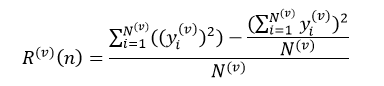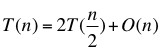目录
一、为什么要剪枝
二、剪枝的策略
1、预剪枝(pre-pruning)
2、后剪枝(post-pruning)
三、代码实现
1、收集、准备数据:
2、分析数据:
3、预剪枝及测试:
4、后剪枝及测试:
四、总结
一、为什么要剪枝
剪枝(pruning)的目的是为了避免决策树模型的过拟合。因为决策树算法在学习的过程中为了尽可能的正确的分类训练样本,不停地对结点进行划分,因此这会导致整棵树的分支过多,也就导致了过拟合。
可通过“剪枝”来一定程度避免因决策分支过多,以致于把训练集 自身的一些特点当做所有数据都具有的一般性质而导致的过拟合。
二、剪枝的策略
决策树的剪枝策略最基本的有两种:预剪枝(pre-pruning)和后剪枝(post-pruning)
1、预剪枝(pre-pruning)
预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
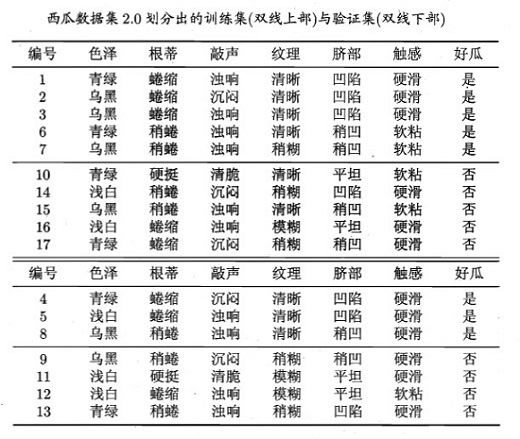
数据集:
预剪枝:
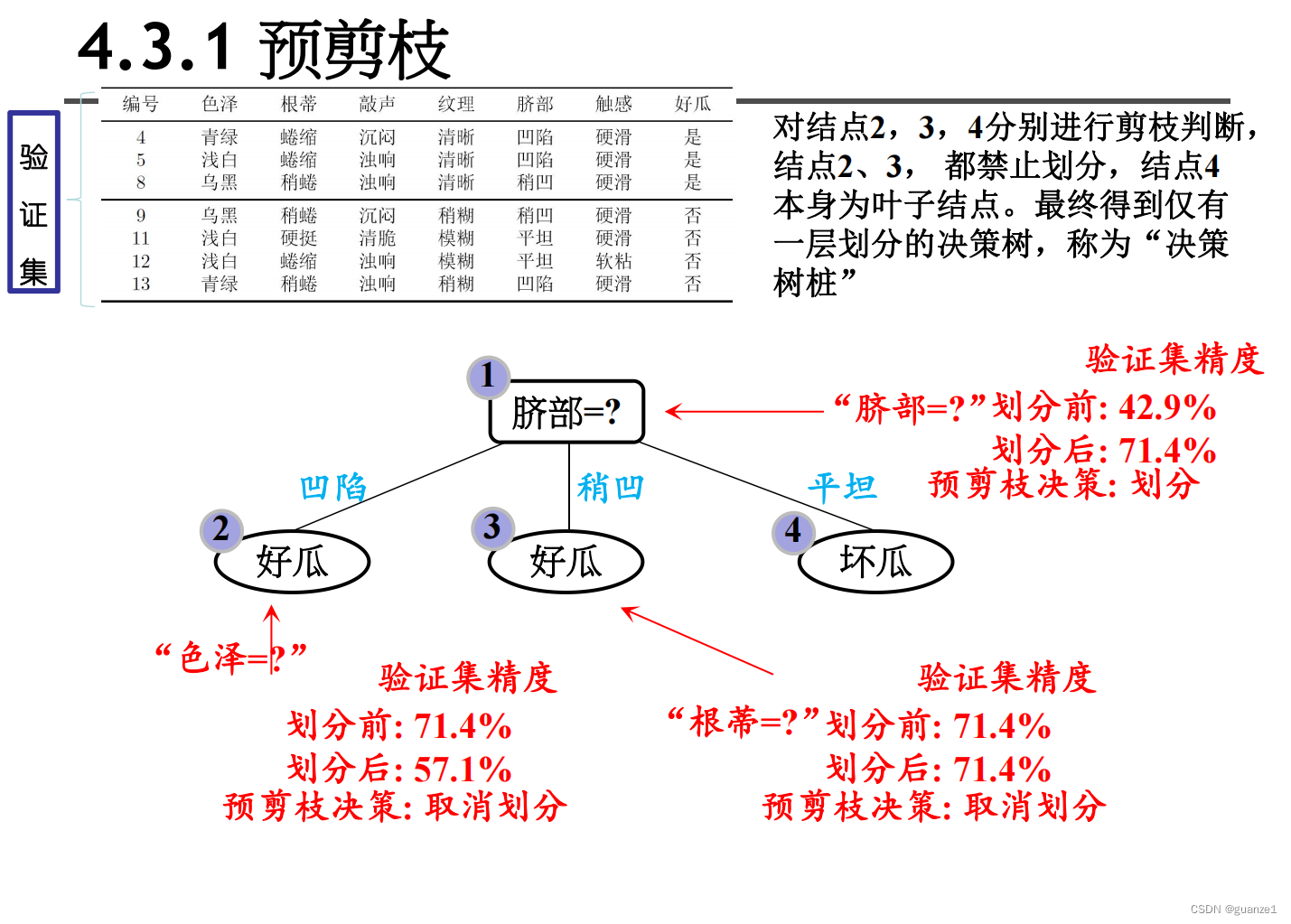
预剪枝的优缺点
•优点
–降低过拟合风险
–显著减少训练时间和测试时间开销。
•缺点
–欠拟合风险 :有些分支的当前划分虽然不能提升泛化性能,但 在其基础上进行的后续划分却有可能显著提高性能。预剪枝基于 “ 贪心 ”本质禁止这些分支展开,带来了欠拟合风险。
2、后剪枝(post-pruning)
后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。
后剪枝处理:
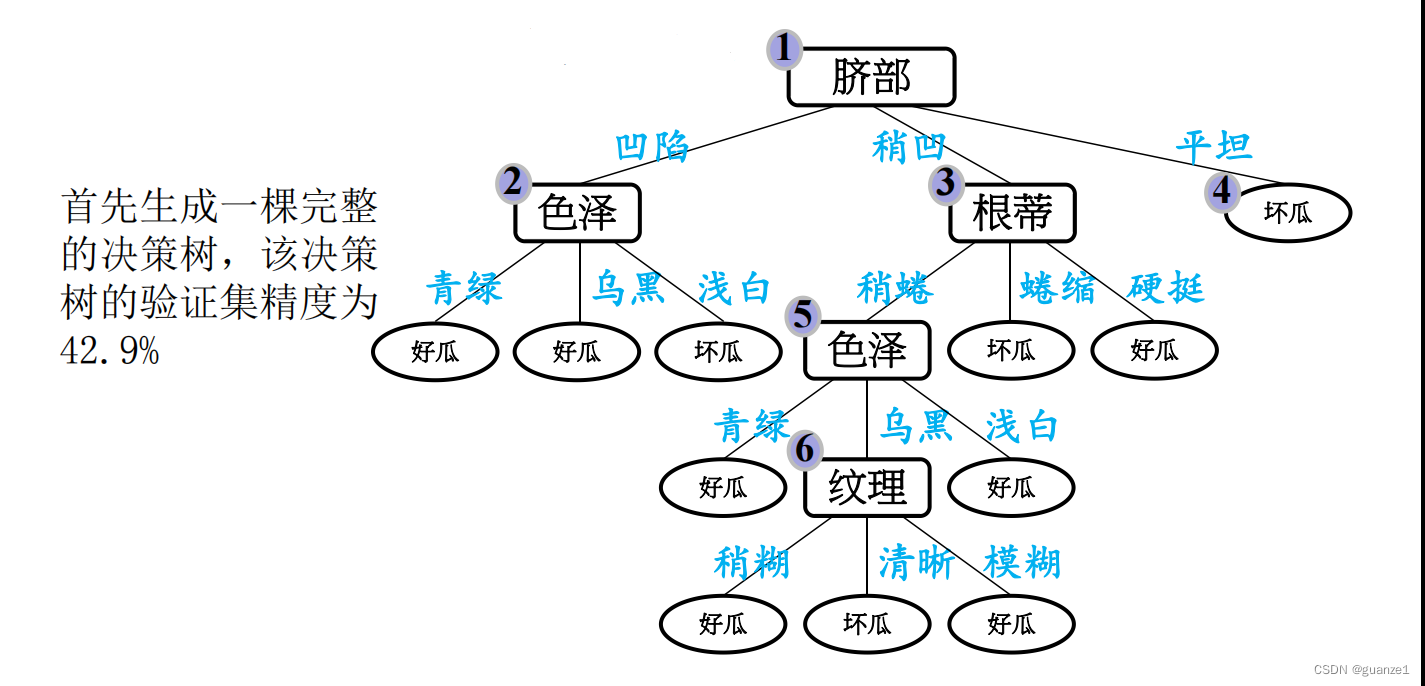
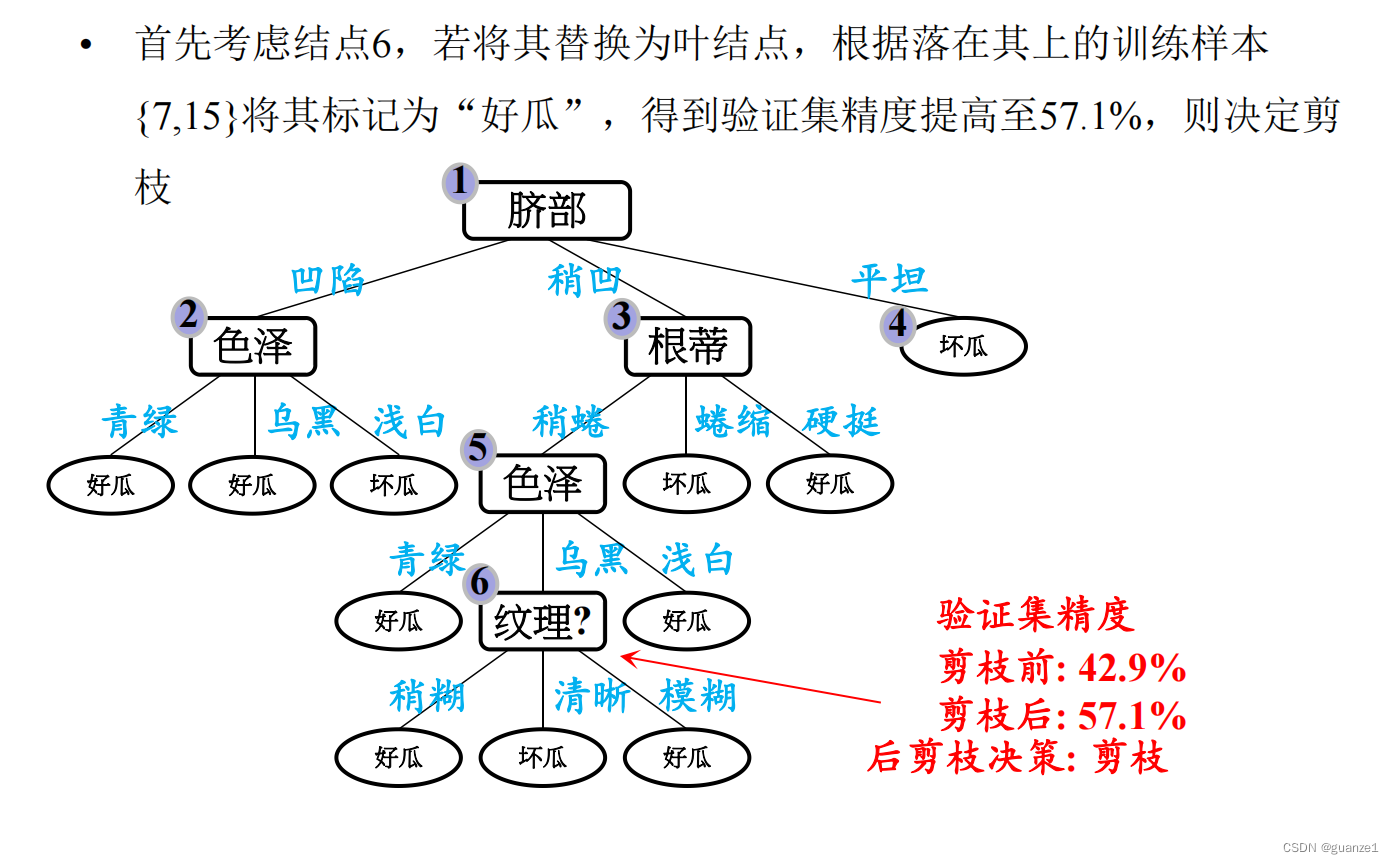
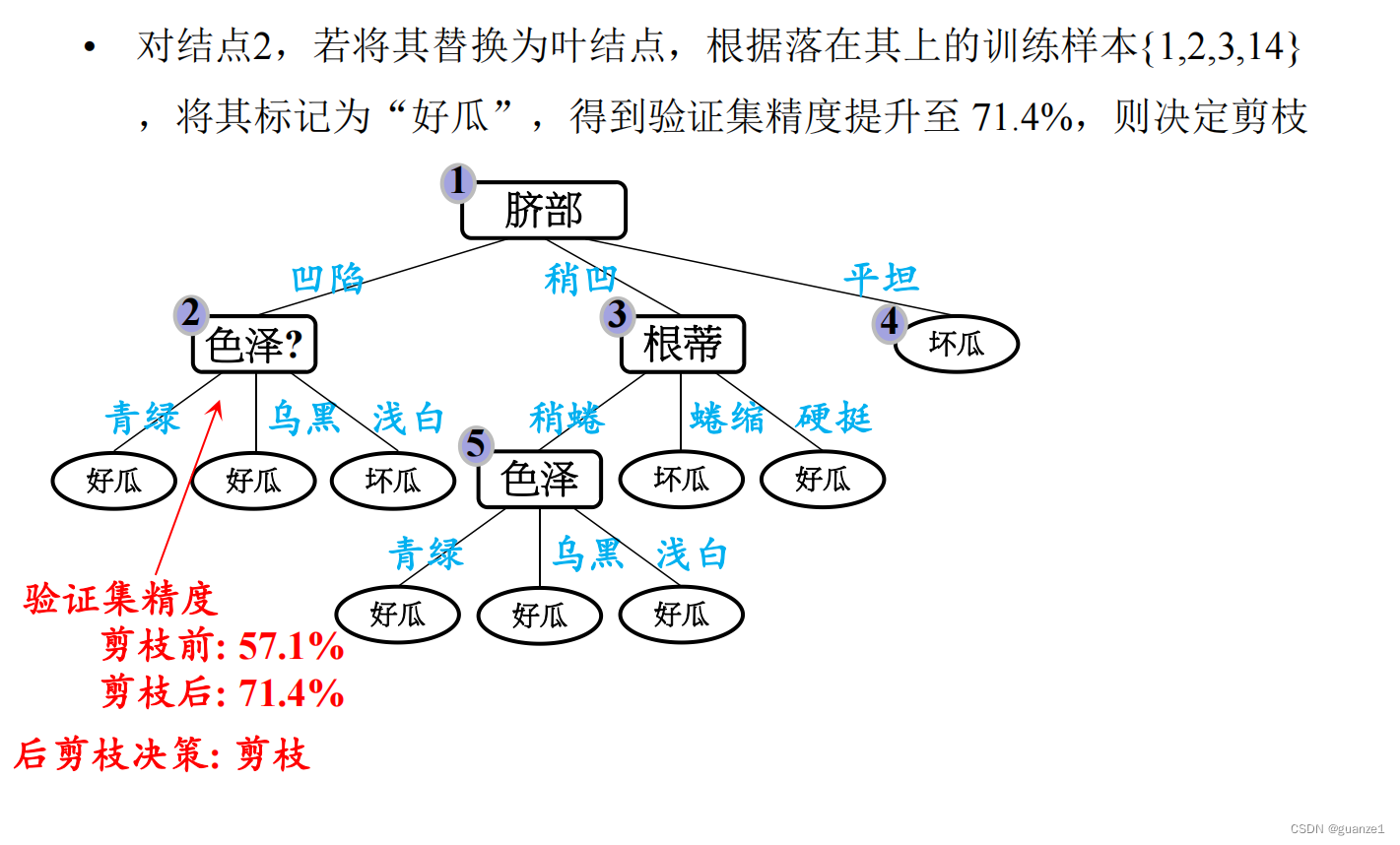
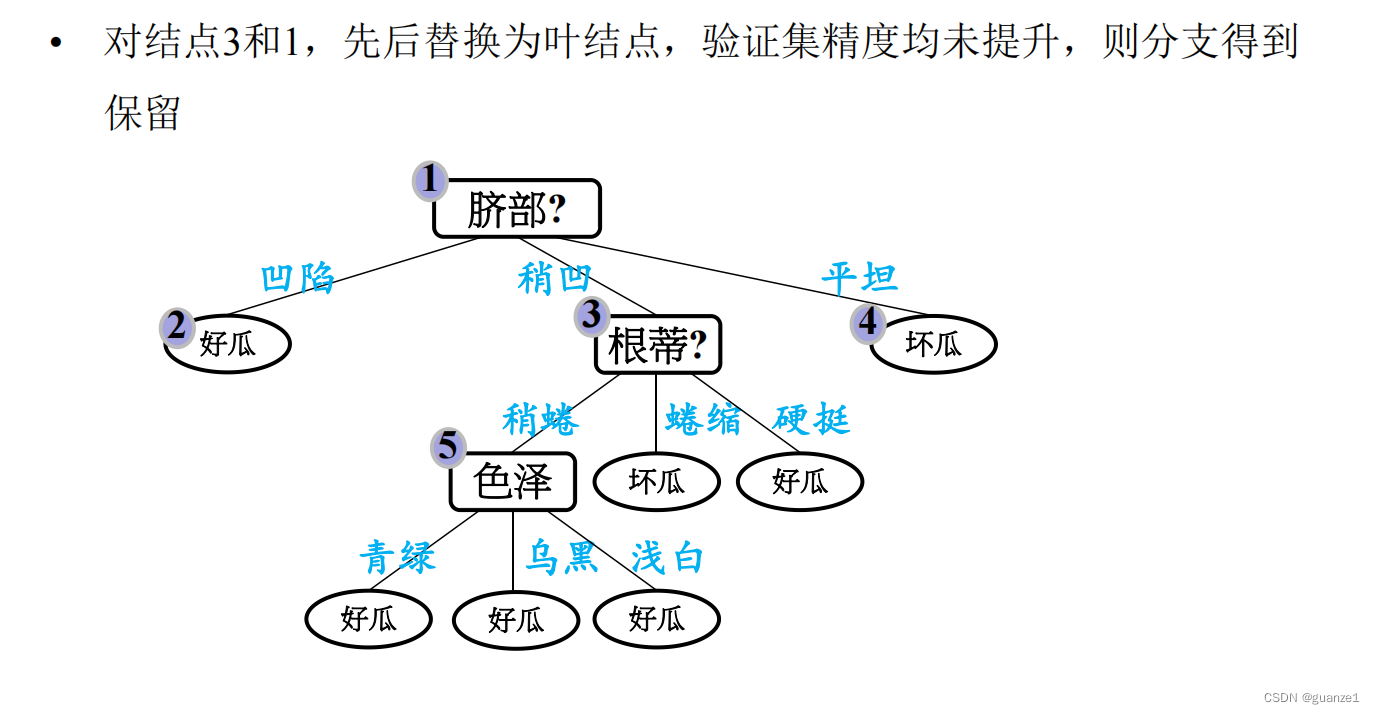
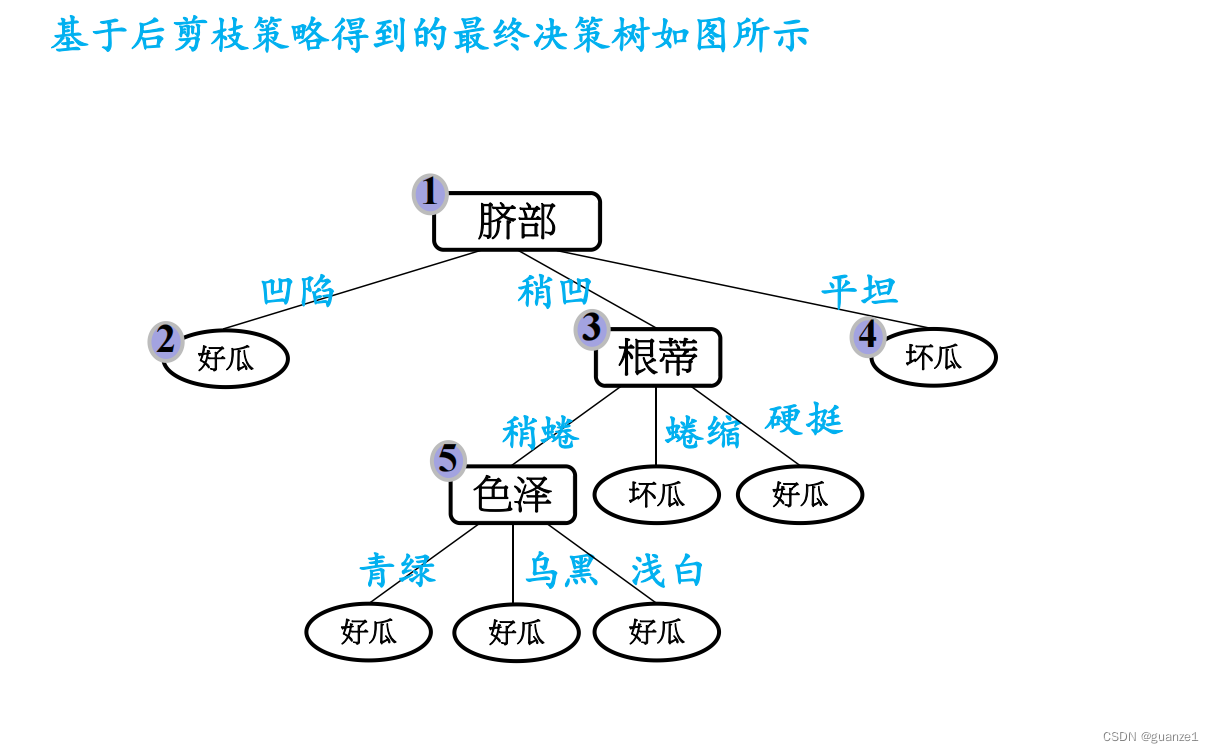
后剪枝的优缺点
•优点
后剪枝比预剪枝保留了更多的分支, 欠拟合风险小 , 泛化性能往往优于预剪枝决策树
•缺点
训练时间开销大 :后剪枝过程是在生成完全决策树 之后进行的,需要自底向上对所有非叶结点逐一计算
三、代码实现
1、收集、准备数据:
这里采用上面西瓜2.0的数据集:
import math
import numpy as np def createMyData():data = np.array([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'], ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'], ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'], ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'], ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘'], ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑'], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑'], ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘'], ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘'], ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑'], ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑'], ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']])label = np.array(['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否'])name = np.array(['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'])return data, label, namedef splitMyData20(myData, myLabel):myDataTrain = myData[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16],:]myDataTest = myData[[3, 4, 7, 8, 10, 11, 12],:]myLabelTrain = myLabel[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16]]myLabelTest = myLabel[[3, 4, 7, 8, 10, 11, 12]]return myDataTrain, myLabelTrain, myDataTest, myLabelTest
2、分析数据:
equalNums = lambda x,y: 0 if x is None else x[x==y].size# 定义计算信息熵的函数
def singleEntropy(x):x = np.asarray(x)xValues = set(x)entropy = 0for xValue in xValues:p = equalNums(x, xValue) / x.size entropy -= p * math.log(p, 2)return entropy# 定义计算条件信息熵的函数
def conditionnalEntropy(feature, y):feature = np.asarray(feature)y = np.asarray(y)featureValues = set(feature)entropy = 0for feat in featureValues:p = equalNums(feature, feat) / feature.size entropy += p * singleEntropy(y[feature == feat])return entropy# 定义信息增益
def infoGain(feature, y):return singleEntropy(y) - conditionnalEntropy(feature, y)# 定义信息增益率
def infoGainRatio(feature, y):return 0 if singleEntropy(feature) == 0 else infoGain(feature, y) / singleEntropy(feature)# 特征选取
def bestFeature(data, labels, method = 'id3'):assert method in ['id3', 'c45'], "method 须为id3或c45"data = np.asarray(data)labels = np.asarray(labels)# 根据输入的method选取 评估特征的方法:id3 -> 信息增益; c45 -> 信息增益率def calcEnt(feature, labels):if method == 'id3':return infoGain(feature, labels)elif method == 'c45' :return infoGainRatio(feature, labels)featureNum = data.shape[1]bestEnt = 0 bestFeat = -1for feature in range(featureNum):ent = calcEnt(data[:, feature], labels)if ent >= bestEnt:bestEnt = ent bestFeat = featurereturn bestFeat, bestEnt # 根据特征及特征值分割原数据集
def splitFeatureData(data, labels, feature):features = np.asarray(data)[:,feature]data = np.delete(np.asarray(data), feature, axis = 1)labels = np.asarray(labels)uniqFeatures = set(features)dataSet = {}labelSet = {}for feat in uniqFeatures:dataSet[feat] = data[features == feat]labelSet[feat] = labels[features == feat]return dataSet, labelSet# 多数投票
def voteLabel(labels):uniqLabels = list(set(labels))labels = np.asarray(labels)finalLabel = 0labelNum = []for label in uniqLabels:labelNum.append(equalNums(labels, label))return uniqLabels[labelNum.index(max(labelNum))]# 创建决策树
def createTree(data, labels, names, method = 'id3'):data = np.asarray(data)labels = np.asarray(labels)names = np.asarray(names)if len(set(labels)) == 1: return labels[0] elif data.size == 0: return voteLabel(labels)bestFeat, bestEnt = bestFeature(data, labels, method = method)bestFeatName = names[bestFeat]names = np.delete(names, [bestFeat])decisionTree = {bestFeatName: {}}dataSet, labelSet = splitFeatureData(data, labels, bestFeat)for featValue in dataSet.keys():decisionTree[bestFeatName][featValue] = createTree(dataSet.get(featValue), labelSet.get(featValue), names, method)return decisionTree # 统计叶子节点数和树深度
def getTreeSize(decisionTree):nodeName = list(decisionTree.keys())[0]nodeValue = decisionTree[nodeName]leafNum = 0 treeDepth = 0 leafDepth = 0for val in nodeValue.keys():if type(nodeValue[val]) == dict: leafNum += getTreeSize(nodeValue[val])[0] leafDepth = 1 + getTreeSize(nodeValue[val])[1] else :leafNum += 1 leafDepth = 1 treeDepth = max(treeDepth, leafDepth)return leafNum, treeDepth # 使用模型对其他数据分类
def dtClassify(decisionTree, rowData, names):names = list(names)feature = list(decisionTree.keys())[0]featDict = decisionTree[feature]feat = names.index(feature)featVal = rowData[feat]if featVal in featDict.keys():if type(featDict[featVal]) == dict:classLabel = dtClassify(featDict[featVal], rowData, names)else:classLabel = featDict[featVal] return classLabel
使用Matplotlib注解绘制树形图:
import matplotlib.pyplot as plt#定义文本框和箭头格式
decisionNode=dict(boxstyle="sawtooth",fc='0.8')
leafNode=dict(boxstyle="round4",fc='0.8')
arrow_args=dict(arrowstyle="<-")#绘制带箭头的注释
def plotNode(nodeTxt,centerPt,parentPt,nodeType):createPlot.axl.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',xytext=centerPt,textcoords='axes fraction',va="center",ha="center",bbox=nodeType,arrowprops=arrow_args)#获取叶节点的数目和树的层数
def getNumLeafs(myTree):numLeafs=0
# firstStr=myTree.keys()[0]firstStr=list(myTree.keys())[0]secondDict=myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':numLeafs+=getNumLeafs(secondDict[key])else:numLeafs+=1return numLeafsdef getTreeDepth(myTree):maxDepth=0firstStr=list(myTree.keys())[0]secondDict=myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':thisDepth=1+getTreeDepth(secondDict[key])else:thisDepth=1if thisDepth>maxDepth:maxDepth=thisDepthreturn maxDepthdef plotMidText(cntrPt,parentPt,txtString):xMid=(parentPt[0]-cntrPt[0])/2.0+cntrPt[0]yMid=(parentPt[1]-cntrPt[1])/2.0+cntrPt[1]createPlot.axl.text(xMid,yMid,txtString)def plotTree(mytree,parentPt,nodeTxt):numLeafs=getNumLeafs(mytree)depth=getTreeDepth(mytree)firstStr=list(mytree.keys())[0]cntrPt=(plotTree.xOff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff)plotMidText(cntrPt,parentPt,nodeTxt)plotNode(firstStr,cntrPt,parentPt,decisionNode)secondDict=mytree[firstStr]plotTree.yOff=plotTree.yOff-1.0/plotTree.totalDfor key in secondDict.keys():if type(secondDict[key]).__name__=='dict':plotTree(secondDict[key],cntrPt,str(key))else:plotTree.xOff=plotTree.xOff+1.0/plotTree.totalWplotNode(secondDict[key],(plotTree.xOff,plotTree.yOff),cntrPt,leafNode)plotMidText((plotTree.xOff,plotTree.yOff),cntrPt,str(key))plotTree.yOff=plotTree.yOff+1.0/plotTree.totalDdef createPlot(inTree):fig=plt.figure(1,facecolor='white')fig.clf()axprops=dict(xticks=[],yticks=[])createPlot.axl=plt.subplot(111,frameon=False,**axprops)plotTree.totalW=float(getNumLeafs(inTree))plotTree.totalD=float(getTreeDepth(inTree))plotTree.xOff=-0.5/plotTree.totalW;plotTree.yOff=1.0;plotTree(inTree,(0.5,1.0),'')plt.show()3、预剪枝及测试:
# 创建预剪枝决策树
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method = 'id3'):trainData = np.asarray(dataTrain)labelTrain = np.asarray(labelTrain)testData = np.asarray(dataTest)labelTest = np.asarray(labelTest)names = np.asarray(names)if len(set(labelTrain)) == 1: return labelTrain[0] elif trainData.size == 0: return voteLabel(labelTrain)bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method = method)bestFeatName = names[bestFeat]names = np.delete(names, [bestFeat])dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)labelTrainLabelPre = voteLabel(labelTrain)labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.sizeif dataTest is not None: dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.sizelabelTrainEqNumPost = 0for val in labelTrainSet.keys():labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0labelTestRatioPost = labelTrainEqNumPost / labelTest.size if dataTest is None and labelTrainRatioPre == 0.5:decisionTree = {bestFeatName: {}}for featValue in dataTrainSet.keys():decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue), None, None, names, method)elif dataTest is None:return labelTrainLabelPre elif labelTestRatioPost < labelTestRatioPre:return labelTrainLabelPreelse :decisionTree = {bestFeatName: {}}for featValue in dataTrainSet.keys():decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue), dataTestSet.get(featValue), labelTestSet.get(featValue), names, method)return decisionTree myDataTrain, myLabelTrain, myDataTest, myLabelTest = splitMyData20(myData, myLabel)
myTreeTrain = createTree(myDataTrain, myLabelTrain, myName, method = 'id3')
myTreePrePruning = createTreePrePruning(myDataTrain, myLabelTrain, myDataTest, myLabelTest, myName, method = 'id3')
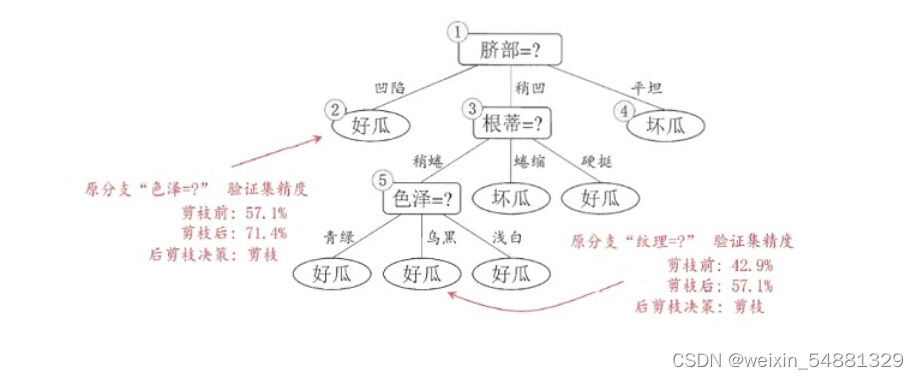
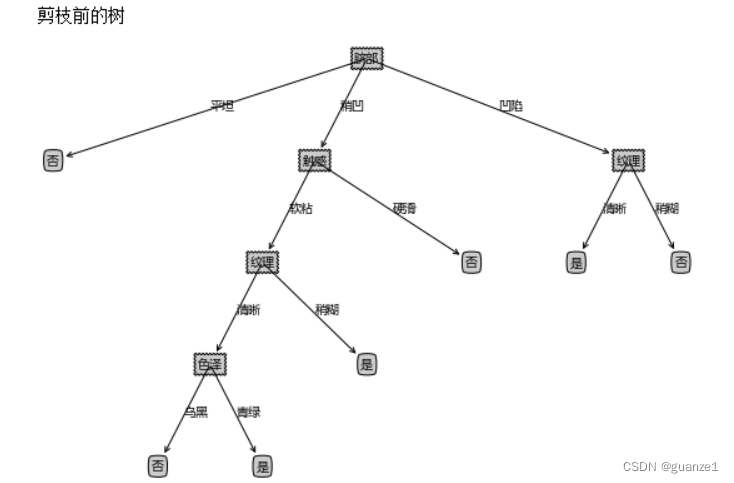
# 画剪枝前的树
print("剪枝前的树")
createPlot(myTreeTrain)
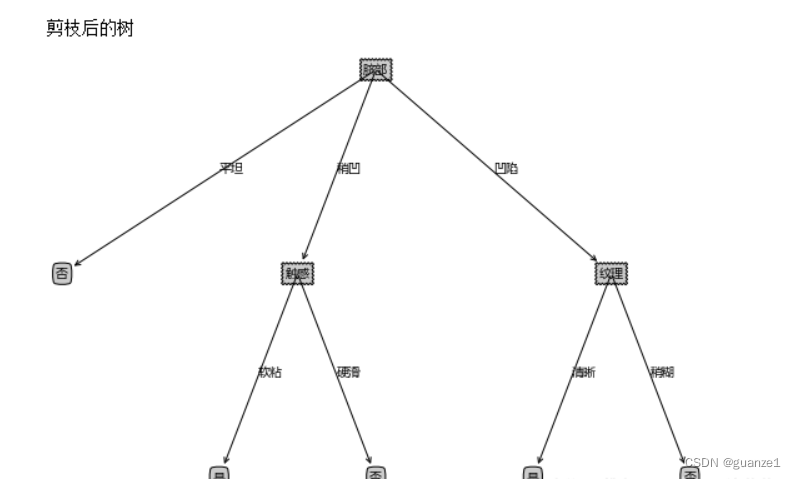
# 画剪枝后的树
print("剪枝后的树")
createPlot(myTreePrePruning)输出结果:
4、后剪枝及测试:
# 创建决策树 带预划分标签
def createTreeWithLabel(data, labels, names, method = 'id3'):data = np.asarray(data)labels = np.asarray(labels)names = np.asarray(names)votedLabel = voteLabel(labels)if len(set(labels)) == 1: return votedLabel elif data.size == 0: return votedLabelbestFeat, bestEnt = bestFeature(data, labels, method = method)bestFeatName = names[bestFeat]names = np.delete(names, [bestFeat])decisionTree = {bestFeatName: {"_vpdl": votedLabel}}dataSet, labelSet = splitFeatureData(data, labels, bestFeat)for featValue in dataSet.keys():decisionTree[bestFeatName][featValue] = createTreeWithLabel(dataSet.get(featValue), labelSet.get(featValue), names, method)return decisionTree def convertTree(labeledTree):labeledTreeNew = labeledTree.copy()nodeName = list(labeledTree.keys())[0]labeledTreeNew[nodeName] = labeledTree[nodeName].copy()for val in list(labeledTree[nodeName].keys()):if val == "_vpdl": labeledTreeNew[nodeName].pop(val)elif type(labeledTree[nodeName][val]) == dict:labeledTreeNew[nodeName][val] = convertTree(labeledTree[nodeName][val])return labeledTreeNew# 后剪枝 训练完成后决策节点进行替换评估
def treePostPruning(labeledTree, dataTest, labelTest, names):newTree = labeledTree.copy()dataTest = np.asarray(dataTest)labelTest = np.asarray(labelTest)names = np.asarray(names)featName = list(labeledTree.keys())[0]featCol = np.argwhere(names==featName)[0][0]names = np.delete(names, [featCol])newTree[featName] = labeledTree[featName].copy()featValueDict = newTree[featName]featPreLabel = featValueDict.pop("_vpdl")subTreeFlag = 0dataFlag = 1 if sum(dataTest.shape) > 0 else 0if dataFlag == 1:dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, featCol)for featValue in featValueDict.keys():if dataFlag == 1 and type(featValueDict[featValue]) == dict:subTreeFlag = 1 newTree[featName][featValue] = treePostPruning(featValueDict[featValue], dataTestSet.get(featValue), labelTestSet.get(featValue), names)if type(featValueDict[featValue]) != dict:subTreeFlag = 0 if dataFlag == 0 and type(featValueDict[featValue]) == dict: subTreeFlag = 1 newTree[featName][featValue] = convertTree(featValueDict[featValue])if subTreeFlag == 0:ratioPreDivision = equalNums(labelTest, featPreLabel) / labelTest.sizeequalNum = 0for val in labelTestSet.keys():equalNum += equalNums(labelTestSet[val], featValueDict[val])ratioAfterDivision = equalNum / labelTest.size if ratioAfterDivision < ratioPreDivision:newTree = featPreLabel return newTreemyTreeTrain1 = createTreeWithLabel(myDataTrain, myLabelTrain, myName, method = 'id3')
createPlot(myTreeTrain1)
print(myTreeTrain1)xgTreeBeforePostPruning = {"脐部": {"_vpdl": "是", '凹陷': {'色泽':{"_vpdl": "是", '青绿': '是', '乌黑': '是', '浅白': '否'}}, '稍凹': {'根蒂':{"_vpdl": "是", '稍蜷': {'色泽': {"_vpdl": "是", '青绿': '是', '乌黑': {'纹理': {"_vpdl": "是", '稍糊': '是', '清晰': '否', '模糊': '是'}}, '浅白': '是'}}, '蜷缩': '否', '硬挺': '是'}}, '平坦': '否'}}xgTreePostPruning = treePostPruning(xgTreeBeforePostPruning, xgDataTest, xgLabelTest, xgName)
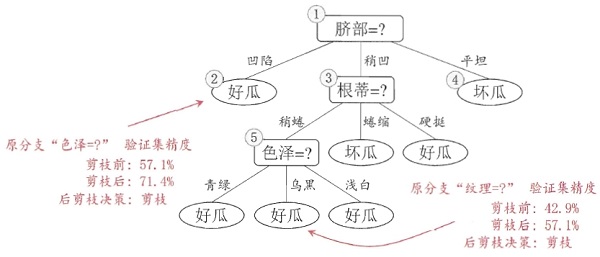
createPlot(convertTree(xgTreeBeforePostPruning))
createPlot(xgTreePostPruning)结果:
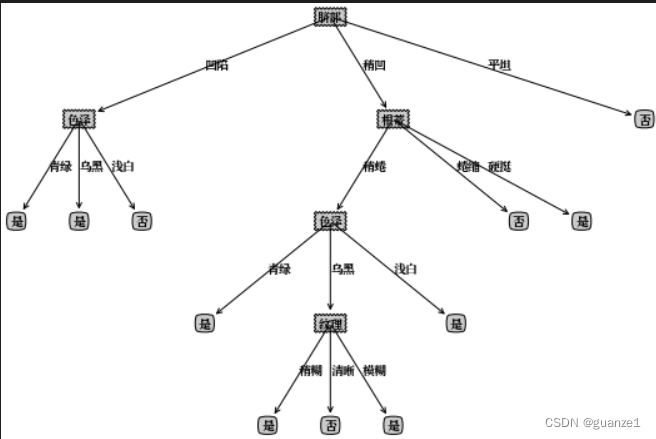

四、总结
对比预剪枝与后剪枝生成的决策树,可以看出,后剪枝通常比预剪枝保留更多的分支,其欠拟合风险很小,因此后剪枝的泛化性能往往由于预剪枝决策树。但后剪枝过程是从底往上裁剪,因此其训练时间开销比前剪枝要大。