BERT模型
Paper: https://arxiv.org/abs/1810.04805
BERT 全称为Bidirectional Encoder Representation from Transformers(来自Transformers的双向编码表示),谷歌发表的发的论文Pre-traning of Deep Bidirectional Transformers for Language Understanding中提出的一个面向自然语言处理任务的无监督预训练语言模型。是近年来自然语言处理领域公认的里程碑模型。
BERT的创新在于Transformer Decoder(包含Masked Multi-Head Attention)作为提取器,并使用与之配套的掩码训练方法。虽然使用了双编码使得BERT不具有文本生成能力,但BERT在对输入文本的编码过程中,利用了每个词的所有上下文信息,与只能使用前序信息提取语义的单向编码器相比,BERT的语义信息提取能力更强。
下面距离说明单向编码与双向编码在语义理解上的差异
今天天气很差,我们不得不取消户外运动。
将句子中的某个字或者词“挖”走,句子变为
今天天气很{},我们不得不取消户外运动。
分别从单向编码(如GPT)和双向编码(如BERT )的角度来考虑“{}”中应该填什么词。单向编码只会使用“今天天气很”这5个字的信息来推断“{}”的字或词,以人类的经验与智慧,使用概率最大的词应该是:“好”“不错”“差”“糟糕”,而这些词可以被划分为截然不同的两类。
通过这个例子我们可以直观地感觉到,不考虑模型的复杂度和训练数据量,双向编码与单向编码相比,可以利用更多的上下文信息来辅助当前的语义判断。在语义理解能力上,采用双向编码的方式是最科学的,而BERT的成功很大程度上有此决定。
BERT的结构

参数
L L L:Transformer blocks;
H H H:hidden size;
A A A:self-attention heads;
𝐵 𝐸 𝑅 𝑇 𝐁 𝐀 𝐒 𝐄 : 𝐵𝐸𝑅𝑇_{𝐁𝐀𝐒𝐄}: BERTBASE: 𝐿 𝐿 L=12, 𝐻 𝐻 H=768, 𝐴 𝐴 A=12, Total Parameters=110𝑀
𝐵 𝐸 𝑅 𝑇 𝐋 𝐀 𝐑 𝐆 𝐄 𝐵𝐸𝑅𝑇_{𝐋𝐀𝐑𝐆𝐄} BERTLARGE: 𝐿 𝐿 L=24, 𝐻 𝐻 H=1024, 𝐴 𝐴 A=16, Total Parameters=340𝑀
无监督预训练深度双向语言模型
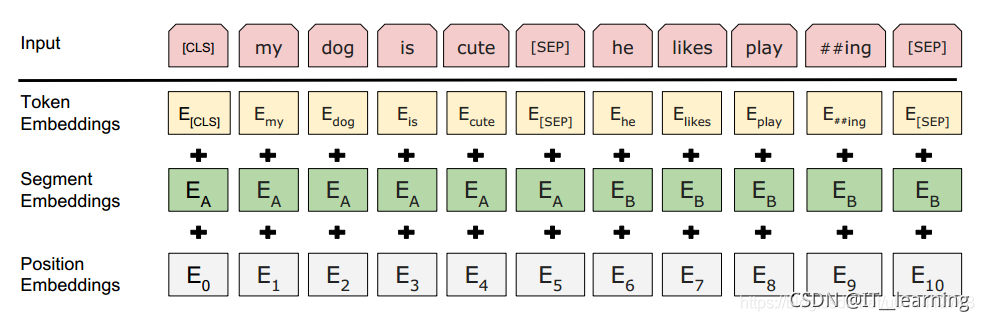
 (1) Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务Segment (2) Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务(3) Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
(1) Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务Segment (2) Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务(3) Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
预训练任务
Task1: Masked LM
为了构建一个深层的真双向语言模型,但是标准的语言模型是使用了马尔可夫链进行的单向编码,即使使用 LTR 与 RTL,但也是假的双向编码,性能会受到极大的影响。使用完形填空机制可以避免标准的语言模型的编码瓶颈。
完形填空策略:随机的 mask 掉 15% 的单词,然后使用编码器最后的 hidden state 过一层 softmax 进行完形填空预测。
但是这种策略会有两个缺点,以下是内容和解决方案:
Downside 1: mismatch
这样做构造了一种 mismatch:因为 [MASK] 永运不会出现在 fine-tuning 阶段,所以 pre-training 与 fine-tuning 出现了 mismatch。
缓解方案:对于随机选择的 15% 待 mask 单词,不是直接将它替换为 [MASK],而是再做一次随机:
80%:将该词替换为 [MASK]
10%:将该词替换为一个随机的词语
10%:不替换
原因:Transformer Encoder 不知道哪个单词被要求做预测,哪个单词被随机替换掉了,所以对于每个输入的单词,它都必须保持上下文嵌入;而且,现在这种策略下随机替换掉的单词只有 1.5%,几乎不会影响模型的语言建模能力。
Downside 2: slower
现在使用的 MLM 模型,每个 batch 只有 15% 的单词被预测,所以收敛速度确实慢了。但是效果带来的提升却很大。
Task2: Next Sentence Prediction
NLP 中有很多句子关系性的任务,这部分的能力不能通过 Task1 的 MLM 来俘获到,所以加入了一个二分类任务进行多任务学习。
策略:50% 的句子对,将第二句替换为随机的句子来构建负样本。
其他细节
(1) 训练语料:BooksCorpus 800𝑀 words + English Wikipedia 2,500𝑀𝑤𝑜𝑟𝑑𝑠
(2) batch size:256
(3) Adam: γ \gamma γ=1e−4, β 1 \beta_1 β1=0.9, β 2 \beta_2 β2=−.999,warmup
(4) dropout:0.1
(5) GELU
(6) loss:两个任务的 loss 和
下游监督任务微调
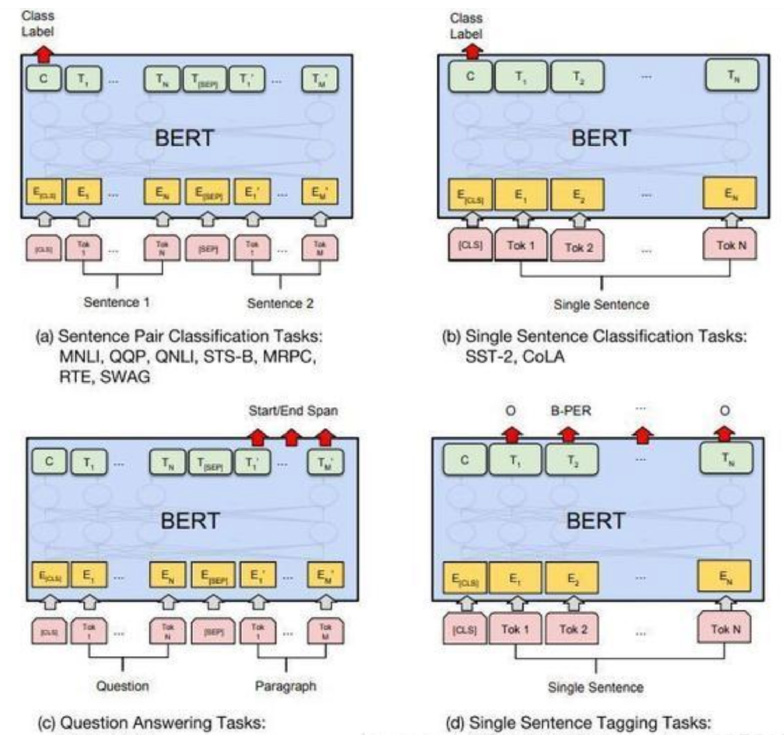
 (1) 单句/句子对分类任务:直接使用 [CLS] 的 hidden state 过一层 softmax 进行预测;
(1) 单句/句子对分类任务:直接使用 [CLS] 的 hidden state 过一层 softmax 进行预测;
(2) QA 任务:将问题和答案所在的段拼接起来,使用最后的答案段的 hidden state 向量来计算某个单词是答案开始单词和结束单词的概率,进而进行预测。
(3) 其中,S 和 E 是需要下游 fine-tuning 阶段训练的开始向量和结束向量。在推断阶段,会强行限制结束的位置必须在开始的位置之后。
(4) 序列标注任务:直接将序列所有 token 的最后一层 hidden state 喂进一个分类层(没有使用自回归、CRF)
BERT:强大的特征提取能力
BERT是由推碟的Transformer Encoder 层组成核心网络,辅以词编码和位置编码而成的。BERT的网络形态与GPT非常相似。简化版本的ELMO、GPT和BERT的网络如下图所示:

(1)ELMO 使用左右编码和自右向左编码的两个LSTM网络,分别以 P ( w 1 ∣ w 1 , . . . , w i − 1 ) P(w_1|w_1,...,w_{i-1}) P(w1∣w1,...,wi−1)和 P ( w i ∣ w i + 1 , w i + 2 , . . . , w n ) P(w_i|w_{i+1},w_{i+2},...,w_{n}) P(wi∣wi+1,wi+2,...,wn)为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码。
(2)GPT使用Transformer Decoder作为Transformer Block,以 P ( w i ∣ w 1 , . . . , w i − 1 ) P(w_i|w_1,...,w_{i-1}) P(wi∣w1,...,wi−1)为目标函数进行训练,用Transformer Block取代LSTM作为特征提取器,实现了单向编码,是一个标准的预训练语言模型。
(3)BERT 与ELMo的区别在于使用Transfomer Block作为特征提取器,加强了语义特征提取的能力;与GPT的区别在于使用Transfomer Enoder作为 Transfomer Block,将GPT的单向编码改为双向编码。BERT含弃了文本生成能力,换来了更强的语义理解能力。
将GPT结构中的Masked Multi-Head Attention层替换成Multi-Head Attention层,即可得到BERT的模型结构,如图:

参考
Bert原理
NLP Google BERT模型原理详解
《预训练语言模型》邵浩
欢迎关注公众号: