一、Where does the error come from?[error due to bias and variance]
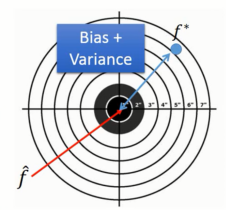
我们将寻找function看作是在打靶,靶的正中心为 f ^ \hat{f} f^,每次collect data训练出来的 f ∗ f^{*} f∗为打在靶上面的点
Variance取决于model的复杂程度和data的数量,而bias只取决于model的复杂成度
 一个较为简单的model,都是有比较小的Variance和比较大的bias,相当于 f ∗ f^{*} f∗相对集中,但是他们平均起来距离 f ^ \hat{f} f^较远。
一个较为简单的model,都是有比较小的Variance和比较大的bias,相当于 f ∗ f^{*} f∗相对集中,但是他们平均起来距离 f ^ \hat{f} f^较远。
一个复杂的model,都有着比较大的Variance和比较小的bias,相当于 f ∗ f^{*} f∗相对分布的比较分散,但是他们平均起来距离 f ^ \hat{f} f^较近
 若实际中error主要来源于variance很大,此时为overfitting
若实际中error主要来源于variance很大,此时为overfitting
若实际中error主要来源于bias很大,此时为underfitting
Notes:如何判断bias大和variance大呢?
1、如果model无法fit training data的examples(training data上面的error较大),此时bais较大,为underfitting。
2、如果model可以fit training data,但是在testing data上面得到很大的error,此时variance较大,为overfitting。
二、How to solve?
1、当我们遇到bias比较大时:
 如果bias较大,则代表现在的model中根本就没有包含target, f ^ \hat{f} f^根本就不存在我们的function set中(model不好),所以此时我们就算再collect more data都毫无意义
如果bias较大,则代表现在的model中根本就没有包含target, f ^ \hat{f} f^根本就不存在我们的function set中(model不好),所以此时我们就算再collect more data都毫无意义
解决方案:redsign,重新对model进行设计(增加更多的feature作为model的input或者让model变得更加复杂)
2、当我们遇到Variance较大时:
 解决的方案:
解决的方案:
1、collect more datas(这是一个非常有效的手段,因为这个不会伤害我们的bias)
但是在很多情况下,我们是无法收集更多的数据,此时可以使用一些手段,generate更多“假“datas
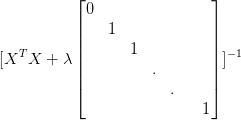
2、Regularization(正则化)

1、蓝色区域为刚开始的情况,model较复杂function set的空间较大(包括了target)因为data不多,variance较大, f ∗ f^{*} f∗较分散。
2、红色的区域为regularization之后,此时function set 的space减小,variance减小,但是在这一缩小的过程中,space也未必能包括target,因此这时候bias还是有可能增大的
通过可视化regularization的过程我们可以发现,我们需要在减小variance的同时,让它包括target,要做到bias和variance相平衡。
三、Model Selection(public set上的error才能真正反映在private set 上的error)

我们可以将training data分成training set和validation set(验证集),先在training set上找出每个model最好的function f ∗ f^{*} f∗,然后用validation set上的data去choose model。得到public set上的error时(可能会很大),不建议回过头去重新调整model的参数。(如果这么做就会把public set的bias也一起考虑进去了)
 若少去根据public training set上的error去调整model这个过程的话,在private testing set上得到的error往往是很接近public testing set 的error。
若少去根据public training set上的error去调整model这个过程的话,在private testing set上得到的error往往是很接近public testing set 的error。
四、conclusion
1、⼀般来说,error是bias和variance共同作用的结果
2、model比较简单和比较复杂的情况:
当model比较简单的时候,variance比较小,bias比较大,此时会比较集中,但是function set可能并没有包含真实值 ;此时model受bias影响较大当model比较复杂的时候,bias比较小,variance比较大,此时function set会包含真实值 ,但是会比较分散;此时model受variance影响较大
3、区分bias大 or variance大的情况:
如果连采样的样本点都没有大部分在model训练出来的上,说明这个model太简单,bias比较大,是欠拟合。如果样本点基本都在model训练出来的上,但是testing data上测试得到的error很大,说明这个model太复杂,variance比较大,是过拟合
4、bias大 or variance大的情况下该如何处理:
当bias比较大时,需要做的是重新设计model,包括考虑添加新的input变量,考虑给model添加高次项;然后对每⼀个model对应的 计算出error,选择error值最小的model(随model变复杂,bias会减小,variance会增加,因此这里分别计算error,取两者平衡点) 当variance比较大时,⼀个很好的办法是增加data(可以凭借经验自己generate data),当data数量足够时,得到的实际上是比较集中的;如果现实中没有办法collect更多的data,那么就采用regularization正规化的方法,以曲线的平滑度为条件控制function set的范围,用weight控制平滑度阈值,使得最终的model既包含 f ^ \hat{f} f^ ,variance又不会太大
5、如何选择model
选择model的时候呢,我们手头上的testing data与真实的testing data之间是存在偏差的,因此我 们要将training data分成training set和validation set两部分,经过validation挑选出来的model再用全部的training data训练⼀遍参数,最后⽤testing data去测试error,这样得到的error是模拟 过testing bias的error,与实际情况下的error会⽐较符合
★ Gradient Desent算法:
一、概念
在Gradient Desent中:梯度不一定是递减的,但总沿着梯度下降的方向,LOSS一定在减小,当gradient=0时,LOSS下降到局部最小值。

θ ∗ = arg min θ L ( θ ) \theta^{*}=\arg \min _{\theta} L(\theta) θ∗=argminθL(θ) [L: loss function θ \theta θ: paramers] (上表为第几组,下标为这组参数的第几个)
Suppose that θ \theta θ has two variables { θ 1 , θ 2 } \left\{\theta_{1}, \theta_{2}\right\} {θ1,θ2}(假设 θ \theta θ是参数的集合)
Randomly start at θ 0 = [ θ 1 0 θ 2 0 ] \theta^{0}=\left[\begin{array}{l}\theta_{1}^{0} \\ \theta_{2}^{0}\end{array}\right] θ0=[θ10θ20] (随机选取一组参数)
gradient: ∇ L ( θ ) = [ ∂ L ( θ 1 ) / ∂ θ 1 ∂ L ( θ 2 ) / ∂ θ 2 ] \nabla L(\theta)=\left[\begin{array}{l}\partial L\left(\theta_{1}\right) / \partial \theta_{1} \\ \partial L_{\left(\theta_{2}\right)} / \partial \theta_{2}\end{array}\right] ∇L(θ)=[∂L(θ1)/∂θ1∂L(θ2)/∂θ2]
[ θ 1 1 θ 2 1 ] = [ θ 1 0 θ 2 0 ] − h [ ∂ L 1 θ 1 0 ) / ∂ θ 1 ∂ L 1 θ 2 0 ) / ∂ θ 2 ] \left[\begin{array}{l}\theta_{1}^{1} \\ \theta_{2}^{1}\end{array}\right]=\left[\begin{array}{l}\theta_{1}^{0} \\ \theta_{2}^{0}\end{array}\right]-h\left[\begin{array}{l} \left.\partial L_{1} \theta_{1}^{0}\right) / \partial \theta_{1} \\ \left.\partial L_{1} \theta_{2}^{0}\right) / \partial \theta_{2}\end{array}\right] [θ11θ21]=[θ10θ20]−h[∂L1θ10)/∂θ1∂L1θ20)/∂θ2]
[ θ 1 2 θ 2 2 ] = [ θ 1 1 θ 2 1 ] − η [ ∂ L ( θ 1 1 ) / ∂ θ 1 ∂ L ( θ 2 1 ) / ∂ θ 2 ] \left[\begin{array}{c}\theta_{1}^{2} \\ \theta_{2}^{2}\end{array}\right]=\left[\begin{array}{c}\theta_{1}^{1} \\ \theta_{2}^{1}\end{array}\right]-\eta\left[\begin{array}{l}\partial L\left(\theta_{1}^{1}\right) / \partial \theta_{1} \\ \partial L\left(\theta_{2}^{1}\right) / \partial \theta_{2}\end{array}\right] [θ12θ22]=[θ11θ21]−η[∂L(θ11)/∂θ1∂L(θ21)/∂θ2]
二、Learning Rate存在的一些问题

gradient descent过程中,影响结果的一个很关键的因素就是learning rate的大小
1、如果learning rate刚刚好,就可以像上图中红色线段一样顺利地到达到loss的最小值
2、如果learning rate太小的话,像下图中的蓝色线段,虽然最后能够走到local minimal的地方,但是它可能会走的非常慢,以至于你无法接受
3、如果learning rate太大,像下图中的绿色线段,它的步伐太大了,它永远没有办法走到特别低的地方,可能永远在这个“山谷”的口上振荡而无法走下去
4、如果learning rate非常大,就会像下图中的黄色线段,一瞬间就飞出去了,结果会造成update参数以后,loss反而会越来越大。
面对这个问题,我们需要在不同learning rate下,把loss随着update的次数的变化可视化,根据可视化图像,对learning rate进行调整,找到最合适的learning rate。
三、Adagrad Learning Rates(Adagrad算法)
基本原则:Learning rate通常随着参数的update越来越小。


四、Stochastic Gradient Desent(随机梯度下降算法)
五、Feature Scaling(特征缩放)

六、Gradient Descent的限制

综上,gradient descent的限制是,它在gradient即微分值接近于0的地方就会停下来,而这个地方不一定是global minima,它可能是local minima,可能是saddle point鞍点,甚⾄可能是⼀个loss很高的plateau平缓高原
















![[JAVA实现]微信公众号网页授权登录,java开发面试笔试题](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)