数据库系统-数据库设计
数据库设计概述及六步骤简介
数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据,满足各种用户的应用需求。
数据库设计的特点
数据库设计是一项涉及多学科的综合性技术,又是一项庞大的工程项目,具有如下特点:
- 数据库建设是硬件、软件和干件(技术和管理的界面)的结合
- 数据库设计应该和应用系统设计相结合
数据库设计方法
常用的数据库设计方法如下:
- 新奥尔良方法:将数据库设计分为若干阶段和步骤
- 基于E-R模型的设计方法:概念设计阶段广泛采用
- 基于3NF的设计方法:逻辑阶段可采用的有效方法
- ODL(Object Definition Language)方法:面向对象的数据库设计方法
- 计算机辅助设计:ORACLE Designer 2000、SYBASE PowerDesigner
数据库设计的基本步骤
数据库设计分为6个阶段:
- 需求分析:准确了解与分析用户需求(包括数据与处理)
- 概念结构设计:对用户需求进行综合、归纳与抽象,形成一个独立与具体DBMS的概念模型
- 逻辑结构设计:将概念结构转换为某个DMBS所支持的数据模型,并对其进行优化
- 物理结构设计:为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)
- 数据库实施:建立数据库,编制与调试应用程序,组织数据入库,并进行试运行
- 数据库运行和维护:对数据库系统进行评论、调整与修改
需求分析-步骤一
需求分析是整个数据库设计过程中最重要的步骤之一,是后继各阶段的基础。在需求分析阶段,从多方面对整个组织进行调查,收集和分析各项应用对信息和处理两方面的需求。
-
收集资料
收集资料是数据库设计人员和用户共同完成的任务。确定企业组织的目标,从这些目标导出对数据库的总体要求。通过调研,确定由计算机完成的功能。
-
分析整理
分析的过程是对所收集到的数据进行抽象的过程,产生求解的模型。
-
数据流图
采用数据流图来描述系统的功能。数据流图可以形象地描述事务处理与所需数据的关联,便于用结构化系统方法,自顶向下,逐层分解,步步细化。
-
数据字典
对数据流图中的数据流和加工等进一步定义,从而完整地反映系统需求。
数据字典的用途:进行详细的数据收集和数据分析所获得的主要结果。
数据字典的内容:数据项、数据结构、数据流、数据存储、处理过程
-
用户确认
需求分析得到的数据流图和数据字典要返回给用户,通过反复完善,最终取得用户的认可
概念结构设计-步骤二
概念设计阶段的目标是产生整体数据库概念结构,即概念模式。概念模式是整个组织各个用户关心的信息结构。描述概念结构的有力工具是 E-R模型
实体型
用矩形表示,矩形框内写明实体名
属性
用椭圆形表示,并用无向边将其与相应的实体连接起来
联系
用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时这无向边旁标上联系的类型(1:1、1:n或m:n)
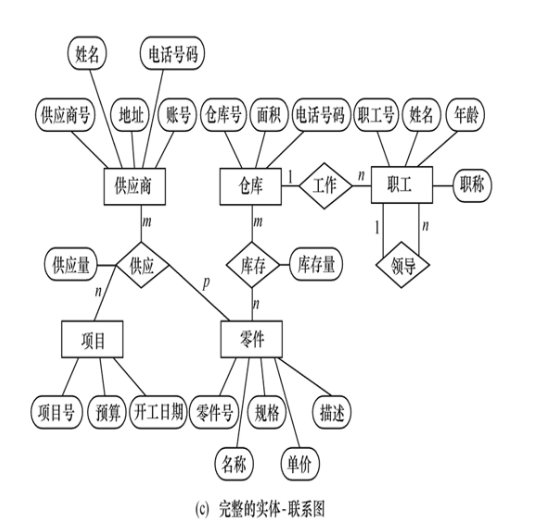
建立E-R模型步骤
-
设计局部E-R模型
确定局部结构范围
定义实体
联系定义
属性分配
-
设计全局E-R模型
确定公共实体类型
局部E-R模型的合并
消除冲突
-
全局E-R模型的优化
实体类型的合并
冗余属性的消除
冗余联系的消除
逻辑结构设计-步骤三
逻辑结构设计就是把上述概念模型转换成为某个具体的数据库管理系统所支持的数据模型
E-R模型向关系模式的转换
E-R模型向关系模式的转换转换原则:
-
每一个实体类型转换为一个关系模式,实体的属性就是关系的属性,实体的码就是关系的码
-
联系的转换
一般1:1,1:m联系不产生新的关系模式,而是将一方实体的码加入多方实体对应的关系模式中,联系的属性也一并加入
m:n联系要产生一个新的关系模式,改关系模式由联系涉及实体的码加上联系的属性(若有)组成
两实体之间的1:1联系
一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。如果转换一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,每个实体的码均是该关系的候选码。如果与某一端实体对应的关系模式合并,则需要这该关系模式的属性中加入另一个关系模式的码和联系本身的属性。可将任一方实体的主码纳入另一方实体对应的关系中,若有联系的属性也一并纳入。
例如:
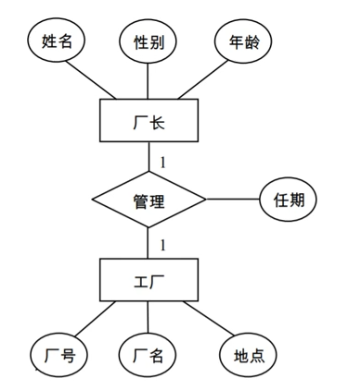
关系模式:
工厂(厂号,厂名,地点)
厂长(姓名,性别,年龄,厂号,任期)
两实体间的1:m联系
可将“1”方实体的主码纳入“m”方实体对应的关系中作为外码,同时把联系的属性也一并纳入“m”方对应的关系中
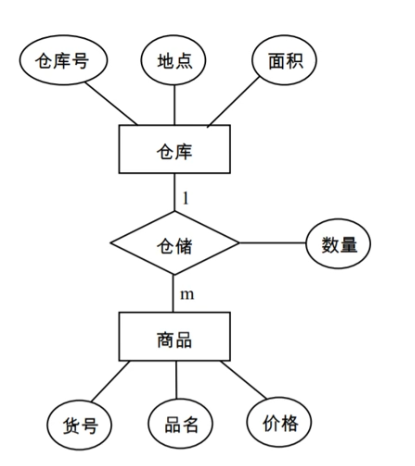
关系模式:
仓库(仓库号,地点,面积)
商品(货号,品名,价格,仓库号,数量)
同一实体间的1:m联系
可在这个实体所对应的关系中多设一个属性,作为域该实体相联系的另一个实体的主码。
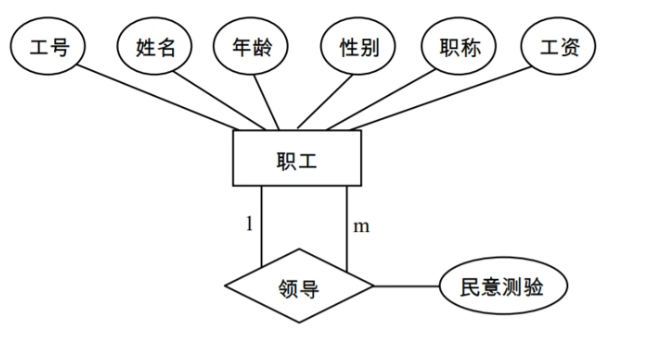
关系模式:
职工(工号,姓名,年龄,性别,职称,工资,领导者工号,民意测验)
两实体间的弱实体联系
可将被依赖实体的主码纳入弱实体中,作为弱实体的主码或主码中的一部分
在现实世界中,常常有某些实体对于另一些实体具有很强的依赖关系,即一个实体的存在必须以另一个实体的存在为前提。通常把前者称为弱实体。
在E-R图中,用双线框表示弱实体,用指向弱实体的箭头表明依赖联系。
例如,如图所示的E-R图可转换为如下关系模式:
例如,如图所示的E-R图可转换为如下关系模式:
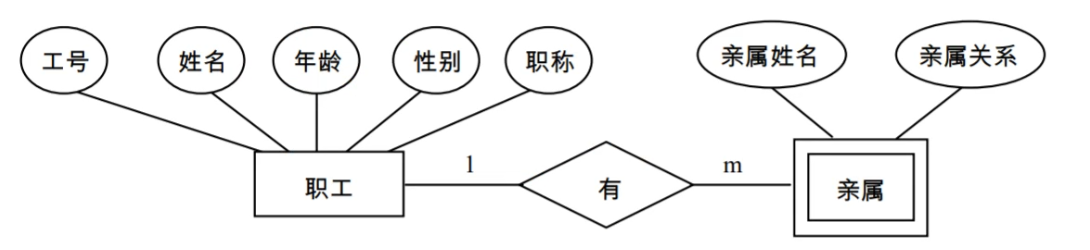
关系模式:
职工(工号,姓名,年龄,性别,职称)
亲属(工号,亲戚姓名,亲戚关系)
超类和子类的转换
概括定义了类型之间的一种子集联系。
例如:学生是一个实体型,本科生、研究生也是实体型。本科生、研究生均是学生的子集。把学生称为超类,本科生、研究生称为学生的子类。
在E-R图中,用双竖边的矩形框表示子类,用直线加小圆圈表示超类-子类联系。子类继承超类上定义的全部属性,其本身还可包含其他属性。
例如,如图所示的E-R图中各个实体的属性为:
职员:职工号,姓名,性别,年龄,参加工作时间
飞行员:飞行小时,健康检查,飞机型号
机械师:学历,级别,专业职称
管理员:职务,职称
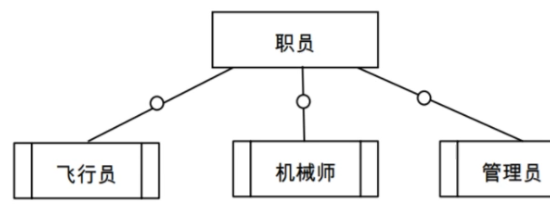
改E-R图转换为关系模式为:
职员(职工号,姓名,性别,年龄,参加工作时间)
飞行员(职工号,飞行小时,健康检查,飞机型号)
机械师(职工号,学历,级别,专业职称)
管理员(职工号,职务,职称)
为了查询方便,可这超类实体中增加一个指示器属性,根据指示器的值直接查询子类实体表。所以,职员关系又可以为:
职员(职工号,姓名,性别,年龄,参加工作时间,职员类型)
两实体间的m:n联系
必须对“联系”单独建立一个关系,该关系中至少包含被它所联系的双方实体的“主码”,如果联系用属性,也要纳入这个关系中。
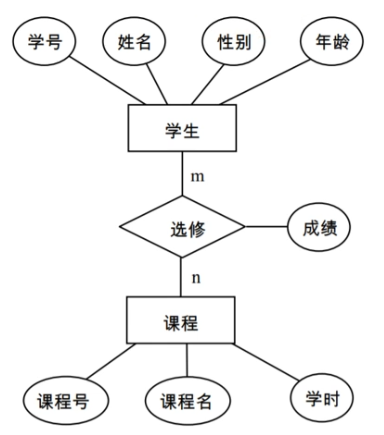
关系模式:
学生(学号,姓名,性别,年龄)
课程(课程号,课程名,学时)
选修(学号,课程号,成绩)
同一实体间的m:n联系
必须为这个“联系”单独建立一个关系,该关系中至少包含被它所联系的双方实体的“主码”,如果联系用属性,也要纳入这个关系中,由于这个“联系”只涉及一个实体,所以加入的实体的主码不能同名。
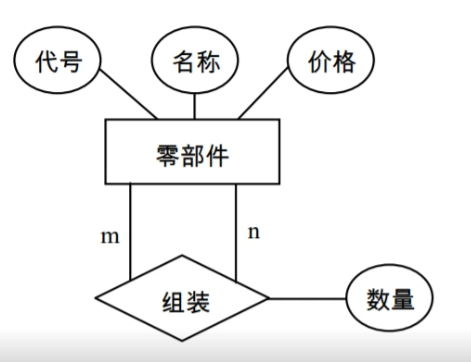
关系模式:
零部件(代号,名称,价格)
组装(代号,组装件代号,数量)
两个以上实体间的m:n联系
必须为这个“联系”单独建立一个关系,该关系中至少包含被它所联系的各个实体的“主码”,若是联系有属性,也要纳入这个关系中
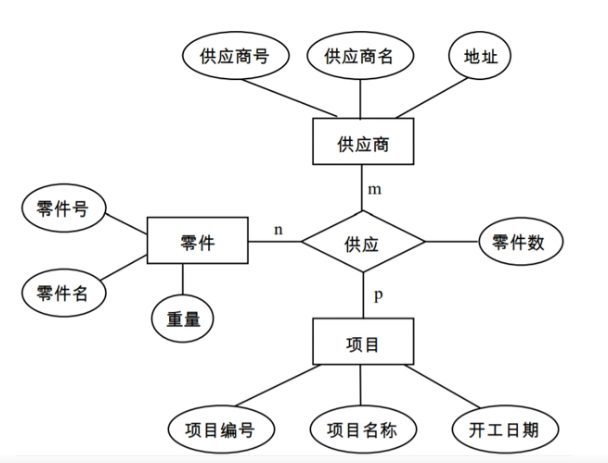
关系模式:
供应商(供应商号,供应商名,地址)
零件(零件号,零件名,重量)
项目(项目编号,项目名称,开工日期)
供应(供应商号,项目编号,零件号,零件数)
关系模式优化
最核心的就是要遵循数据库设计的NF范式
应用关系规范化理论对上述产生的关系模式进行优化,具体步骤如下:
- 确定每个关系模式内部各个属性之间的数据依赖以及不同关系模式属性之间的数据依赖
- 对各个关系模式之间的数据依赖进行最小化处理,消除冗余的联系
- 确定各关系模式的范式等级
- 按照需求分析阶段得到的处理要求,确定要对哪些模式进行合并或分解
- 为了提高数据操作的效率和存储空间的利用率,对上述产生的关系模式进行适当的修改、调整和重构
设计用户子模式
全局关系模型设计完成后,还应根据局部应用的需求,结合具体DBMS的特点,设计用户的子模式
设计子模式时应注意考虑用户的习惯和方便性,主要包括:
- 使用更符合用户习惯的别名
- 可以为不同级别的用户定义不同的视图,以保证系统的安全性
- 可将经常使用的复杂的查询定义为视图,简化用户对系统的使用
物理结构设计-步骤四
数据库的物理设计是指对一个给定的逻辑数据库模型选取一个最适合应用环境的物理结构的过程。物理设计通常分为两步:
第一步 确定数据库的物理结构
- 确定数据的存取方法、索引方法的选择、聚簇方法的选择
- 确定数据的存储结构
确定数据的存放位置 基本原则:根据应用情况将易变部分与稳定部分分开存放、存取频率较高部分与存取频率较低部分分开存放
确定系统配置
DBMS产品一般都提供了一些存储分配参数
同时使用数据库的用户数
同时打开的数据库对象数
内存分配参数
使用的缓冲区长度、个数
存储分配参数
第二步 物理结构进行评价
对时间效率、空间效率、维护开销和各种用户要求进行权衡,从多种设计方案中选择一个较优的方案。
评价方法(完全依赖于所选用的DBMS)
定量估算各种方案
存储空间
存取时间
维护代价
对估算结果进行权衡、比较,选择出一个较优的合理的物理结构
如果该结构不符合用户需求,则需要修改设计
数据库实施-步骤五
实施阶段的工作主要有:
-
建立数据库结构
-
数据载入
数据库结构建立好后,就可以向数据库中装载数据了。组织数据入库是数据库实施阶段最主要的工作。
-
应用程序的编码和调试
-
数据库试运行
-
功能测试
实际运行数据库应用程序,执行对数据库的各种操作,测试应用程序的功能是否满足设计要求如果不满足,对应用程序部分则要修改、调整,直到达到设计要求。
-
性能测试
测量系统的性能指标,分析是否达到设计目标。
如果测试的结果与设计目标不符,则要返回物理设计阶段,重新调整物理结构,修改系统参数,某些情况下甚至要返回逻辑设计阶段,修改逻辑结构。
-
数据库运行维护-步骤六
数据库系统投入正式运行后,对数据库经常性的维护工作主要由DBA完成,包括:
-
数据库的转储和恢复
这数据库试运行阶段,系统还不稳定,硬、软件故障随时都可能发生。
系统的操作人员对新系统还不熟悉,误操作也不可避免因此必须做好数据库的转储和恢复工作,尽量减少对数据库的破坏。
-
数据库的安全性、完整性控制
-
数据库性能的监督、分析和改造
-
数据库的重组与重构
重组的目标:提高系统性能
重组的工作:按原设计要求、重新安排存储位置、回收垃圾、减少指针链、数据库的重组不会改变原设计的数据逻辑结构和物理结构
数据库重构:根据新环境调整数据库的模式和内模式、增加新的数据项、改变数据项的类型、改变数据库的容量、增加或删除索引修改完整性约束条件