BERT是基于transformer结构的预训练模型。具体bert原理介绍,请参考博客:Bert系列解读及改进_&永恒的星河&的博客-CSDN博客_bert系列
求解Bert模型的参数量是面试常考的问题,也是作为算法工程师必须会的一个点。所谓会用并不代表熟悉。今天以BERT BASE模型为例子,计算其参数量。开始正题:
在BERT BASE中:
- 词表的大小是(word list):30522
- Encoder层个数是(layer):12
- 词向量的大小(vocab dim):768
- 文本最大长度(seq length):512
- 头个数(multi head attention):12
- Feed Forward的两层全链接层神经元个数分别是:3702, 768
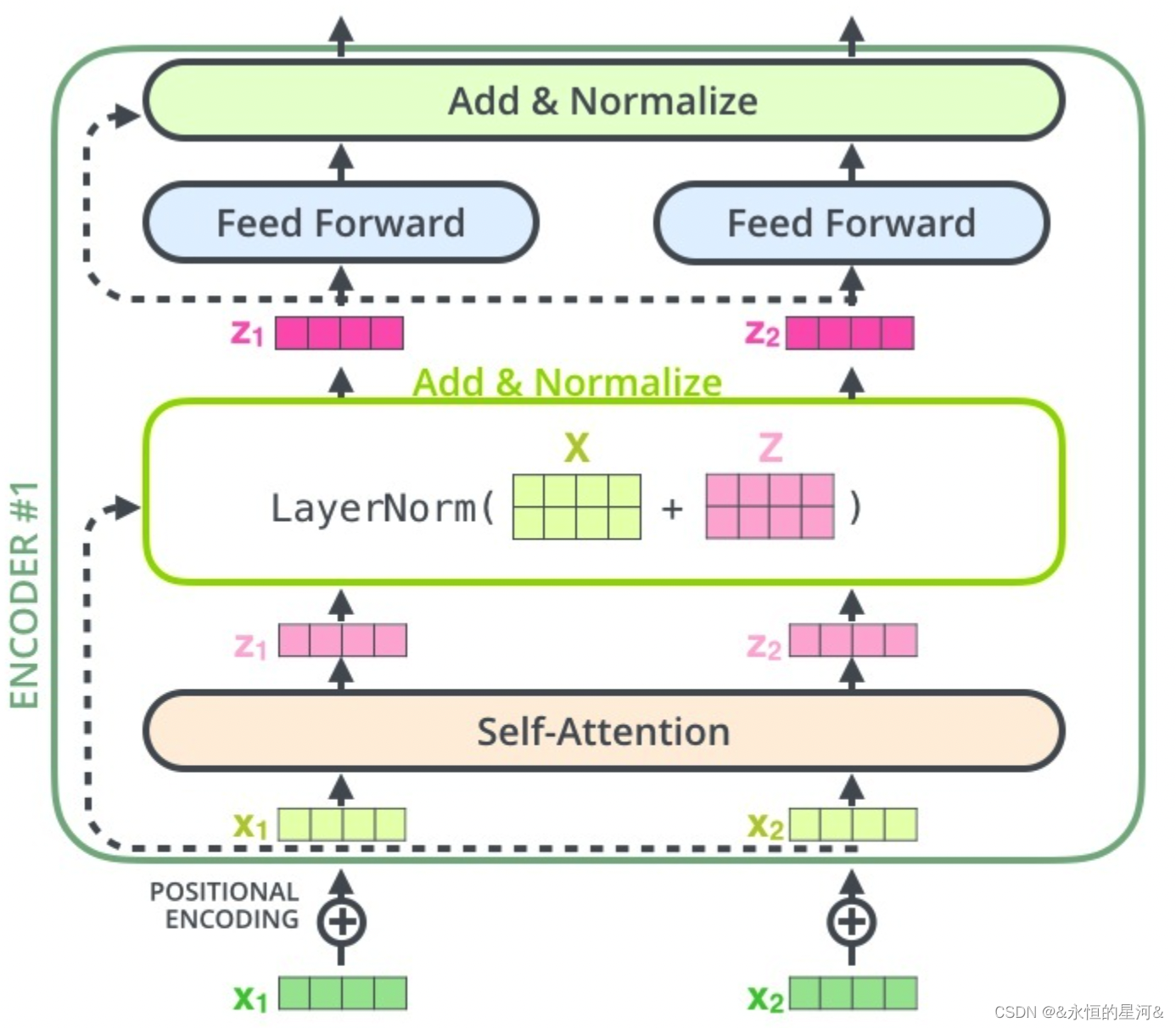
BERT 的Encoder结构
BERT中Encoder包括: Embedding层,Multi-Head Attention 层,Feed-Forward Network层,LayerNorm层参数。
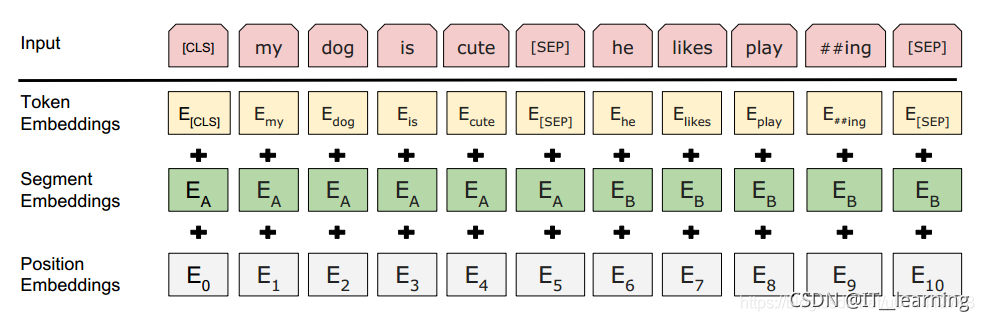
1. Embedding层
该层包括三种Embedding,具体是Token Embedding, Segment Embedding, Position Embedding
Token Embedding 层参数: 30522 * 768
Segment Embedding层参数:2 * 768
Position Embedding层参数:512 * 768
因此总的参数量为:(30522 + 512 +2)* 768 = 23835648 = 22.7 M
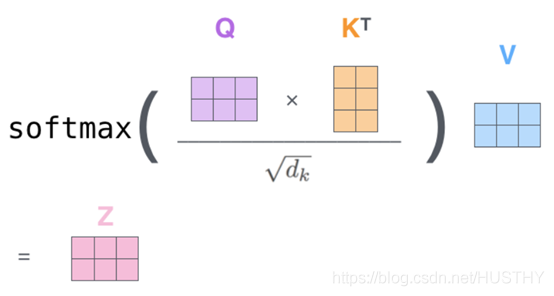
2. Multi-Head Attention层
该层主要是由Q、K、V三个矩阵运算组成,BERT模型中是Multi-head多头的Self-attention(记为SA)机制。先通过Q和K矩阵运算并通过softmax变换得到对应的权重矩阵,然后将权重矩阵与 V矩阵相乘,最后将12个头得到的结果进行concat,得到最终的SA层输出。
又因为BERT模型中包含12个Transformer Encoder层,因此改层的参数总量为:[768 * (768/12) * 3 * 12 + 768 * 768 ] * 12 = 28311552 = 27M
3. LayerNorm层
LayerNorm层主要有weight和bias两个参数。而LN层在Embedding层、Self-attention层、Feed-Forward Network层三个层都有用到,因此LN层的参数总量为:768 * 2 + (768 * 2)* 12 + (768 * 2)* 12 = 38400 = 37.5KB
4. Feed-Forward Network层
前馈网络FFN主要由两个全连接层组成,且W1和W2的形状分别是(768,3072),(3072,768),层数为12,因此该层的参数量为:
(768 * 3072 + 3072 * 768)* 12 = 56623104 = 54M
将上面的计算结果加起来,那么BERT模型的参数总量为:23835648 + 28311552 + 56623104 + 38400 = 108808704 ≈ 104M。
Embedding层约占参数总量的20%,Transformer层约占参数总量的80%。