剪枝参考视频
本文将介绍深度学习模型压缩方法中的剪枝,内容从剪枝简介、剪枝步骤、结构化剪枝与非结构化剪枝、静态剪枝与动态剪枝、硬剪枝与软剪枝等五个部分展开。
剪枝简介
在介绍剪枝之前,首先来过参数化这个概念,过参数化主要是指在训练阶段,在数学上需要进行大量的微分求解,去捕捉数据中微小的变化信息,一旦完成迭代式的训练之后,网络模型在推理的时候就不需要这么多参数。而剪枝算法正是基于过参数化的理论基础提出来的。剪枝算法的核心思想就是减少网络模型中参数量和计算量,同时尽量保证模型的性能不受影响。
剪枝步骤
对模型进行剪枝有三种常见的做法:
1、先训练一个模型 ,然后对模型进行剪枝,最后对剪枝后模型进行微调。这种方法是三种方法中用的最多的。
2、直接在模型训练过程中进行剪枝,最后对剪枝后模型进行微调。
3、直接进行剪枝,然后从头训练剪枝后的模型。
上述做法中提到的对模型进行剪枝具体步骤如下:
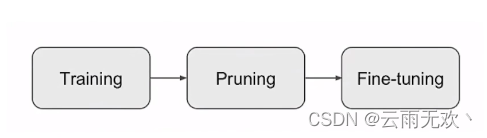
第一步训练: 是对网络模型进行训练。在剪枝流程中,训练部分主要指预训练,训练的目的是为剪枝算法做准备;
第二步剪枝: 在这里面可以进行如细粒度剪枝、向量剪枝、核剪枝、滤波器剪枝等各种不同的剪枝算法。其中很重要的一点,就是在剪枝之后,对网络模型进行评估,看是否符合要求。剪枝之前需要确定需要剪枝的层,设定一个裁剪阈值或者比例。在具体实现上,通过修改代码加入一个与参数矩阵尺寸一致的Mask矩阵。Mask矩阵中只有0和1,它的实际作用是微调网络;
第三步微调: 微调是一个的必要的步骤,它能恢复被剪枝操作影响的模型性能。结构化剪枝会对原始模型的结构进行调整,因此剪枝后的模型虽然保留了原始模型的参数,但是由于模型结构的改变,模型的表达能力会受到一定程度的影响。具体实现上,在计算的时候先乘以该Mask矩阵,Mask为1的参数值将继续训练,并通过反向传播调整梯度,而Mask为0的部分因为输出始终为0则不对后续部分产生影响。
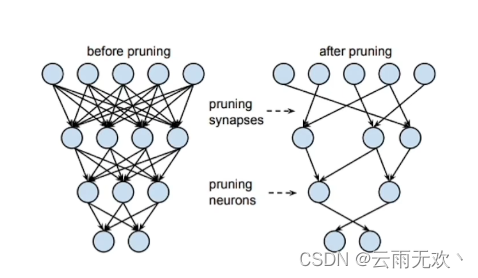
结构化剪枝与非结构化剪枝
如图所示,从左到右,剪枝的粒度是递增的,最左边的非结构化剪枝粒度最小,右边结构化剪枝中的层级、通道级、滤波器级剪枝粒度依次增大。
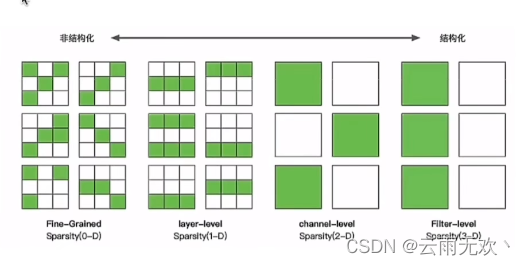
非结构化剪枝
非结构化剪枝主要是对一些独立的权重或者神经元进行剪枝,就是随机的剪,是粒度最小的剪枝。问题是如何确定要剪哪些东西呢?
最简单的方法是预定义一个阈值,低于这个阈值的权重被剪去,高于的被保留。但是有三个主要缺点:
1、阈值与稀疏性没有直接联系;
2、不同的层应该具有不同的灵敏度;
3、这样设置阈值可能会剪掉太多信息,无法恢复原来的精度。

结构化剪枝
图中右边这三个是结构化剪枝,结构化的剪枝是有规律、有顺序的。对神经网络,或者计算图进行剪枝,几个比较经典的就是对layer进行剪枝,对channel进行剪枝,对Filter进行剪枝,剪枝粒度依次增大。
在滤波器剪枝中,有一种方法是使用滤波器的Lp范数来评估每个滤波器的重要性(p为1则使用L1范数,p为2则使用L2范数)。通常,L范数较小的滤波器的卷积结果导致相对较低的激活值,因此对模型的最终预测具有较小的数值影响。根据这种理解,这种小Lp范数的滤波器将比那些大Lp范数滤波器更容易被剪掉。
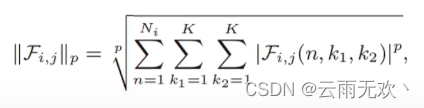
结构化剪枝的优点是:大部分算法保留原始卷积结构,不需要专用硬件就可以实现;缺点是:剪枝算法相对复杂。
静态剪枝与动态剪枝
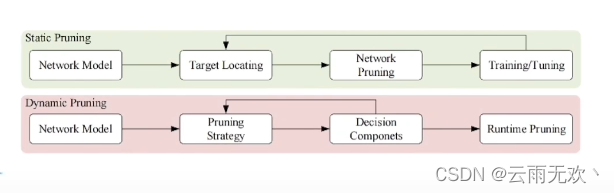
上图显示了静态剪枝和动态剪枝之间的差异。静态剪枝在推理之前离线执行所有剪枝步骤,而动态剪枝是在运行时执行。
静态剪枝
静态剪枝在训练后和推理前进行剪枝。在推理过程中,不需要对网络进行额外的剪枝。 静态剪枝通常包括三个部分:剪枝参数的选择;剪枝的方法;选择性微调或再训练;
再训练可以提高修剪后的网络的性能,以达到与未修剪时的网络相当的精度,但可能需要大量的计算时间和能耗。
静态剪枝存储成本低,适用于资源有限的边缘设备,但是也存在三个主要问题:
1、通道的删除是永久性的,对于一些较为复杂的输入数据,可能无法达到很好的精度,这是因为有些通道已经被永久剪掉了。
2、需要精心设计要剪的部分,不然容易造成计算资源的浪费。
3、神经元的重要性并不是静态的,而且神经元的重要性很大程度上依赖于输入数据,静态的剪枝很容易降低模型的推理性能。
动态剪枝
网络中有一些奇怪的权重,他们在某些迭代中作用不大,但在其他的迭代中却很重要。动态剪枝就是通过动态的恢复权重来得到更好的网络性能。动态剪枝在运行时才决定哪些层、通道或滤波器不会参与进一步的活动。动态剪枝可以通过改变输入数据来克服静态剪枝的限制,从而潜在地减少计算量、带宽和功耗。而且动态剪枝通常不会执行微调或重新训练。
与静态剪枝相比,动态剪枝能够显着提高卷积神经网络的表示能力,从而在预测精度方面取得更好的性能。同样,动态剪枝也存在一些问题:
1、之前有方法通过强化学习来实现动态剪枝,但在训练过程中要消耗非常多的运算资源。
2、很多动态剪枝的方法都是通过强化学习的方式来实现的,但是”阀门的开关“,是不可微的,也就是说,梯度下降法在这里是用不了的。
3、存储成本高,不适用于资源有限的边缘设备。
硬剪枝与软剪枝
硬剪枝与软剪枝都是对Filter进行剪枝,是结构化剪枝中粒度最大的剪枝。
硬剪枝
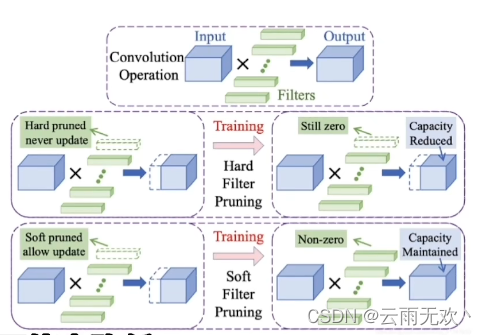
硬剪枝在每一轮后,会将卷积核直接剪掉,被剪掉的卷积核在下一轮中不会再出现。这类的剪枝算法通常从模型本身的参数出发,寻找或者设计出合适的统计量来表明连接的重要性。通过对重要性的排序等算法,永久删除部分不重要的连接,保留下来的模型即为剪枝模型。但是也存在一些问题:
1、模型性能可能会降低;
2、依赖预先训练的模型。
软剪枝
相比较于硬剪枝,软剪枝在进行训练时,上一轮中被剪掉的卷积核在本轮训练时仍参与迭代,只是将其参数置为0,因此那些卷积核不会被直接丢弃。
在每轮训练中,根据不同的数据对完整模型进行优化和训练。在每轮之后,为每个加权层计算所有滤波器的L2范数,并将其作为滤波器选择的标准。然后,通过将相应的滤波器权重设置为零来修剪所选择的滤波器,随后是下一轮训练。最后,原始的深度神经网络模型被修剪成一个紧凑而有效的模型。
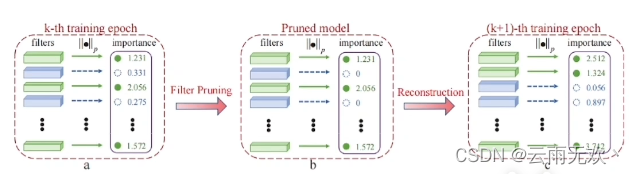
软剪枝一般有四个步骤:
1、滤波器选择: 使用L2范数来评估每个滤波器的重要性。具有较小L2范数的滤波器的卷积结果会导致相对较低的激活值,从而对网络模型的最终的预测结果有较小的影响。所以这种具有较小L2范数的滤波器将更容易被剪掉。
2、滤波器剪枝: 将所选滤波器的值设置为零。这可以暂时消除它们对网络输出的影响。然而,在接下来的训练阶段,这些滤波器仍然可以被更新,以保持模型的高性能。在滤波器剪枝步骤中,可以同时修剪所有加权层。此外,要对所有加权层使用相同的剪枝率。
3、重建: 在剪枝步骤之后,再训练一个轮来重构修剪后的滤波器。修剪滤波器通过反向传播被更新为非零。这样,经过软剪枝的模型可以具有与原始模型相当的性能。
4、获得紧凑模型: 重复以上3个步骤。当模型收敛后,我们可以得到一个包含许多“零滤波器”的稀疏模型。一个“零过滤器”对应于一个特征图。对应于那些“零过滤器”的特征图在推理过程中将总是零。移除这些过滤器以及相应的特征图不会有任何影响。




![[算法] 栈和队列](https://img-blog.csdnimg.cn/ce7df0be33f0470fb7d74a4b449cb342.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6KW_56eR6IOh5YWI55Sf,size_20,color_FFFFFF,t_70,g_se,x_16)