目录
一、前言
二、随机遮挡,进行预测
三、两句话是否原文相邻
四、两者结合起来
五、总结
六、参考链接
一、前言
Bert在18年提出,19年发表,Bert的目的是为了预训练Transformer模型encoder网络,从而大幅提高准确率
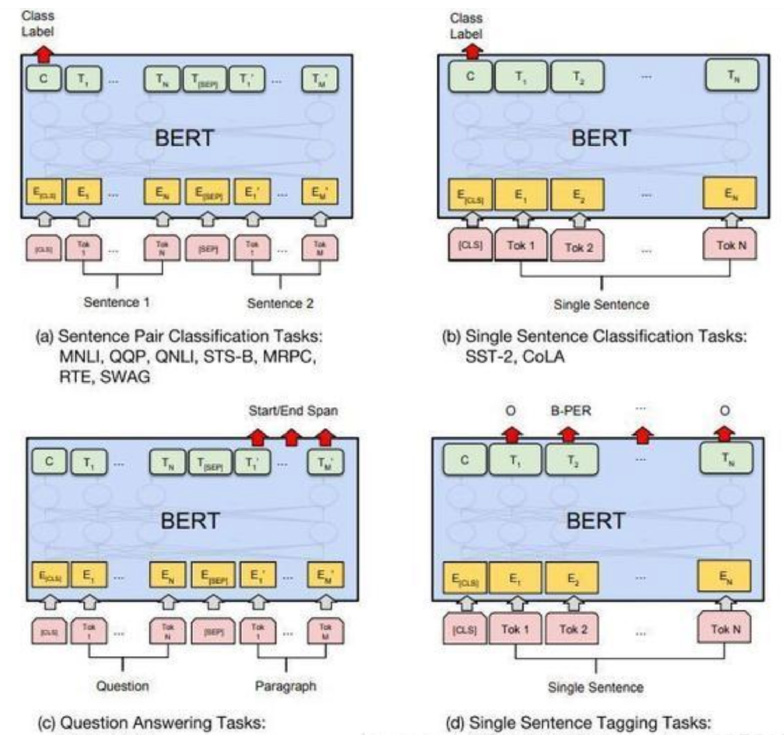
Bert 的基本想法有两个,第一个想法:随机遮挡一个或者多个单词,让encoder网络根据上下文来预测被遮挡的单词。第二个想法:把两个句子放在一起让encoder网络判断两句话是不是原文里相邻的两句话
Bert用这两个任务来预训练Transformer模型中的encoder网络。
二、随机遮挡,进行预测
下面我们讲一下第一个任务,预测被遮挡的单词
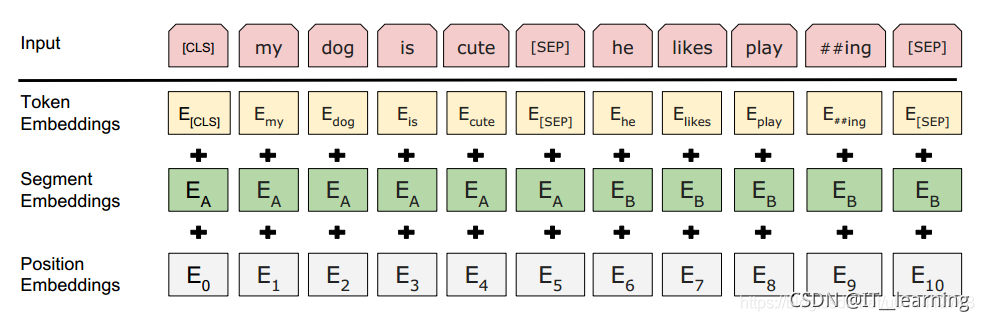
首先回顾一下,Transformer的encoder网络,输入是一句话,被分成了很多个单词,embedding把每个单词映射到一个词向量,然后是encoder网络,它是由多个block堆叠起来的,每个block分别是self-attention和全连接层,the cat sat on the mat.这句输入有6个单词,embedding把这六个单词映射成六个词向量,x1到x6,embedding网络的输入是6个词向量,所以最终输出6个向量,u1到u6
bert的第一个任务是预测被遮挡的单词,我们随机遮挡一个或者多个单词,然后问神经网络被遮挡的单词是什么,比如这个例子
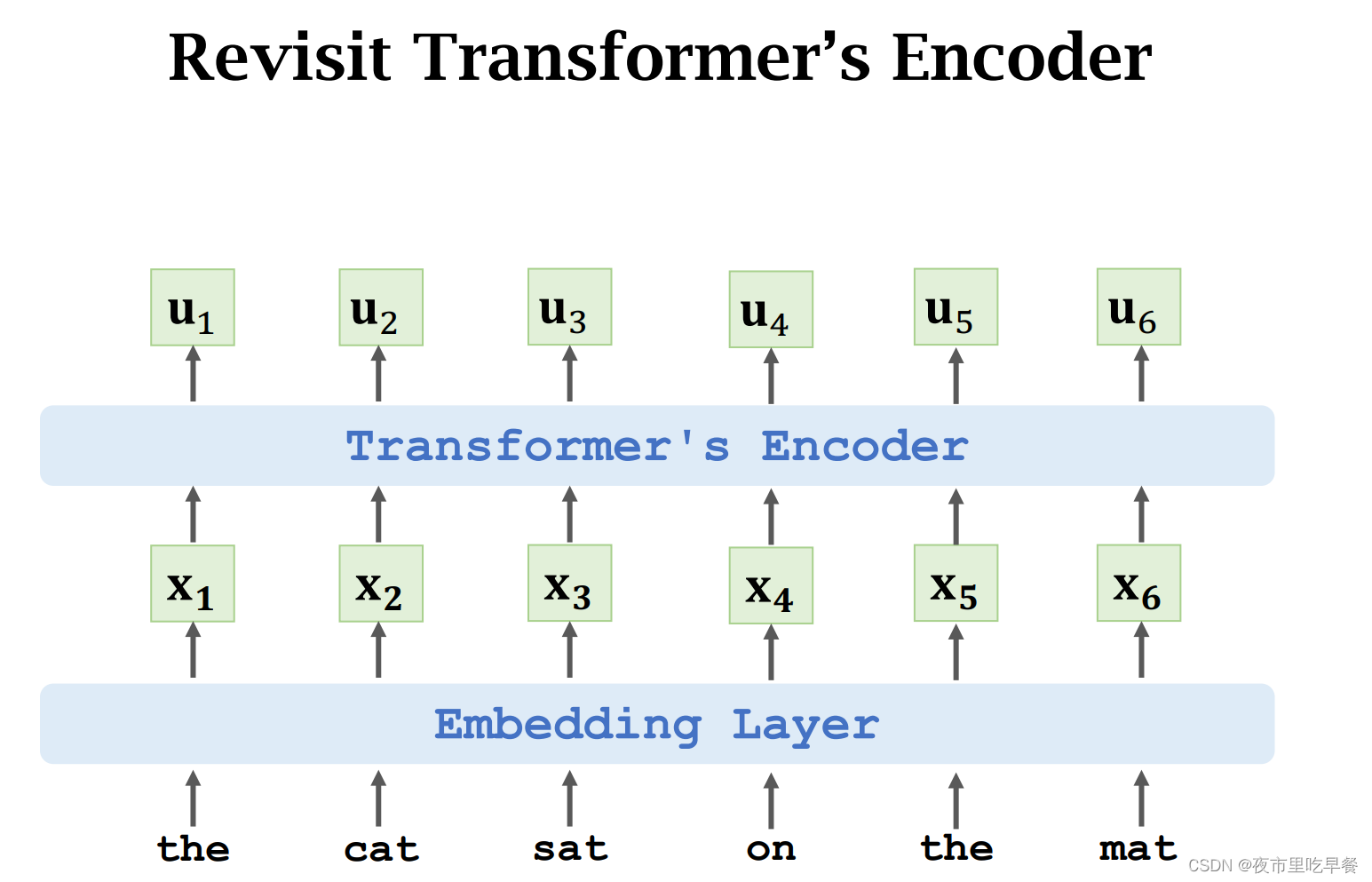

第二个单词被遮挡住,于是让神经网络来预测第二个单词,具体这么做
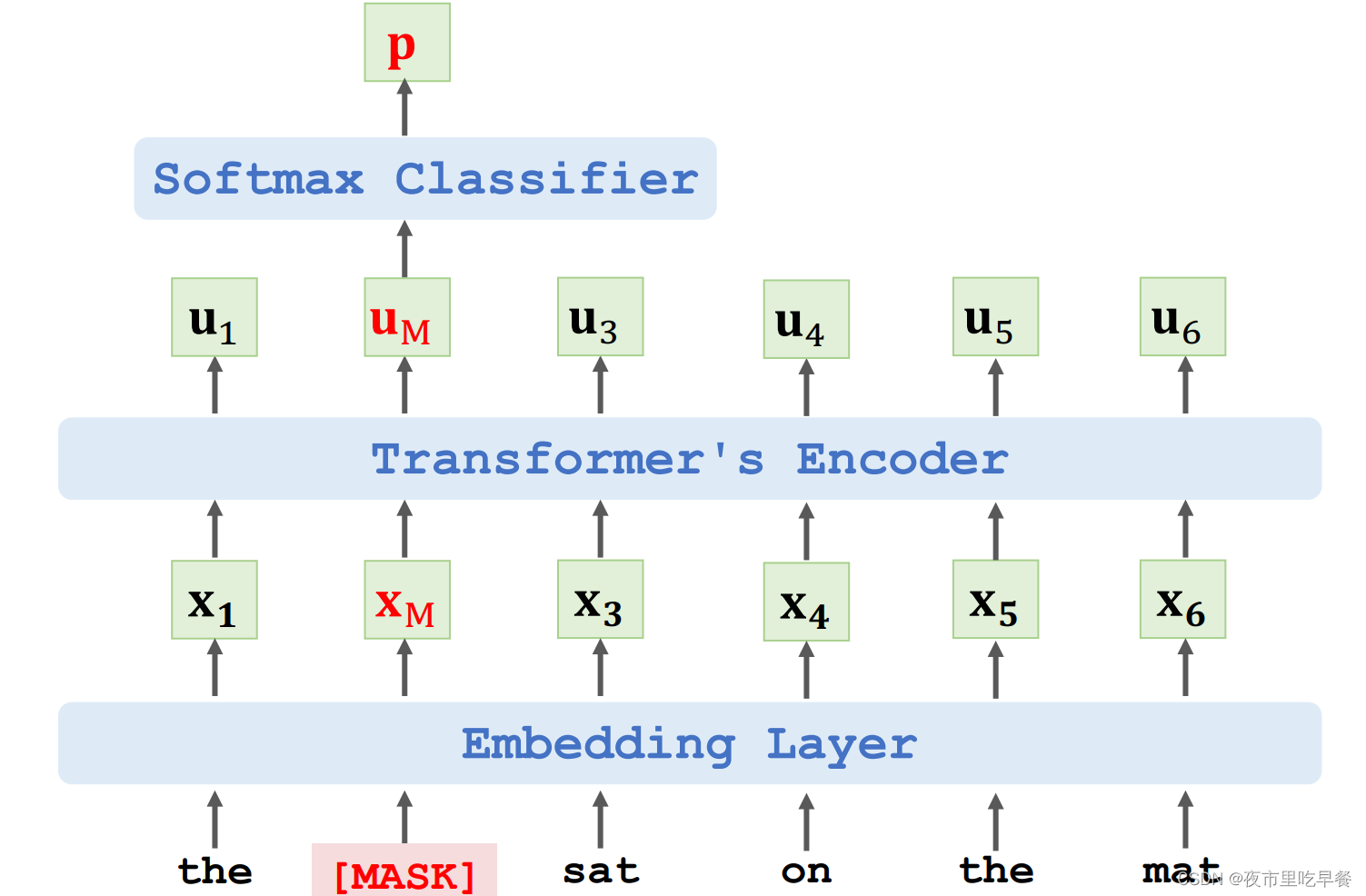
把输入的第二个单词替换成Mask符号,Mask符号会被embedding层编码成词向量Xm,把Mask位置的输出记作向量Um
Transformer的encoder网络不是一对一映射,而是多对一,Um向量不仅依赖于Xm,而且依赖于所有x向量,Um在Mask位置上,但是Um知道整句话的信息,Um包含上下文信息,所以可以用Um来预测被遮挡的单词,把Um作为特征向量输入一个Softmax分类器,分类器的输出是一个概率分布P,字典里每个单词都有一个概率值,通过概率值就能判断被遮挡的单词是什么。
以上这个例子我们遮挡住了cat这个单词,训练的时候我们希望分类器输出p向量接近cat的one-hot向量,把cat的ont-hot的向量记作e,刚才得到的向量p是分类器输出的概率分布,我们希望预测接近e,把e和p的crossentropy作为损失函数,用反向传播算出损失函数关于模型参数的梯度,然后做梯度下降来更新模型参数
总结一下
bert会随机遮挡单词,把遮挡的单词作为标签,bert的预训练不需要人工标注的数据集,可以用任何书籍或者维基百科作为训练数据,可以自动生成标签,这样一来训练数据要多少有多少,足以训练出一个非常大的模型。

三、两句话是否原文相邻
刚才讲了第一个任务。预测被遮挡的单词。下面讲第二个任务,预测下一个句子
第一句话是calculus、、、、第二句话是it was、、、、

现在让我们做一个判断,这两句话是否是原文中相邻的两句话,我们觉得是,因为牛顿和莱布尼茨的相关性非常大,神经网络可以从海量训练数据中学习出这种相关性,所以神经网络有能力做出正确的判断,假如第一句话不变,还是

第二句话换成

我们觉得这两句话是否是原文中相邻的两句话呢?我觉得应该不是,第一句话讲的是微积分和数学,第二句话是熊猫,这两句话之间没有任何关联,可以这样准备训练数据,把两句话给拼接起来,两句话之间用SEP符号给分开,在最前面放一个CLS符号占一个位置。

CLS符号是Classification,分类,后面我们具体解释。
生成训练数据的时候,有50%是原文中真实相邻的两句话,另外50%的第二句话,是从训练数据中心随机抽取的

这两句话是真实的原文,所以标签设置维true
第二句话可以是随机选取的句子,这里的第二句话就是随机选取的,所以标签是false

一条训练数据包含两句话,两句话都被分割成很多符号,在最前面放一个CLS符号,占一个位置
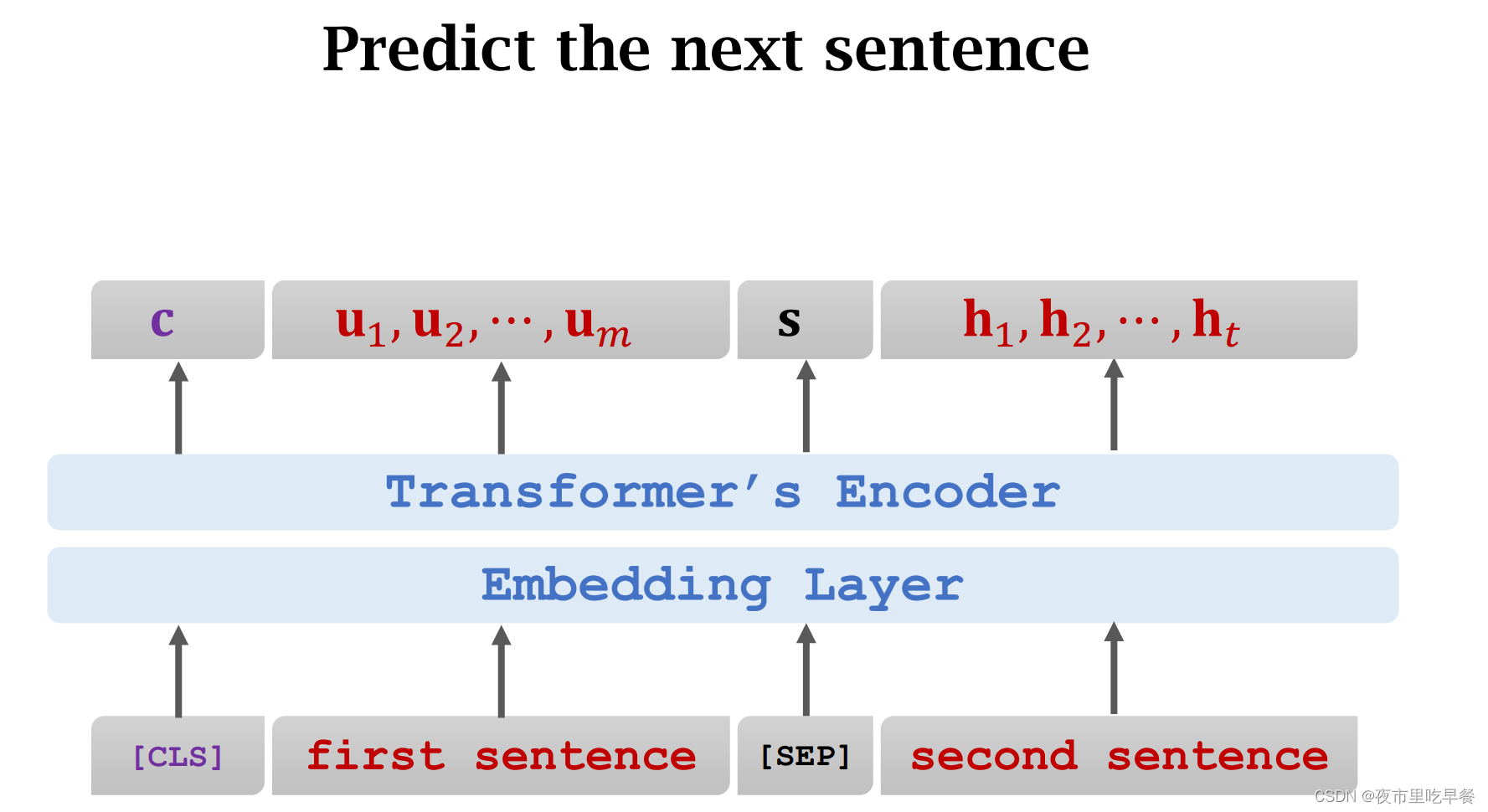
这个位置上的输出记作向量c,我们再强调一下,向量c在CLS的位置上,但是C并不只依赖于CLS符号,向量c包含两句话的全部信息,所以靠c向量就能判断两句话是否真实的相邻,把c作为特征向量输入一个分类器,分类器的输出是介于0-1之间的值f,1代表true,分类器认为这两句话是从原文中拿出来的,0代表FALSE,分类器认为第二句话是假的,两句话不相关,可以用crossentropy来作为损失函数衡量预测f和真实标签之间的区别,有了损失函数就可以计算梯度,然后用梯度下降来更新模型参数,这样做预训练有何意义呢?
相邻两句话通常有关联,这样做二分类可以强化这种关联,让embedding和词向量包含这种关联,比如微积分和牛顿的词向量就应该有某种关联,encoder网络中有self-attention层,self-attention的作用就是找相关性,这种任务就可以使self-attention找到正确的相关性,
四、两者结合起来
前面讲了两个任务,一个是预测遮挡单词,另一个判断两句话是否在原文中真实相连
Bert把两个任务结合起来,用来预训练Transformer,把两句话被拼接起来,然后随机遮挡百分之十五的单词,

这条训练数据,碰巧有两个被遮挡的单词,一共有三个任务,第一个任务是判断两句话是否真的相邻,我知道这两句话是从原文中取出来的,所以标签设置为True,另外两个任务是预测被遮挡的单词,标签是真实的单词,branch和was

这条训练数据中碰巧有一个被遮挡的单词,所以一共有两个任务,我们知道第二句话是随机抽样得到的,所以标签设置为FALSE,被遮挡的单词是south,所以标签是单词south,假如有两个单词被遮挡,那么就有三个任务,就需要定义三个损失函数,
第一个任务是二分裂,所以第一个损失函数是binary

第二三任务是预测单词,这个是多分类任务。
目标函数是三个损失函数的加和,把目标函数关于模型参数求梯度,然后做梯度下降来更新模型参数,bert的好处不需要人工标注数据
人工标注数据非常昂贵,bert两种任务的标签都是自动生成的,这个是非常的性质,可以用书或者论文或者网页等等来做预训练,反正标签都是自动生成的,无需人工标注,bert论文里用了英文维基百科,长度是25亿个单词
五、总结
回顾一下,bert有两个任务,第一个任务是单词预测,随机遮挡百分之十五的单词,第二个任务是判断两句话是否在原文中真实相邻,百分之五十的句子是真实的原文贴上true标签,百分之五十是随机选择的,贴上FALSE标签,
Bert的想法简单,而且非常有效,但是计算代价超级大
论文中有两种模型,小模型有一点一亿个参数,大模型更大,有2.35亿个参数,训练小模型用16块tpu,花费了4天时间,这个只是跑了一遍的时间,还不包括调参数,要是调参数的话时间还要多很多倍,训练大模型,要大四倍,更加夸张。
只有大公司才能玩的起bert。普通学生不可能有资源跑bert,不过好在,他们训练出来的模型参数都是公开的,你想用Transformer的话,直接下载Bert的预训练的模型和参数就好。
Bert可以利用海量数据,来训练一个超级大的模型
这节课我们主要解释了主要原理,但是我们没有讲bert的基础细节,bert的embedding层并不是简单地word-embedding,其中还有一些技巧,随机遮挡单词的时候也有一些技巧,我们并没有对他们进行细节讲解,等我们用到bert的时候,我们可以去看原论文和源代码,我们已经了解了基本原理,阅读论文来说并不困难。
六、参考链接
ShusenWang的个人空间_哔哩哔哩_bilibili