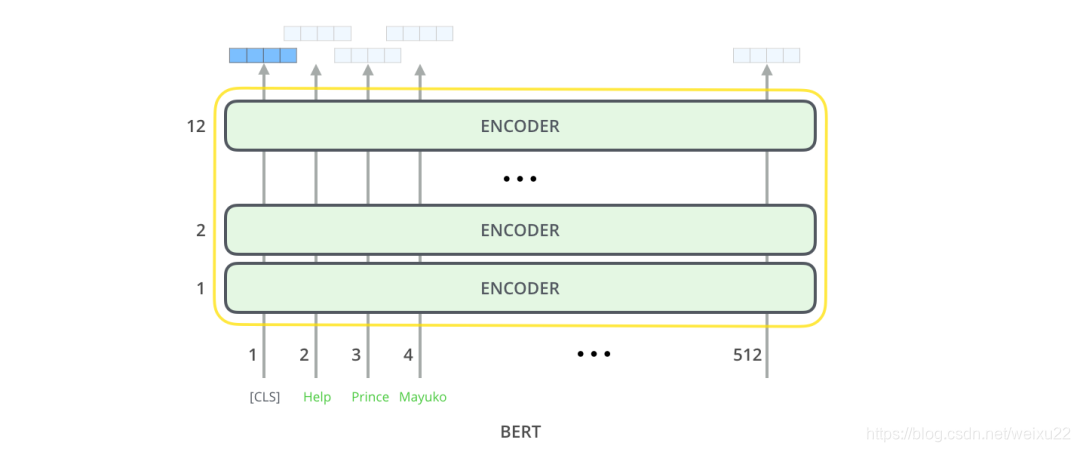
这个输出的向量现在可以作为后面分类器的输入。论文里用单层神经网络作为分类器,取得了很好的效果。
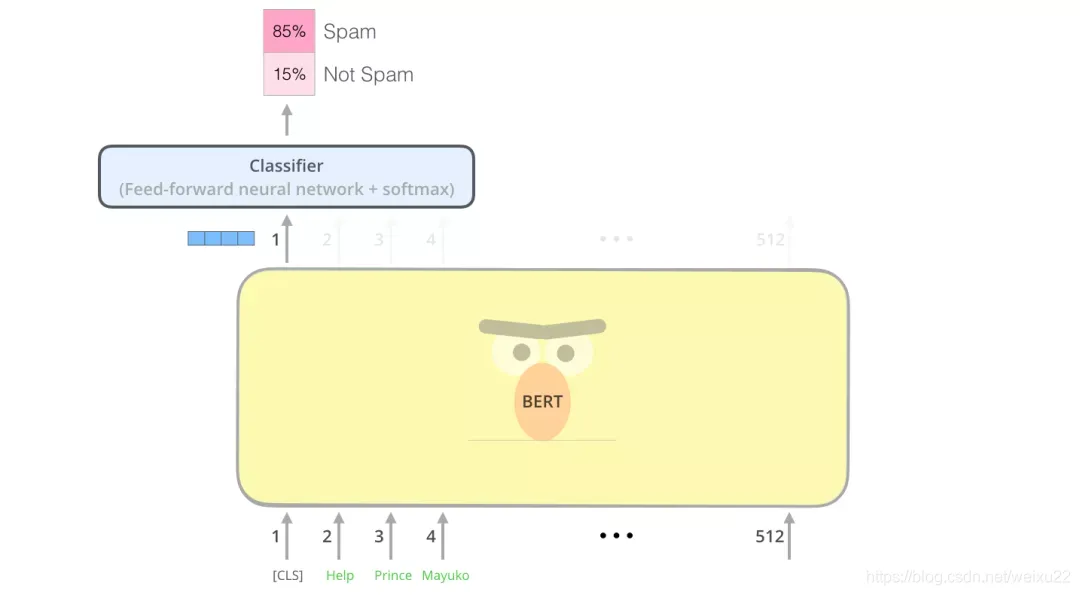
如果你有更多标签(例如你是一个电子邮件服务,需要将邮件标记为 “垃圾邮件”、“非垃圾邮件”、“社交”、“推广”),你只需要调整分类器的神经网络,增加输出的神经元个数,然后经过 softmax 即可。
2.3 词嵌入技术
2.3.1 Word2Vec
单词不能直接输入机器学习模型,而需要某种数值表示形式,以便模型能够在计算中使用。通过 Word2Vec,我们可以使用一个向量(一组数字)来恰当地表示单词,并捕捉单词的语义以及单词和单词之间的关系。

人们很快意识到,相比于在小规模数据集上和模型一起训练词嵌入,更好的一种做法是,在大规模文本数据上预训练好词嵌入,然后拿来使用。因此,我们可以下载由 Word2Vec 和 GloVe 预训练好的单词列表,及其词嵌入。
2.3.2 语境词嵌入
如果我们使用 Glove 的词嵌入表示方法,那么不管上下文是什么,单词 “stick” 都只表示为同一个向量。一些研究人员指出,像 “stick” 这样的词有多种含义。为什么不能根据它使用的上下文来学习对应的词嵌入呢?这样既能捕捉单词的语义信息,又能捕捉上下文的语义信息。于是,语境化的词嵌入模型应运而生。
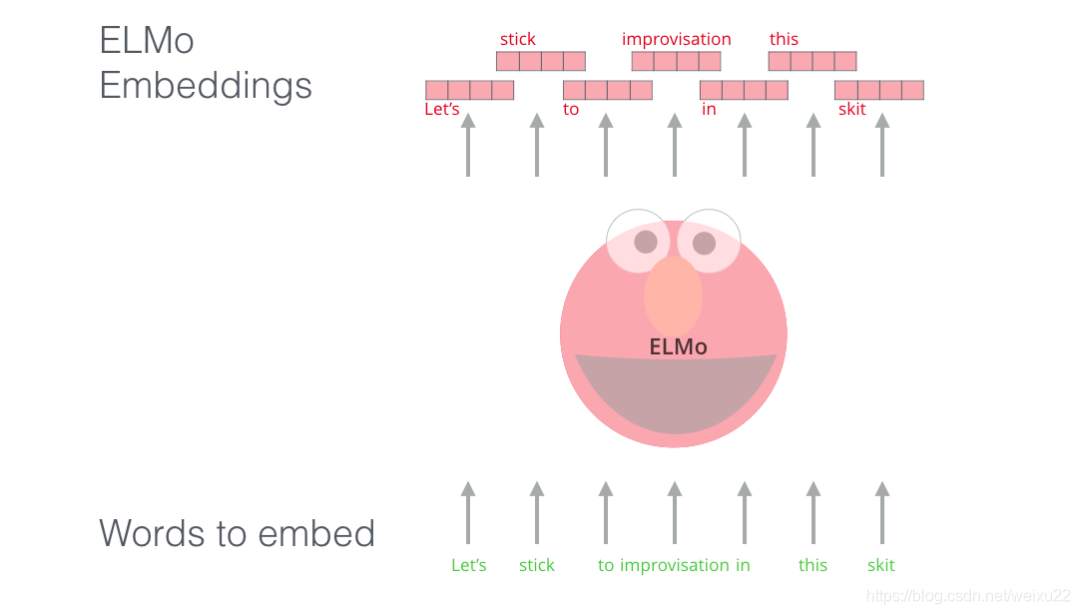
ELMo 没有对每个单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。它使用在特定任务上经过训练的双向 LSTM 来创建这些词嵌入。
2.4 下游任务的迁移学习
BERT 的论文展示了 BERT 在多种任务上的应用。
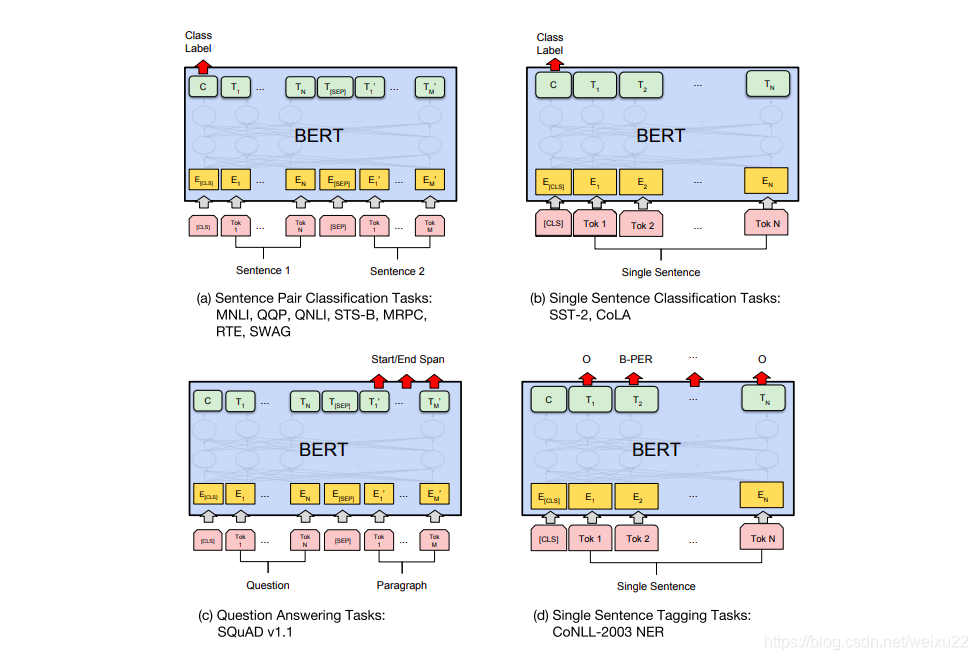
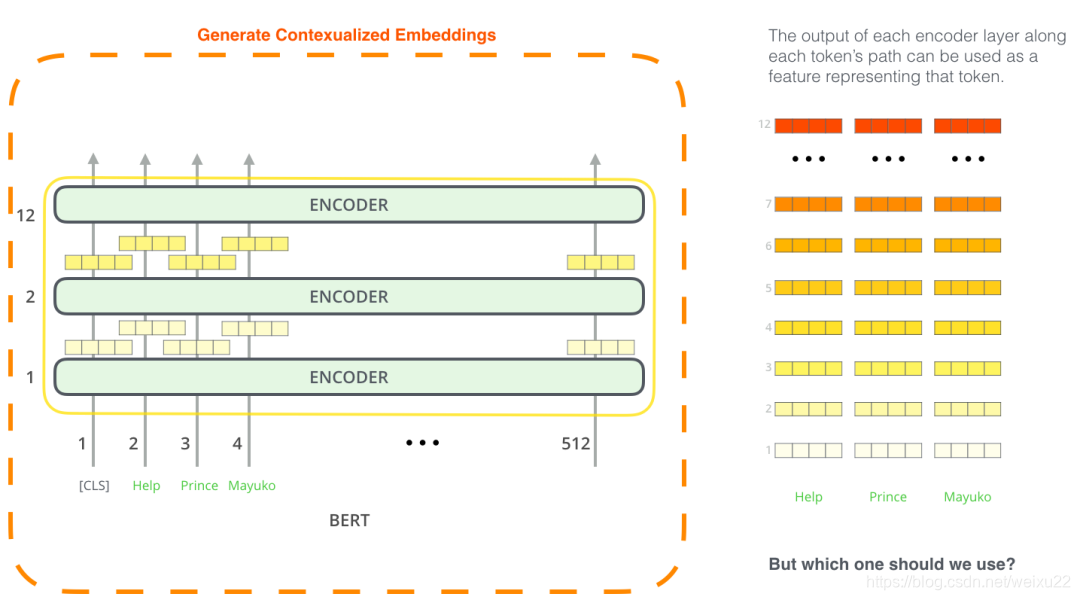
使用 BERT 并不是只有微调这一种方法。就像 ELMo 一样,你可以使用预训练的 BERT 来创建语境化的词嵌入。然后你可以把这些词嵌入用到你现有的模型中。论文里也提到,这种方法在命名实体识别任务中的效果,接近于微调 BERT 模型的效果。
尝试 BERT 的最佳方式是通过托管在 Google Colab 上的 BERT FineTuning with Cloud TPUs。如果你之前从来没有使用过 Cloud TPU,那这也是一个很好的尝试开端,因为 BERT 代码可以运行在 TPU、CPU 和 GPU。
3. GPT
GPT 更多地用于自然语言生成,比如写文章、写诗等创作型任务,它本质上是一个语言模型。语言模型基本上是一个机器学习模型,它可以根据句子的一部分预测下一个词。最著名的语言模型就是手机键盘,它可以根据你输入的内容,提示下一个单词。从这个意义上讲,GPT-2 基本上就是键盘应用程序中预测下一个词的功能,但 GPT-2 比你手机上的键盘 app 更大更复杂。GPT-2 是在一个 40 GB 的名为 WebText 的数据集上训练的,OpenAI 的研究人员从互联网上爬取了这个数据集,作为研究工作的一部分。
GPT-2 是使用 Transformer 的 Decoder 模块构建的。另一方面,BERT 是使用 Transformer 的 Encoder 模块构建的。这些模型的实际工作方式是,在产生每个 token 之后,将这个 token 添加到输入的序列中,形成一个新序列。然后这个新序列成为模型在下一个时间步的输入。这是一种叫“自回归(auto-regression)”的思想。这种做法可以使得 RNN 非常有效。