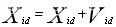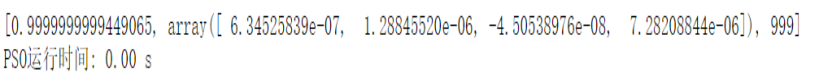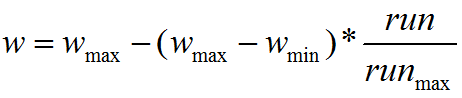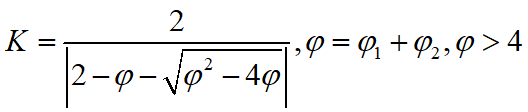粒子群优化算法PSO
- 粒子群优化算法
- 基本原理
- 算法步骤
- 代码实现
粒子群优化算法
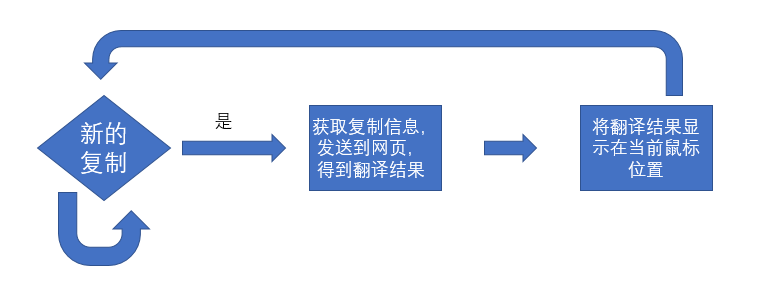
一群鸟在随机搜索食物,在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是它们知道当前的位置离食物还有多远。那么,找到食物的最简单有效的方法就是搜寻离食物最近的鸟的周围区域。如果将鸟抽象为没有体积和质量的“粒子”,相当于问题的一个解,鸟群就相当于一个解集,离食物最近的鸟相当于解群中的最优粒子,食物的位置相当于全局最优解。
基本原理
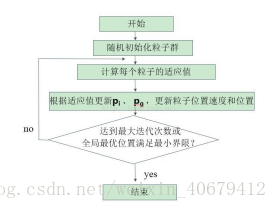
粒子群算法是由 Kennedy 和 Eberhart 等通过模拟鸟群的觅食行为而提出的一种基于群体协作的随机搜索算法。标准粒子群算法搜索寻优的基本框架如图 所示:

每个粒子具有两个属性:
粒子位置 x
粒子速度 v
假设在一个 D 维的目标搜索空间中,有 N 个粒子组成一个群落。则:
第 i 粒子的位置为一个 D 维向量,表示为:
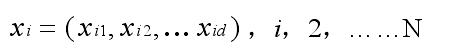
第 i 个粒子的飞行速度也是一个 D 维向量,表示为:
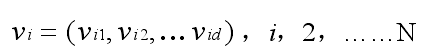
第 i 个粒子迄今为止搜索到的最优位置为个体极值,表示为:

整个粒子群迄今为止搜索到的最优位置为全局极值,表示为:
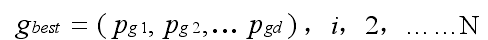
每个粒子追随当前的最优粒子在解空间中运动,并根据如下公式来更新自己的速度和位置:
速度变换公式:
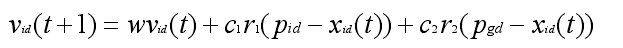
位置变换公式为:
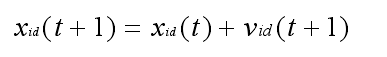
其中,w 为惯性权值;c1 和 c2 为学习因子,分别反映粒子的自我学习能力和向群体 最 优 粒 子学 习 的 能 力 ; r1 和 r2 为 [0,1] 的 均 匀 随 机数 ;vi为 粒 子 速 度,vi属于[-vmax,vmax],vmax是用户设定的一个常量,用来限制粒子的速度。
公式中,第一部分是粒子先前的速度与惯性权值的积,用来保证算法的全局
收敛性,第二部分是粒子自身的学习能力,第三部分是粒子的社会学习能力,表示粒子之间的信息共享与相互协作,第二、三部分是引起粒子速度变化的社会因素,使其在最优解附近具有局部搜索的能力。
算法步骤
基于上述流程,标准粒子群算法的具体步骤可描述如下:
步骤 1:在可行域中随机初始化一群粒子,包括粒子的规模 N、位置 xi和速
度 vi;
步骤 2:根据目标函数计算每个粒子的适应度值 Fit[i] ;
步骤 3:比较每个粒子的适应度值Fit[i]与个体极值 Pbest[i],若Fit[i] > Pbest[i],
则用 Fit[i] 替换 Pbest[i];
步骤 4:比较每个粒子的适应度值 [i]itF 与当前的全局极值 gbest[i],若
Fit[i] > gbest[i],则用 Fit[i] 替换 gbest[i];
步骤 5:根据公式(2-1),(2-2)更新粒子的速度 vi 和位置 xi ;
步骤 6:判断是否达到停止准则,如果达到设置的搜索精度或达到最大迭代次
数则退出,否则返回步骤 2。
代码实现
# coding: utf-8
import numpy as np
import random
import matplotlib.pyplot as pltclass PSO():# PSO参数设置def __init__(self, pN, dim, max_iter):self.w = 0.8self.c1 = 2self.c2 = 2self.r1 = 0.6self.r2 = 0.3self.pN = pN # 粒子数量self.dim = dim # 搜索维度self.max_iter = max_iter # 迭代次数self.X = np.zeros((self.pN, self.dim)) # 所有粒子的位置和速度self.V = np.zeros((self.pN, self.dim))self.pbest = np.zeros((self.pN, self.dim)) # 个体经历的最佳位置和全局最佳位置self.gbest = np.zeros((1, self.dim))self.p_fit = np.zeros(self.pN) # 每个个体的历史最佳适应值self.fit = 1e10 # 全局最佳适应值#目标函数Sphere函数def function(self, X):return X**4-2*X+3#初始化种群def init_Population(self):for i in range(self.pN): #因为要随机生成pN个数据,所以需要循环pN次for j in range(self.dim): #每一个维度都需要生成速度和位置,故循环dim次self.X[i][j] = random.uniform(0, 1)self.V[i][j] = random.uniform(0, 1)self.pbest[i] = self.X[i] #其实就是给self.pbest定值tmp = self.function(self.X[i]) #得到现在最优self.p_fit[i] = tmp 这个个体历史最佳的位置if tmp < self.fit: #得到现在最优和历史最优比较大小,如果现在最优大于历史最优,则更新历史最优self.fit = tmpself.gbest = self.X[i]# 更新粒子位置def iterator(self):fitness = []for t in range(self.max_iter): #迭代次数,不是越多越好for i in range(self.pN): # 更新gbest\pbesttemp = self.function(self.X[i])if temp < self.p_fit[i]: # 更新个体最优self.p_fit[i] = tempself.pbest[i] = self.X[i]if self.p_fit[i] < self.fit: # 更新全局最优self.gbest = self.X[i]self.fit = self.p_fit[i]for i in range(self.pN):self.V[i] = self.w * self.V[i] + self.c1 * self.r1 * (self.pbest[i] - self.X[i]) + \self.c2 * self.r2 * (self.gbest - self.X[i])self.X[i] = self.X[i] + self.V[i]fitness.append(self.fit)print(self.X[0], end=" ")print(self.fit) # 输出最优值return fitness##输出
#程序
my_pso = PSO(pN=30, dim=1, max_iter=100)
my_pso.init_Population()
fitness = my_pso.iterator()
# 画图
plt.figure(1)
plt.title("Figure1")
plt.xlabel("iterators", size=14)
plt.ylabel("fitness", size=14)
t = np.array([t for t in range(0, 100)])
fitness = np.array(fitness)
plt.plot(t, fitness, color='b', linewidth=3)
plt.show()
在上面我们计算 适应度函数
我们看一看结果:
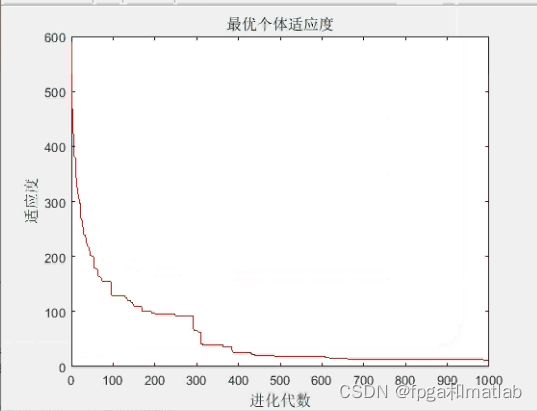
1.迭代图像