下面以sklearn的KNeighbors模型举例:
1.对于分类(Classifier)模型,score函数计算的是精确度。底层是accuracy_score
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.RadiusNeighborsClassifier.html#sklearn.neighbors.RadiusNeighborsClassifier.score

def score(self, X, y, sample_weight=None):"""Returns the mean accuracy on the given test data and labels.In multi-label classification, this is the subset accuracywhich is a harsh metric since you require for each sample thateach label set be correctly predicted.Parameters----------X : array-like, shape = (n_samples, n_features)Test samples.y : array-like, shape = (n_samples) or (n_samples, n_outputs)True labels for X.sample_weight : array-like, shape = [n_samples], optionalSample weights.Returns-------score : floatMean accuracy of self.predict(X) wrt. y."""from .metrics import accuracy_scorereturn accuracy_score(y, self.predict(X), sample_weight=sample_weight)
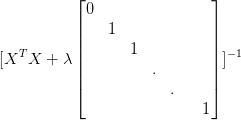
2.对于回归(Regressor)问题,score函数计算的是R^2分数。底层是r2_score
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html#sklearn.neighbors.KNeighborsRegressor.score

def score(self, X, y, sample_weight=None):"""Returns the coefficient of determination R^2 of the prediction.The coefficient R^2 is defined as (1 - u/v), where u is the residualsum of squares ((y_true - y_pred) ** 2).sum() and v is the totalsum of squares ((y_true - y_true.mean()) ** 2).sum().The best possible score is 1.0 and it can be negative (because themodel can be arbitrarily worse). A constant model that alwayspredicts the expected value of y, disregarding the input features,would get a R^2 score of 0.0.Parameters----------X : array-like, shape = (n_samples, n_features)Test samples.y : array-like, shape = (n_samples) or (n_samples, n_outputs)True values for X.sample_weight : array-like, shape = [n_samples], optionalSample weights.Returns-------score : floatR^2 of self.predict(X) wrt. y."""from .metrics import r2_scorereturn r2_score(y, self.predict(X), sample_weight=sample_weight,multioutput='variance_weighted')















![[JAVA实现]微信公众号网页授权登录,java开发面试笔试题](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)